A Geometrical Understanding of Matrices
My college course on linear algebra focused on systems of linear equations. I present a geometrical understanding of matrices as linear transformations, which has helped me visualize and relate concepts from the field.
Beyond systems of equations
I took linear algebra in college, but the main thing I remember from the course was solving systems of linear equations by converting matrices to row echelon form. I did well in the class, but I had little intuition for matrices as geometric objects and almost none of the material stuck. In graduate school, I have discovered that having such a geometrical intuition for matrices—and for linear algebra more broadly—makes many concepts easier to understand, chunk, and remember.
For example, computing the determinant of a matrix is tedious. But if we think of the determinant of a matrix as the signed scale factor representing how much a matrix transforms the volume of an -cube into an -dimensional parallelepiped, it is straightforward to see why a matrix with a determinant of is singular. It is because the matrix is collapsing space along at least one dimension.
The goal of this post is to lay the ground work for understanding matrices as geometric objects. I focus on matrices because they effect how I think of vectors, vector spaces, the determinant, null spaces, spans, ranks, inverse matrices, singular values, and so on. In my mind, every one of these concepts is easier to understand with a strong, geometrical understanding of matrices. For simplicity, I will focus on real-valued matrices and vectors, and I error on the side of intuitive examples rather than generalizations.
Matrices as linear transformations
In linear algebra, we are interested in equations of the following form:
Where , , and . One way to think about this equation is that represents a system of linear equations, each with variables, and represents a solution to this system. But there is another way to think of the matrix , which is as a linear function from to :
In my mind, the easiest way to see how matrices are linear transformations is to observe that the columns of a matrix represent where the standard basis vectors in map to in . Let’s look at an example. Recall that the standard basis vectors in are:
By definition, this means that every vector in is a linear combination of this set of basis vectors:
Now let’s see what happens when we matrix multiply one of these standard basis vectors, say , by a transformation matrix :
In words, the second column of tells us where the second basis vector in maps to in . If we horizontally stack the standard basis vectors into a matrix, we can see where each basis vector maps to in with a single matrix multiplication:
Now here’s the cool thing. We can express any transformed -vector as a linear combination of , , and , where the coefficients are the components of the untransformed -vector. For example, if , then:
It’s worth staring at these equations for a few minutes. In my mind, seeing Equations and together helped me understand why matrix multiplication is defined as it is. When we perform matrix multiplication, we are projecting a vector or vectors into a new space defined by the columns of the transformation matrix. And is just a linear combination of the columns of , where the coefficients are the components of .
In my mind, changing how we see the equation is not trivial. In the textbook Numerical Linear Algebra (Trefethen & Bau III, 1997), the authors claim that seeing matrices this way is “essential for a proper understanding of the algorithms of numerical linear algebra.”
This linearity is what allows us to say concretely that any linear transformation, , can be represented as a linear combination of the transformed basis vectors of , which can be encoded as a matrix-vector multiplication:
See the Appendix for a proof of the linearity of matrix transformations.
