Hamiltonian Monte Carlo
The physics of Hamiltonian Monte Carlo, part 3: In the final post in this series, I discuss Hamiltonian Monte Carlo, building off previous discussions of the Euler–Lagrange equation and Hamiltonian dynamics.
In the previous two posts in this series, we built up enough background material in physics to re-derive Hamilton’s equations. We now ready for Hamiltonian Monte Carlo (HMC) (Duane et al., 1987), a Markov chain Monte Carlo (MCMC) algorithm that improves on a random walk using Hamiltonian dynamics. Now that we understand Hamiltonian dynamics, understanding HMC is relatively easy.
I assume the reader is familiar with the material and notation in the previous two posts, and is at least familiar with the Metropolis–Hastings (MH) algorithm. I’ll review MH next, but if any details do not make sense, see my MH post.
Correlated Metropolis steps
In Bayesian inference, we often want to sample from a posterior density where are our model parameters and is our data. The Metropolis–Hastings algorithm (Metropolis et al., 1953; Hastings, 1970) walks an implicit Markov chain whose stationary distribution is , meaning that once the Markov chain has mixed, each state is a sample from the posterior.
Metropolis–Hastings works because, given a transition kernel that computes a transition probability , any Markov process will converge to a unique stationary distribution provided it is ergodic and satisfies the detailed balance,
Ensuring the Markov process is ergodic is straightforward: we can avoid periodicity by ensuring the probability of staying on any state is nonzero, and we can ensure a single recurrent class by picking a proposal distribution such that there is a nonzero probability of jumping to any point in parameter space. However, ensuring the detailed balance in requires an acceptance criteria. Let be some function for proposing candidate jumps in the Markov process. If we accept its proposals with probability where,
then we ensure the detailed balance holds for . In Bayesian inference, we set , and we sample from our posterior by walking the Markov chain until it mixes. If the transition kernel is symmeteric, meaning , then Metropolis–Hastings reduces to the Metropolis algorithm with acceptance criteria,
A challenge with both the Metropolis–Hastings and Metropolis algorithms is that the proposed state is correlated with the current state . For example, in a simple Gaussian random walk, the proposal is just the previous state with additive Gaussian noise. Increasing the MH step size does not necessarily help, because bigger proposed jumps in parameter space may result to a higher rejection rate in or . This becomes even more problematic if is high-dimensional. While we have asymptotic guarantees, we often can’t rely on them in practice, i.e. MH can be very, very slow to converge.
Hamiltonian Monte Carlo
HMC leverages Hamiltonian dynamics to propose a new state that is both uncorrelated with the previous state and has a high probability of being accepted. Imagine that our parameters are the generalized coordinates, a -dimensional position vector, in a fictitious physical system, and let’s introduce auxiliary generalized momenta . By fiat, let’s say that the Hamiltonian of our fictitious physical system is equal to the log joint distribution on :
Here, we have defined kinetic energy as and potential energy as . The second equality holds because we assume is independent of .
Now consider the following MCMC algorithm. On each sampling step, randomly resample the momentum variables from a spherical Gaussian distribution,
and then update both and by simulating Hamiltonian dynamics using Hamilton’s equations:
This would give us a new position vector that is uncorrelated from the previous step . If the transition probabilities are symmetric and if Hamiltonian dynamics are volume-preserving—I’ll explain these qualifications later—, then we can accept this new proposal using the Metropolis criteria in :
If we could simulate Hamiltonian dynamics exactly, the Hamiltonian would always be conserved exactly, and would always be . As we will see, the main complication in implementing HMC is that we cannot simulate Hamiltonian dynamics exactly. Instead, we will use the leapfrog integrator, which approximates simulating the dynamics. However, if this approximation is good, then should be small, and our acceptance rate will be high.
Note that above, we’ve only shown that is the stationary distribution of our Markov process. However, at least intuitively, the probability of transitioning from to also satisfies the detailed balance because we resample from a distribution that is independent of . In fact, this intuition is correct, meaning we are also sampling from the stationary distribution . See Duane’s original paper for a proof.
HMC is a very clever idea. If our approximation of Hamiltonian dynamics is good, then we can make possibly large, uncorrelated jumps in parameter space while having a high probability of acceptance because the difference in is often small.
