Modeling Repulsion with Determinantal Point Processes
Determinantal point process are point processes characterized by the determinant of a positive semi-definite matrix, but what this means is not necessarily obvious. I explain how such a process can model repulsive systems.
A point process over a set is a probability measure over a random subset of . For example, in a Bernoulli point process with parameter , each event is independent and occurs with probability . A determinantal point process (DPP) is a point process which is characterized by the determinant of a positive semi-definite matrix or kernel. The consequence of this is that DPPs are good for modeling repulsion, but why this follows from their definition may not be obvious. I want to explain my understanding of how they how they can be used as probabilistic models of repulsion. For simplicity, I only consider discrete sets.
It’s worth mentioning that while many point processes are determinantal, it is not well-understood why they are common (Tao, 2009), and they have recently received renewed attention in the mathematics and machine learning communities (Kulesza et al., 2012).
Determinantal point processes
A determinantal point process is a point process such that for every random subset drawn according to , we have for every subset :
where is a positive semi-definite (real, symmetric) matrix, called a kernel, indexed by the elements in and,
which means that the elements of are indexed by the indices of . (We haven’t specified the actual values in .) There is a lot of notation to unpack here. First, both and are subsets . But we say that is a random subset sampled according to . Thus, we call a realization of our point process, meaning it was sampled according to the distribution of , while is just any subset of . And for to be a determinantal point process, a property of that realization must be that for every possible subset of points , the probability of that set being in is equal to the determinant of some real, symmetric matrix. If you’re like me, what this means is not obvious, but it becomes more clear once we work through the math.
Let’s start with the simplest case. What happens when . Then we have:
In words, the diagonal of the matrix represents the marginal probability that is included in any realization of our determinantal point process . For example, if is close to , that means that any realization from the DPP will almost certainly include . Now let’s look at a two element set, :
where we can say because is symmetric. So the off-diagonal elements loosely represent negative correlation in the sense that the larger the value of , the less likely the joint probability of .
If you’re like me, this above example from (Kulesza et al., 2012) is useful for two dimensions, but I find it hard to reason about how the probabilities change with higher-dimensional kernels. For example, this is the probability for three elements (dropping the set notation for legibility):
This is harder to reason about. I might note that if all the values are fixed and increases, then increases faster than , and therefore the probability decreases. But I find this kind of thinking about interactions slippery. I think an easier way to understand the determinantal point process is to use a geometrical understanding of the determinant while remembering that is symmetric.
Geometry of the determinant
Consider the geometrical intuition for the determinant of an matrix: it is the signed scale factor representing how much a matrix transforms the volume of an -cube into an -dimensional parallelepiped. If that statement did not make sense, please read my previous post on a geometrical understanding of matrices. With this idea in mind, let’s consider the determinant for a simple matrix :
If we think of as a geometric transformation, then the columns of indicate where the standard basis vectors in land in the transformed space. We can visualize this transformation by imagining how a unit square is transformed by (Figure ).
In this case, the determinant of is still because the area of the parallelogram (Figure ) is the same as the area of the unit square (Figure ). But what happens if were symmetric (Figure )? Recall that symmetry is a property of DPP kernels.
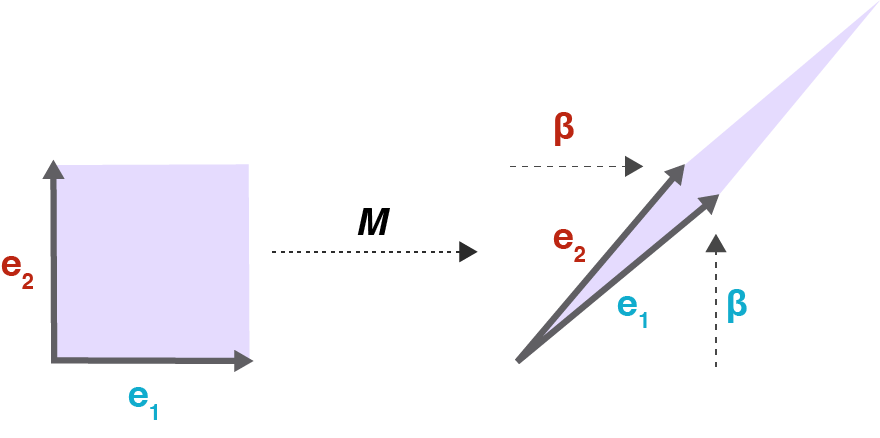
In this case, the off-diagonal elements of shear the matrix in two dimensions. The larger the value of , provided , the smaller the determinant of . If , then is no longer positive semi-definite because the determinant is either or negative.