Visualizing matrix transformations
The linearity of matrix transformations can be visualized beautifully. For ease of visualization, let’s only consider matrices, which represent linear transformations from to . For example, consider the following matrix transformation of a vector :
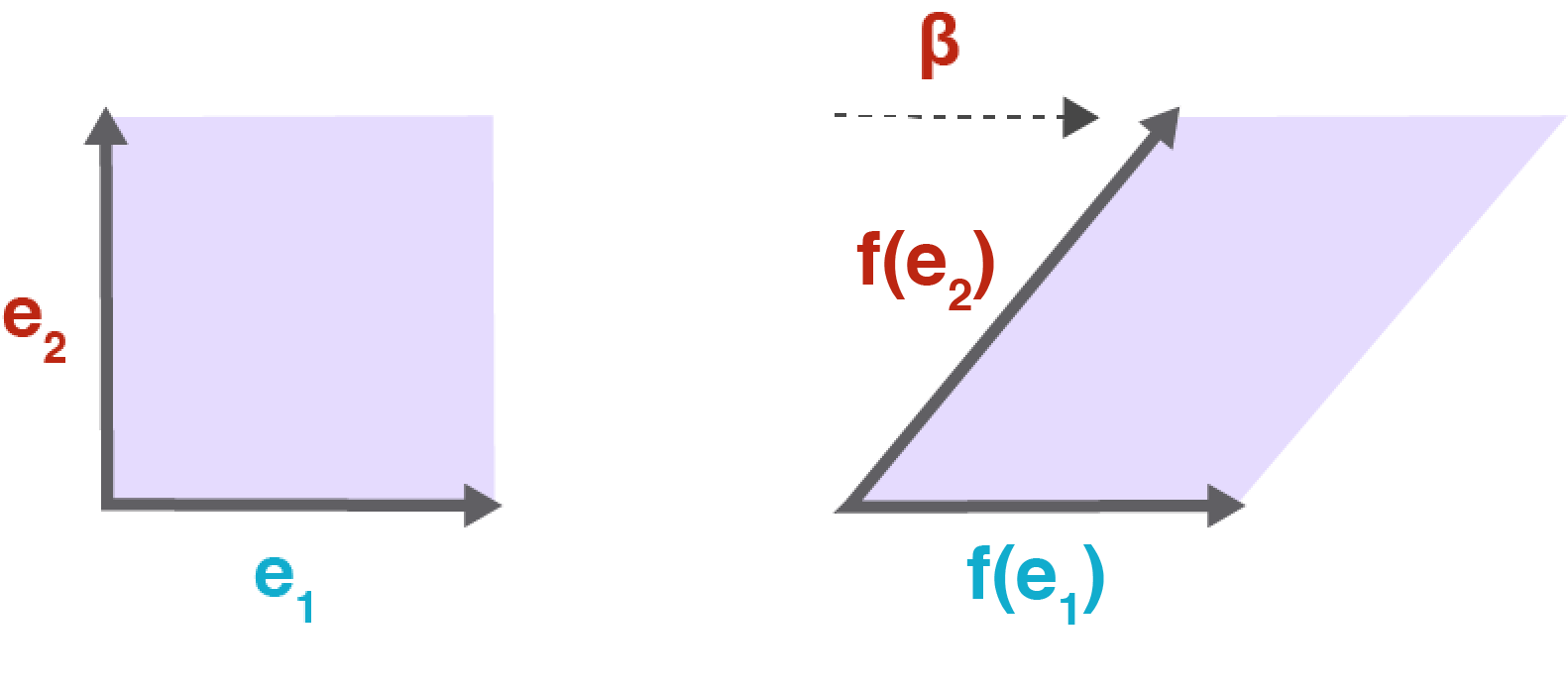
We can visualize two important properties of this operation (Figure ). First, the columns of represent where the standard basis vectors in land in this transformed vector space.
Second, in the new vector space, the vector is a linear combination of these transformed vectors. This is particularly useful to visualize by coloring unit squares and seeing how they are transformed. You can imagine that not just a vector is transformed by a matrix but that all of is transformed an matrix. Note that the determinant of the matrix is also visualized here. It is .
Types of linear transformations
Now that we have some intuition for how matrix transformations represent linear functions, we might want to ask: what kind of transformations can we perform with matrices? A consequence of the linearity of matrix transformations is that we can only modify a vector space in particular ways such as by rotating, reflecting, scaling, shearing, and projecting. Intuitively, the hallmark of a linear transformation is that evenly spaced points before the transformation are evenly spaced after the transformation (Figure ).