Now that we understand the big picture, we need to discuss three details: Are the transition probabilites symmetric? Are Hamiltonian dynamics volume-preserving? How can we simulate Hamiltonian dynamics? Let’s take a look at each of these points separately.
Time reversal symmetry
The correctness HMC depends on the proposal distribution being symmetric. To understand why this symmetry holds, we need to understand that Hamilton’s equations are invariant under a reversal in the direction of time, where . Or Hamilton’s equations are reversible. While the position vector does not depend on time, momenta does through velocity, and is therefore also reversed:
Above, and are the mass and velocity associated with the -th parameter. Plugging and into , we get:
In other words, the forms of the equations don’t change from . The physical interpretation is that if we allow a physical system to evolve up to time , then flip the sign of each particle’s velocity, and then allow the system to evolve again for another time interval , the system would return to its original state. Put differently, if we observe a system evolve through time—a bird flying from ground to branch—it is impossible to know a priori if we are observing the forward- or backward-in-time evolution because the system has time reversal symmetry. In physics, this leads to concepts such as Loschmidt’s paradox and the arrow of time.
HMC ensures the proposal distribution is symmetric with this trick: after each sampling step, flip the sign of the momenta variable, so on iteration . On half of the steps, we move forward in time; and on the other half, we move backwards in time. That said, this is not needed in practice if we sample the momenta from a symmetric distribution such as because positive or negative mometum components (each ) are equally likely.
There is one caveat to this discussion. We aren’t simulating Hamiltonian dynamics exactly, and therefore the leapfrog integrator mentioned previously must also be symmetric. We’ll see that it is.
Volume preservation
A second important property of Hamilton’s equations is that they are volume-preserving transformations. Why does this matter? To be frank, I haven’t seen a single resource that explains this point well, although (Neal, 2011) implies the answer when he writes:
If we proposed new states using some arbitrary, non-Hamiltonian, dynamics, we would need to compute the determinant of the Jacobian matrix for the mapping the dynamics defines, which might well be infeasible.
Let me explain what he means in more detail.
At each sampling step, we’re applying a deterministic transformation to the parameters and momenta. Let’s call this transformation . How do we know we’re still sampling from the desired joint distribution after applying this transformation? In probability, there is a simple solution: apply a change of variables:
Let be a -dimensional random variable with a joint density . If where is an invertible, differentiable function, then has density :
Here, the term is the Jacobian of the inverse of the transformation . In our case, this means that the Metropolis acceptance ratio in can be written more explicitly as
The reason no one writes this out in HMC is because the invertible and differentiable transformation is Hamiltonian dynamics, and the determinant of a volume-preserving transformation is one. For a geometric intuition of the determinant, see my previous post on determinantal point processes. So volume preservation means we do not have to write the Metropolis acceptance ratio as in and can instead write it as in .
I haven’t seen a simple, standalone proof of the fact that Hamiltonian dynamics are volume-preserving, and I suspect this is why Neal just proves directly that the determinant of the transformation is one, a sufficient claim for our purposes and one that requires less knowledge about statistical mechanics. I won’t include his proof here because I don’t think it adds to our intuition at this point.
Once again, we have a caveat. Since we aren’t simulating Hamiltonian dynamics exactly, the leapfrog integrator mentioned previously must also be volume-preserving. Again, we’ll see that it is.
Leapfrog integration
Our remaining question is: how can we simulate Hamiltonian dynamics? This is an important problem in physics, and there are many algorithms for doing so. For example, here is a textbook on the topic and here is a recent paper. The class of methods for providing numerical solutions to Hamilton’s equations are symplectic integrators, where symplectic refers to a type of manifold. Without getting sidetracked, the main idea is that the generalized momenta and position live on a symplectic manifold, and symplectic integrators are integrators whose solutions are on symplectic manifolds. Because these integrators assume the right structure for the problem, they are better at long-term integration because they do not accumulate systematic error. You can find many examples of this systematic error for simpler integrators, for example in this blog post by Colin Carroll, this StackExchange post, and of course (Neal, 2011).