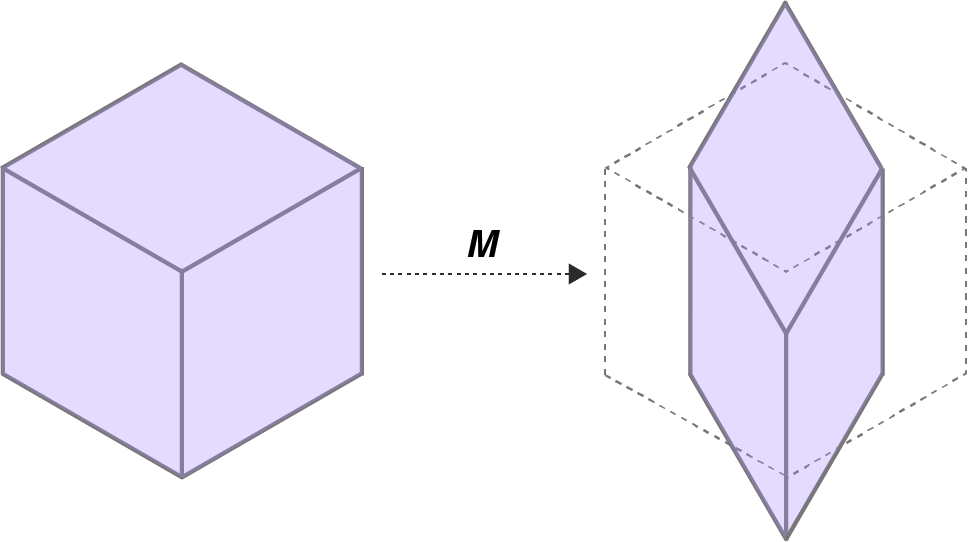
I like this geometrical intuition for the kernels of DPPs because it generalizes better in my mind. I find generalizing Equation difficult, but I can imagine a determinant of a kernel matrix in three dimensions. As the off-diagonal elements of this kernel matrix increase, the unit cube in 3D space is sheared more and more, just like in the 2D case. For example, consider again the probability of three elements from a DPP, . What if was high? Then the matrix transformation represented by would be sheared along the -plane (Figure ). Since the probability of the triplet is proportional to the determinant of this matrix, the probability of the triplet decreases.
Gram matrices
There’s another way to think of the geometry of the determinant in relation to a DPP. Consider a realization of , . We can construct a positive semi-definite matrix in the following way:
In this case, the determinant of is equal to the squared volume of the parallelepiped spanned by the vectors in . To see this, recall two facts. First, recall that for any matrix . And second, note that in general, the absolute value of the determinant of real vectors is equal to the volume of the parallelepiped spanned by those vectors. Then we can write:
This is a useful way to think about DPPs because it means that if we construct our kernel in the manner above, we have a very nice intuition for our model: if is a realization from our point process over , then as the points in move farther apart, the probability of sampling increases. This is because now is just a Gram matrix, i.e.:
and if two elements and have a larger inner product, then the probability of them co-occuring in a realization of our point process decreases. For real matrices, this inner product just the dot product, which has a simple, geometrical intuition.
Conclusion
DPPs are an interesting way to model repulsive systems. In probabilistic machine learning, they have been used as a prior for latent variable models (Zou & Adams, 2012)—think of a DPP with over a Gram matrix of latent variable parameters—, and in optimization, they have been used for diversifying mini-batches (Zhang et al., 2017), which may lead to stochastic gradients with lower variance, especially in contexts such as imbalanced data.
- Tao, T. (2009). Determinantal processes. https://terrytao.wordpress.com/2009/08/23/determinantal-processes/
- Kulesza, A., Taskar, B., & others. (2012). Determinantal point processes for machine learning. Foundations and Trends® in Machine Learning, 5(2–3), 123–286.
- Zou, J. Y., & Adams, R. P. (2012). Priors for diversity in generative latent variable models. Advances in Neural Information Processing Systems, 2996–3004.
- Zhang, C., Kjellstrom, H., & Mandt, S. (2017). Determinantal point processes for mini-batch diversification. ArXiv Preprint ArXiv:1705.00607.