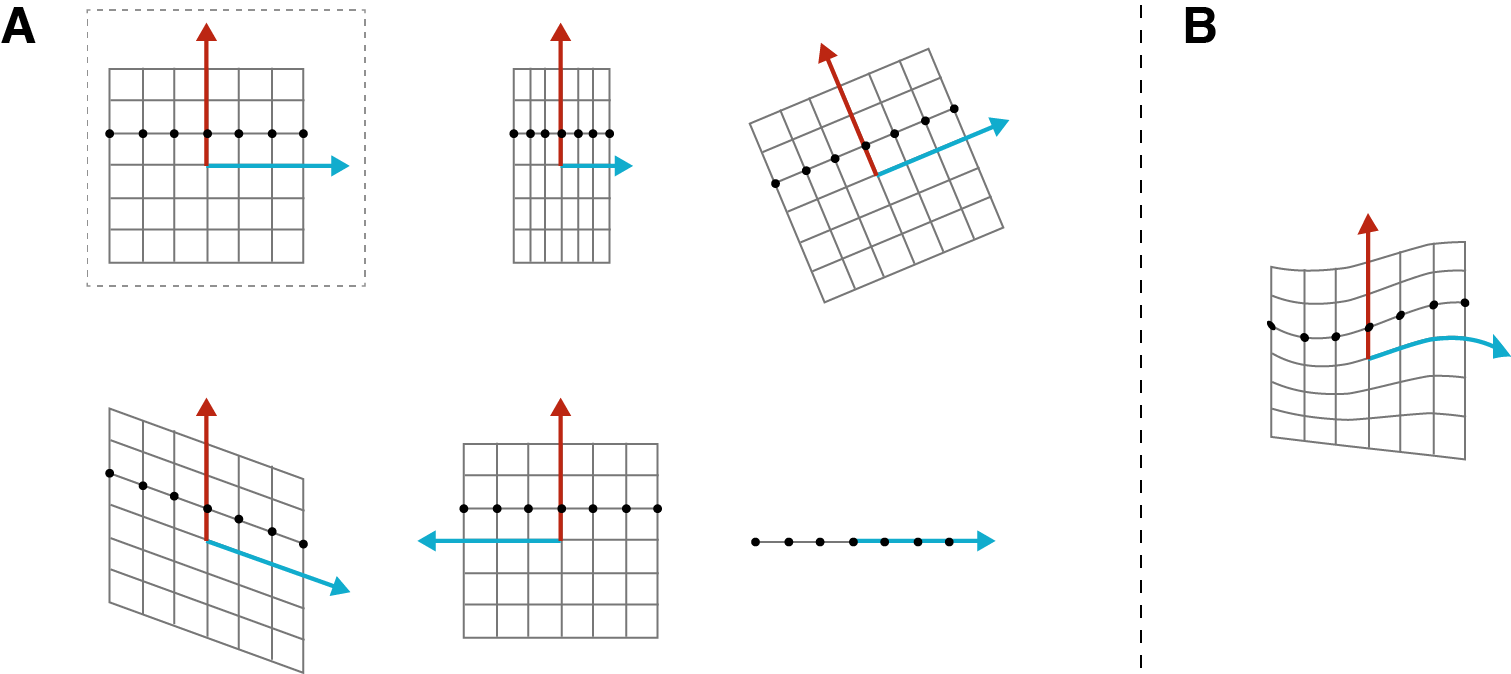
This makes sense. Linear functions are polynomials of degree one or less, meaning variables change at fixed rates. Conversely, what we cannot represent with a linear transformation is anything that would deform the space in such a way that evenly spaced points in are unevenly spaced in (Figure ).
Now let’s look at some specific types of matrix transformations. To keep things simple, we’ll only consider square matrices. This is by no means an exhaustive or formal look at every type of matrix. The idea is to see how our geometrical understanding so far relates to familiar types of matrices.
Diagonal matrices
In my opinion, a diagonal matrix is the easiest matrix to understand once you understand that the columns of a matrix represent where the standard basis vectors map to in a new vector space defined by . For example, consider an arbitrary diagonal matrix with scalar values along its diagonal. If we think of the columns of the matrix as defining a new vector subspace, it is clear that each component in a transformed vector is only modified by one value on the diagonal:
This means a diagonal matrix is constrained in how it can modify a set of vectors (Figure ). For example, it can stretch the -th component of a vector with , or it can reflect the -th component with . You cannot shear a vector subspace with a diagonal matrix.