Symplectic integration is a complex topic, and the main point is just that the leapfrog integrator is a specific instance of a general set of solutions that is particularly convenient for HMC. In the original paper, Duane lists three reasons for choosing the leapfrog integrator:
- It is simple.
- It ensures exact reversibility.
- It preserves volume.
The first reason is just nice-to-have. The second point ensures the correctness of HMC, and the third point makes our calculations tractable, since we can ignore the Jacobian of our transformation.
The method is called the leapfrog integrator or the leapfrog method because it discretizes time using a small stepsize , computing a half-step update of momenta, a full-step update of position using the new momenta, and finally another half-step update in momenta using the new position:
We can imagine the momenta and position estimates leapfrog jumping over each other. Note that is just the gradient of the log likelihood, which we can compute using automatic differentation. This is why HMC is sometimes referred to as a gradient-based MCMC method.
Since we’re arbitrarily discretizing time into step sizes , we can run the leapfrog updates in as many times as we’d like to simulate a Metroplis jump using Hamiltonian dynamics. Both the number of steps and the step size are hyperparameters, and tuning these hyperparameters is part of what makes HMC difficult in practice. See (Neal, 2011) for a detailed discussion of tuning HMC.
Example: Rosenbrock density
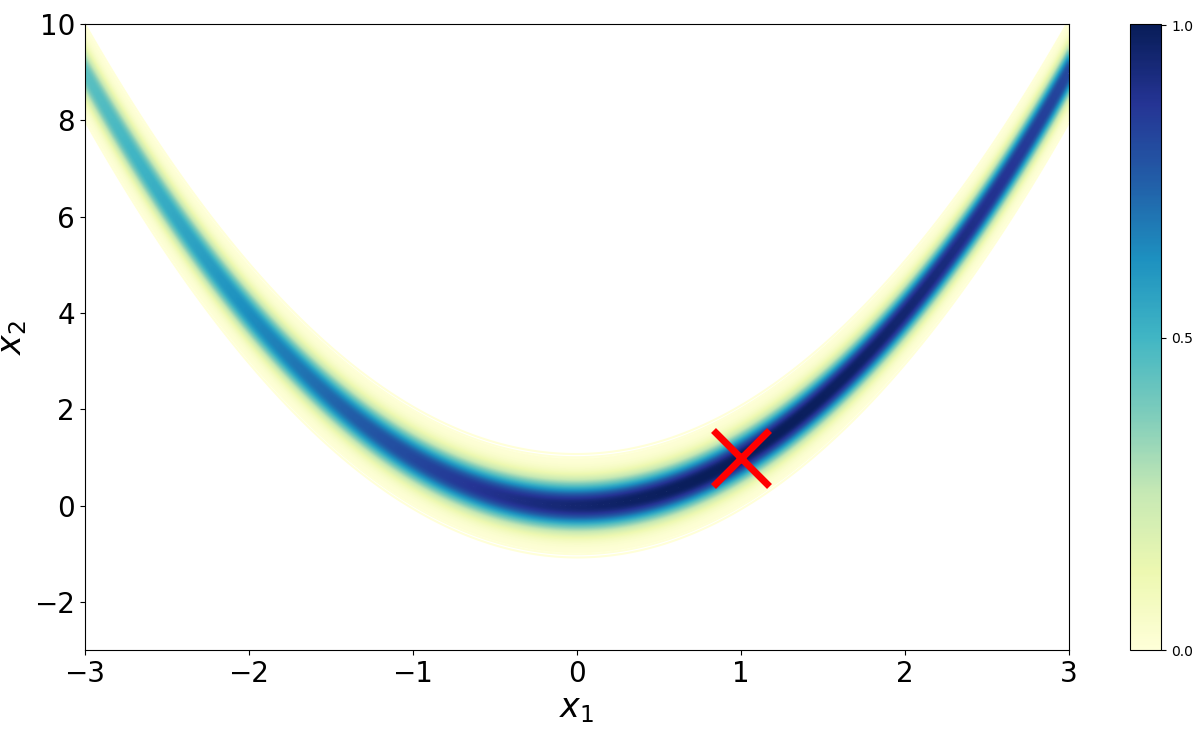
Imagine we want to sample from the Rosenbrock density (Figure ),
The Rosenbrock function (Rosenbrock, 1960) is a well-known test function in optimization because while finding a minimum is relatively easy, finding the global minimum at (, ) is less trivial. (Goodman & Weare, 2010) adapted the function to serve as a benchmark for MCMC algorithms. I’ve also used this density to benchmark my implementation of Metroplis-Hastings
Below is my implementation of Hamiltonian Monte Carlo run on the Rosenbrock density. I’ve used the autograd library to automatically differentiate the log density provided by the user. We can accept a proposed sample with probability by drawing a uniform random variable with support and then checking if it is less than the acceptance criteria.