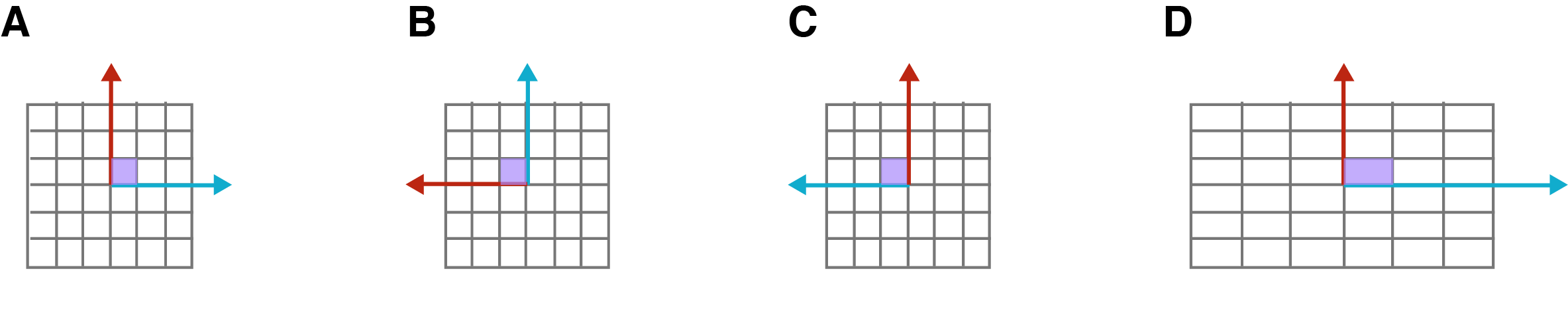
Note that the identity matrix is a diagonal matrix where , meaning the standard basis vectors are not changed. It has a determinant of because it does not modify a vector subspace.
Shear matrices
A shear matrix is so-named because you can imagine the unit square shearing. We can achieve shear with an off-diagonal element:
Without the off-diagonal element , this transformation would just stretch by . The off-diagonal element means that a transformed vector’s -st component is a linear combination of and . This results in a unit square that is sheared because one dimension is now a function of two dimensions (Figure ).
The matrix visualized in Figure is a concrete example of a shear matrix.
Orthogonal matrix
An orthogonal matrix is a square matrix whose columns and rows are orthogonal unit vectors. Let represent the -th column vector of . Recall that two vectors are orthogonal if the dot product between them is . Geometrically, this means that if you were to project one vector onto another, it would turn into a point rather than a line (Figure ).
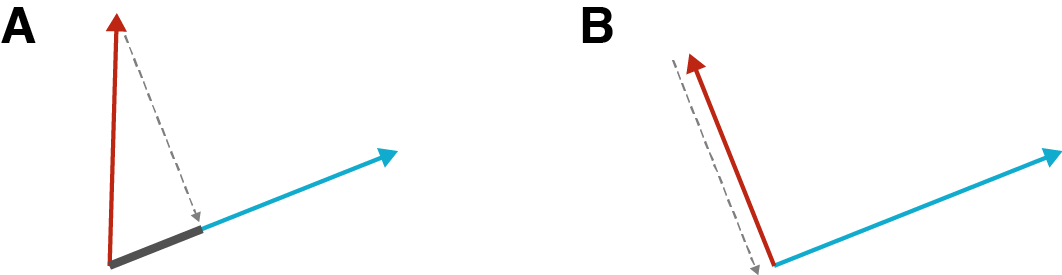
So the columns for all . And since the columns are unit vectors, then . An immediate consequence of this is that if a matrix is orthogonal, then:
If this is not obvious, write out the matrices explicitly as column and row vectors:
But what is the geometric intuition for orthogonal matrices? In words, an orthogonal matrix can rotate or flip a vector space, but it will not stretch it or compress it. But we can make our thinking more rigorous. The key is to observe a few key properties of orthogonal matrices:
1. Angles are preserved
Given a set of vectors, , which we can represent as columns in a matrix , an orthogonal matrix will preserve all the angles between pairs of vectors in this set after the transformation . To see this, let denote the dot product between vectors and . Then,
In words, all angles between pairs of vectors are preserved.