from autograd import grad
import matplotlib.pyplot as plt
import numpy as np
from scipy.stats import norm
def hmc(logp, n_samples, x0, n_steps, step_size):
"""Run Hamiltonian Monte Carlo to draw `n_samples` from the log density
`logp`, starting at initial state `x0`.
"""
momenta_dist = norm(0, 1)
# Kinetic and potential energy functions.
T = lambda r: -momenta_dist.logpdf(r).sum()
V = lambda x: -logp(x)
grad_V = grad(V)
dim = len(x0)
samples = np.empty((n_samples, dim))
samples[0] = x0
for i in range(1, n_samples):
x_curr = samples[i-1]
r_curr = momenta_dist.rvs(size=dim)
x_prop, r_prop = leapfrog(x_curr, r_curr, n_steps, step_size, grad_V)
H_prop = T(r_prop) + V(x_prop)
H_curr = T(r_curr) + V(x_curr)
alpha = np.exp(-H_prop + H_curr)
if np.random.uniform(0, 1) < alpha:
x_curr = x_prop
samples[i] = x_curr
return samples
def leapfrog(x, r, n_steps, step_size, grad_V):
"""Run the leapfrog integrator forward `n_steps` using step size
`step_size`.
"""
x, r = x[:], r[:]
for _ in range(n_steps):
r = r - (step_size / 2) * grad_V(x)
x = x + step_size * r
r = r - (step_size / 2) * grad_V(x)
return x, r
def log_rosen(x):
"""Compute the log of the Rosenbrock density.
"""
return -((1 - x[0]) ** 2 + 100 * (x[1] - x[0] ** 2) ** 2) / 20
samples = hmc(
logp=log_rosen,
n_samples=1000,
x0=np.random.uniform(low=[-3, -3], high=[3, 10], size=2),
n_steps=20,
step_size=0.03
)
plt.plot(samples[:, 0], samples[:, 1])
plt.show()
That’s it. Despite its conceptual depth, Hamiltonian Monte Carlo is, like Metropolis–Hastings, surprisingly simple to implement. This code could easily be amended to support burn in, multiple chains, and so forth, but it is the minimal code required to understand the algorithm.
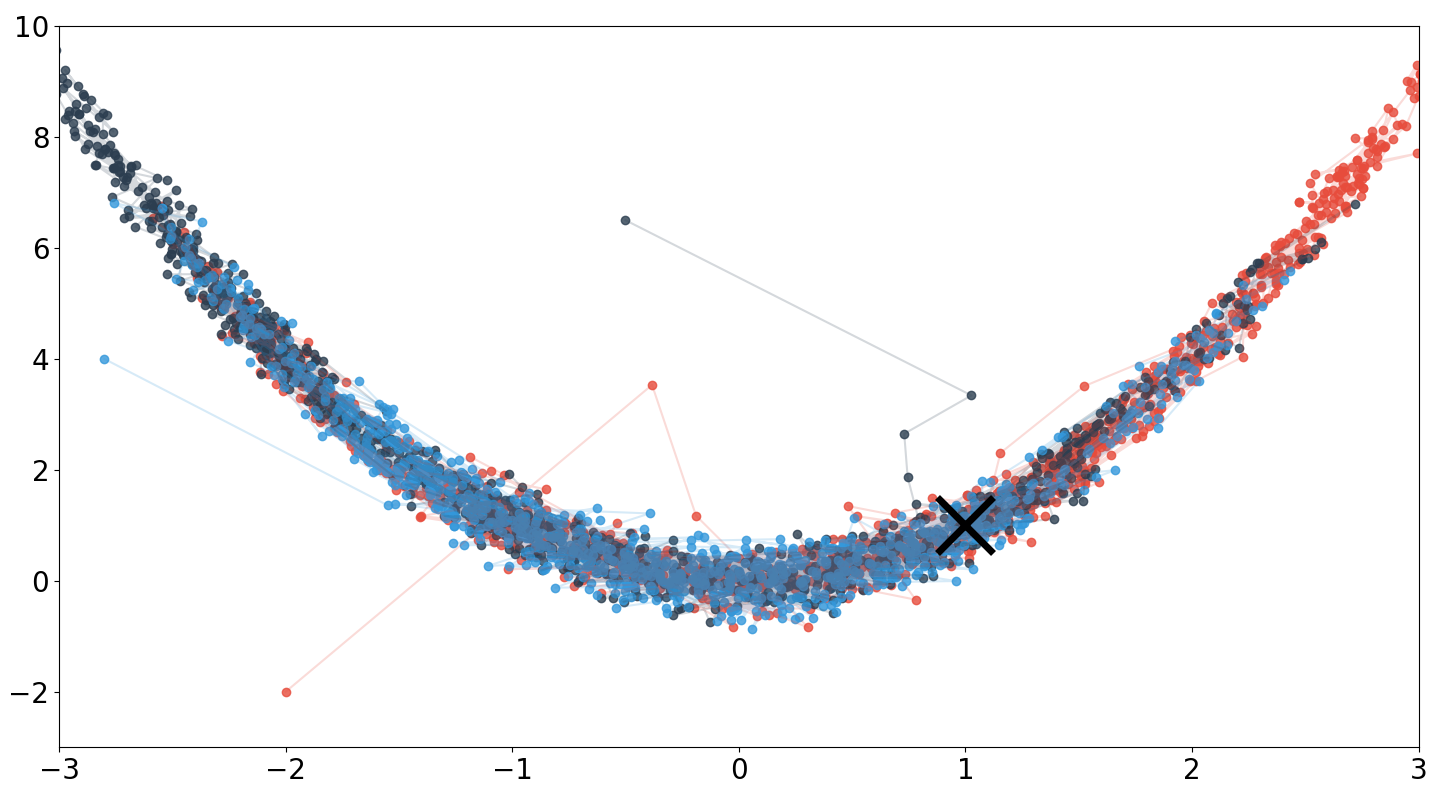