2. Lengths are preserved
Given our same set of vectors , an orthogonal matrix will preserve all lengths of the vectors after the transformation . This proof is just a small modification of the previous proof:
In words, the length of any vector in is preserved after transformation.
3. Area is preserved
Note that the determinant of an orthogonal matrix is either or . This is because,
Since the determinant represents the signed factor that the area of an -cube is multiplied by when being transformed by a matrix, a determinant of or means the cube is only rotated or reflected.
To summarize the previous three points: angles, lengths, and areas of a vector space transformed by an orthogonal matrix are all preserved. In my mind, this is a beautiful result. We have a geometric notion of an orthogonal matrix as a function that can only rotate or reflect a vector space, but we can combine this intuition with formal mathematical ideas such as orthogonality of vectors, the definition of the dot product, and the determinant to say something that is mathematically precise.
Composing linear functions
Since is linear if both and are linear, we can compose matrix transformations using matrix multiplications. In fact, because of singular value decomposition (SVD), we make a very strong claim: any matrix has a singular value decomposition where and are orthogonal matrices and is diagonal. Intuitively, this means we can decompose any matrix transformation into simpler transformations such as unitary transformations and diagonal transformations. This falls out of the fact that the image of the unit sphere under any matrix transformation is a hyperellipse.
I want to save SVD for a future post, but let’s look at a simple example of matrix multiplication as function composition from (Paeth, 1986), who claims but does not prove that any rotation matrix can be decomposed into three shear matrices. Following the example in that paper, consider decomposing a rotation matrix and three shear matrices :
Using a little trigonometry, we can solve for , , and . See the Appendix for a derivation. We can sanity check our work visualizing the matrix transformations for a specific , say (Figure ).
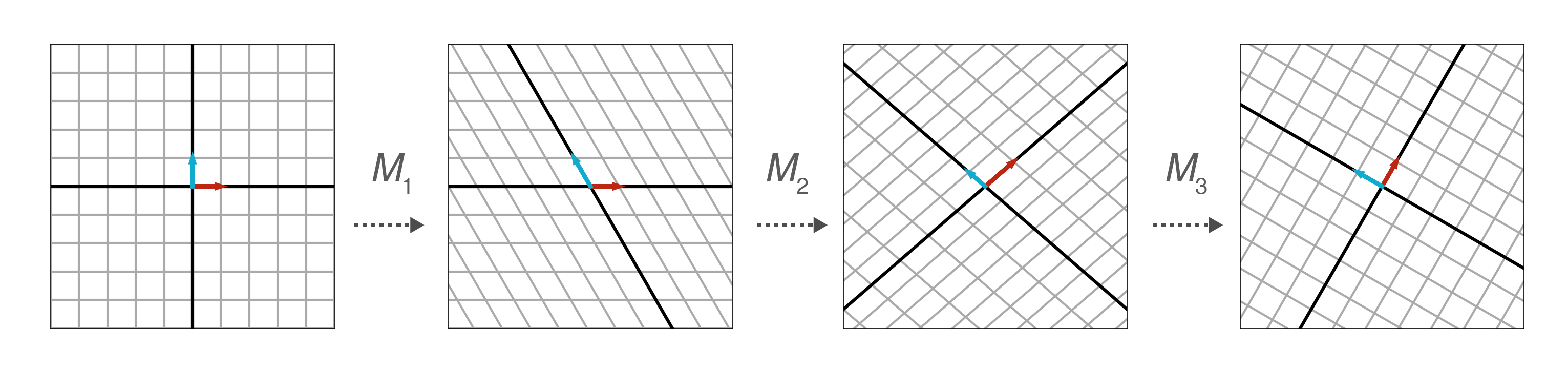
I think this is a really beautiful way to think about matrix multiplication, and it also drives home the utility of a geometrical understanding. For example, image shearing and then rotating a unit square. Now imagine applying the rotation matrix first and then shearing the rotated matrix—be sure to shear with respect to the standard basis vectors, not along an axis parallel with the rotated matrix! You won’t get the same resultant matrix. (It may help to sketch this out.) What this means that matrix multiplication is not necessarily commutative, and this is a property you can visualize rather than just remember.
Properties of matrices
With a geometrical understanding of matrices as linear transformations, many concepts in linear algebra are easier to appreciate. Here are just a concepts that are, in my mind, easier to understand geometrically.
Invertibility
Thinking of a matrix as a geometric transformation or projection, it should be clear that a rectangular matrix cannot be invertible. This is because a rectangular matrix projects vectors into either a higher- or lower-dimensional space. Imagine you found an apple lying on the ground beneath an apple tree. Can you tell me how high it was before it fell to the ground?
Rank
The rank of a matrix is the maximal number of linearly independent columns of . Again, if we think of the columns of a matrix as defining where the standard basis vectors land after the transformation, then a low-rank matrix creates linear dependencies between standard basis vectors. The linear dependence between columns means that any projection will map a higher-dimensional vector space to a lower-dimensional vector space.
Null space
The null space is the set of all vectors that land on the origin or become null after a transformation. For example, if a matrix has rank , that means it projects all the points in a 3-dimensional space onto a plane. This means there are a line of vectors that all land on the origin. If this is hard to visualize, imagine flattening a cardboard box in which the origin is in the center of the box. As you flatten the box, there must a line of vectors that all collapse to the origin.
Spectral norm
The spectral norm computes the maximum singular value of a matrix:
Since a matrix transforms a vector, we can think of the spectral norm as measuring the maximum amount that a matrix can “stretch” a vector. Many methods and proofs in numerical and randomized linear algebra rely on this norm. For example, algorithms in (Mahoney, 2016) use the spectral norm to bound randomized approximations of matrix multiplication.
Determinant
The determinant has the property that it is multiplicative. That is:
You can easily find formal proofs of this, but let’s convince ourselves that this is at least plausible through geometrical intuition. Consider a scenario in which and are defined as follows:
Our geometrical understanding of matrices suggests that matrix dilates by and matrix dilates by . Can you see why the determiant is multiplicative (Figure )?

The determinant of is , while the determinant of is . And what is the determinant of ? It is because it dilates a unit cube by .
Another cool property of the determinant that is easy to visualize is its sign. The sign of the determinant is positive if the matrix does not change the chirality of the space and negative if it does. This is, I think, easy to visualize (Figure ).