The above code is the basis for Figure , which runs three Markov chains from randomly initialized starting points. A few points are worth mentioning when comparing this result to my MH result. First, notice that HMC jumps to the high probability areas much faster than MH. This is probably because HMC leverages the gradient of the log density. Second, notice that HMC explores the Rosenbrock density more thoroughly given the same number of iterations (). Finally, HMC accepted nearly all of the proposals () because the leapfrog integrator could well-approximate the dynamics for this simple problem.
Conclusion
Hamiltonian Monte Carlo, like Metropolis–Hastings, is a beautifully simple algorithm given a basic understanding of MCMC and Hamiltonian dynamics. Rather than performing a random walk, HMC introduces auxiliary momenta variables that allow us to simulate a fictitious physical system using Hamiltonian dynamics. This simulation creates MCMC jumps with less correlation between states, and if the approximated dynamics are good, can result in a very high acceptance rate.
- Duane, S., Kennedy, A. D., Pendleton, B. J., & Roweth, D. (1987). Hybrid monte carlo. Physics Letters B, 195(2), 216–222.
- Metropolis, N., Rosenbluth, A. W., Rosenbluth, M. N., Teller, A. H., & Teller, E. (1953). Equation of state calculations by fast computing machines. The Journal of Chemical Physics, 21(6), 1087–1092.
- Hastings, W. K. (1970). Monte Carlo sampling methods using Markov chains and their applications.
- Neal, R. M. (2011). MCMC using Hamiltonian dynamics.
- Rosenbrock, H. H. (1960). An automatic method for finding the greatest or least value of a function. The Computer Journal, 3(3), 175–184.
- Goodman, J., & Weare, J. (2010). Ensemble samplers with affine invariance. Communications in Applied Mathematics and Computational Science, 5(1), 65–80.