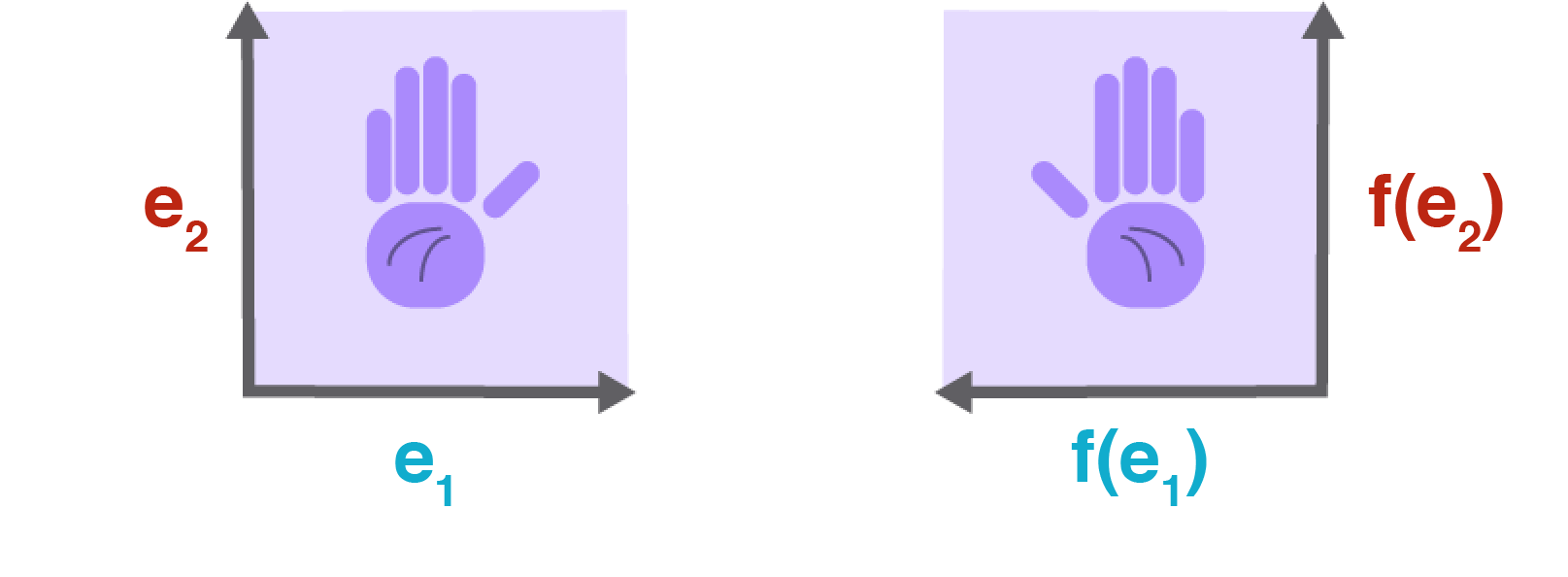
Imagine a chiral object—that is, an object that cannot be mapped to its mirror image by rotations and translations alone, for example a hand. A matrix transformation on that chiral object that changes its chirality changes the sign of the determinant.
Conclusion
While thinking about these ideas, I came across this lecture by Amritanshu Prasad, who argues at the end of the video for a geometrical understanding:
Most of us think fairly geometrically to start with, and algebra comes as part of training. Also, a lot of mathematics comes from trying to model problems in physics where we really need to think geometrically. So in that sense, a definition that is geometric has much more relationship to the physical world around us and also perhaps gives us a better intuition about the object we’re studying.
Mathematics is a contact sport, and I have no illusions that a geometrical understanding that is not paired with rigorous, numerical understanding is sufficient. It is impossible to deeply understand a mathematical idea if you cannot formalize it. That said, I have found that my ability to “think in linear algebra” has been strengthened by a better geometrical understanding of the material.
Acknowledgements
I thank Philippe Eenens for helpful suggestions for clarifying the notation.
Appendix
1. Proof that matrices are linear transformations
To prove that a function is linear, we need to show two properties:
Let be an vector, so the -th column in , , is an -vector and there are such vectors. And let and be two -vectors. Then we can express a function as the linear combination of the columns of where the coefficients in are the scalar components in and :
Proving both properties is straightforward with this representation because we only need to rely on properties of scalar addition and multiplication.
Property 1
Property 2
2. Derivation for rotation matrix decomposition
To solve for , , and in terms of , let’s first multiply our matrices:
We are given that a rotation matrix is equivalent to these three shear matrices:
Now let’s solve. Immediately, we have:
We can use this to solve for :
Finally, let’s solve for :
- Trefethen, L. N., & Bau III, D. (1997). Numerical linear algebra (Vol. 50). Siam.
- Paeth, A. W. (1986). A fast algorithm for general raster rotation. Graphics Interface, 86(5).
- Mahoney, M. W. (2016). Lecture notes on randomized linear algebra. ArXiv Preprint ArXiv:1608.04481.