Why Metropolis–Hastings Works
Many authors introduce Metropolis–Hastings through its acceptance criteria without explaining why such a criteria allows us to sample from our target distribution. I provide a formal justification.
Metropolis–Hastings (MH) is an elegant algorithm that is based on a truly deep idea. Suppose we want to sample from a target distribution . We can evaluate , just not sample from it. MH performs a random walk according to a Markov chain whose stationary distribution is . At each step in the chain, a new state is proposed and either accepted or rejected according to a dynamically calculated probability, called the acceptance criteria. The Markov chain is never explicitly constructed; we cannot save the transition probability matrix to disk or print one of its rows. However, if the MH algorithm is run for long enough—until the Markov chain mixes—, then the probability of being on a given state in the chain is equal to the probability of the associated sample. Thus, walking the Markov chain and recording states is, in the long-run, like sampling from .
This should be mind-blowing. This is not obvious. If these ideas are new, you should have to read the above paragraph twice. However, my go-to authors for excellent explanations of machine learning ideas—(Bishop, 2006; MacKay, 2003; Murphy, 2012)—as well as most blogs introduce MH by presenting just the algorithm’s acceptance criteria with no justification for why the algorithm works. For example, after MacKay introduces notation and the acceptance criteria, he writes
It can be shown that for any positive (that is, any such that for all ) as , the probability distribution of tends to .
Above, is the target distribution (what I call ), is the proposal distribution which proposes new samples, and is the sample at step . That said, the above explanation completely elides the mind-blowing part: how is walking an implicit Markov chain the same as sampling from a target distribution, and how does the acceptance criteria ensure we’re randomly walking according to the desired chain?
The goal of this post is to formally justify the algorithm. The notation and proof is based on (Chib & Greenberg, 1995). I assume the reader understands Markov chains. Please see my previous post for an introduction if needed.
Notation
Consider a Markov chain with transition kernel where and is a subset of our sample space (technically, where is the Borel -field on ). So in words, is a conditional distribution function of moving from to a point in the set . Note that a transition kernel is the generalization of a transition matrix in finite state-spaces. Naturally, and self-loops are allowed, meaning that is not necessarily zero.
The stationary distribution of a Markov chain is defined as where
This is just the continuous state-space analog of the discrete case. In a discrete Markov chain taking values in , if the transition matrix is , then stationary distribution is
where is a -dimensional row vector. In words, the Markov chain has mixed when the probability of being on a given state no longer changes as we walk the chain.
The -th iterate or th application of the transition kernel is given by
As goes to infinity, the -th iterate converges to the stationary distribution or
The above is an alternative definition of .
Implicit Markov chain construction
Markov chain Monte Carlo (MCMC) approaches the problem of sampling in a beautiful but nonobvious way. We want to sample from a . Let’s imagine that is the stationary distribution of a particular Markov chain. If we could randomly walk that Markov chain, then we could sample from eventually. Thus, we need to construct a transition kernel which converges to in the limit.
Suppose we represent the transition kernel as
where is some function, is an indicator random variable taking the value one if condition is true and zero otherwise, and is defined as
Alternatively, we can write the kernel as
Thus, is the probability that the Markov chain remains at , and is not necessarily one because is not necessarily zero.
Now consider the following reversibility constraint,
If adheres to this constraint, then is the stationary distribution of . To see this, consider the following derivation:
Step is the key step. It only holds because of the reversibility constraint, and it’s what allows us to cancel all terms except .
Let’s review. We want to sample from some target distribution . We imagine that this distribution is the stationary distribution of some Markov chain, but we don’t know the chain’s transition kernel . The above derivation demonstrates that if we define as Equation and ensure that adheres to the reversibility constraint in Equation , then we will have found the transition kernel for a chain whose stationary distribution is our target distribution. This is the essence of Metropolis–Hastings. As we will see, MH’s acceptance criteria is constructed to ensure that the reversibility constraint is met.
Metropolis–Hastings
We want to construct the function such that it is reversible. Consider a candidate generating density, . This density, as in rejection sampling, generates candidate samples conditioned on that will be either rejected or accepted depending on some criteria. Note that if and are states, this is a Markov process because no past states are considered. The future only depends on the present. Since is a density, . If the following were true,
then we’re done. We’ve satisfied Equation . But most likely this is not the case. For example, we might find that
Our random process moves from to more often than from to . MH ensures equilibrium (reversibility) this by restricting some moves (samples) according to an acceptance criterion, . Thus, if a move is not made, the process returns to . Intuitively, this is what allows us to balance with . Let’s assume that moves from to happen more often than the reverse. Then our criteria would be
Of course, the probabilities could be reversed, but we can handle both cases this with a single expression:
If MH moves from to more than the reverse, then the numerator is greater than the denominator, and the probability of accepting a move to from goes down. If we move from to more than the reverse, the sample (move from to ) is accepted with probability one.
We have found our function . It is
And while it is unnecessary to write down, for completeness the full transition kernel is
In summary, if we conditionally sample according to the density and accept the proposed sample according to , then we’ll be randomly walking according to a Markov chain whose stationary distribution is .
Metropolis
Notice that for a symmetric conditional distribution—so —, Equation simplifies to
This is the predecessor to Metropolis–Hastings, the Metropolis algorithm invented by Nicholas Metropolis et al in 1953 (Metropolis et al., 1953). In 1970, Wilfred Hastings extended Equation to the more general asymmetrical case in Equation (Hastings, 1970). For example, if we assume that is a conditional Gaussian distribution, then running the Metropolis–Hastings algorithm is equivalent to running the Metropolis algorithm.
Example: Rosenbrock density
Imagine we want to sample from the Rosenbrock density (Figure ),
The Rosenbrock function (Rosenbrock, 1960) is a well-known test function in optimization because while finding a minimum is relatively easy, finding the global minimum at (, ) is less trivial. (Goodman & Weare, 2010) adapted the function to serve as a benchmark for MCMC algorithms.
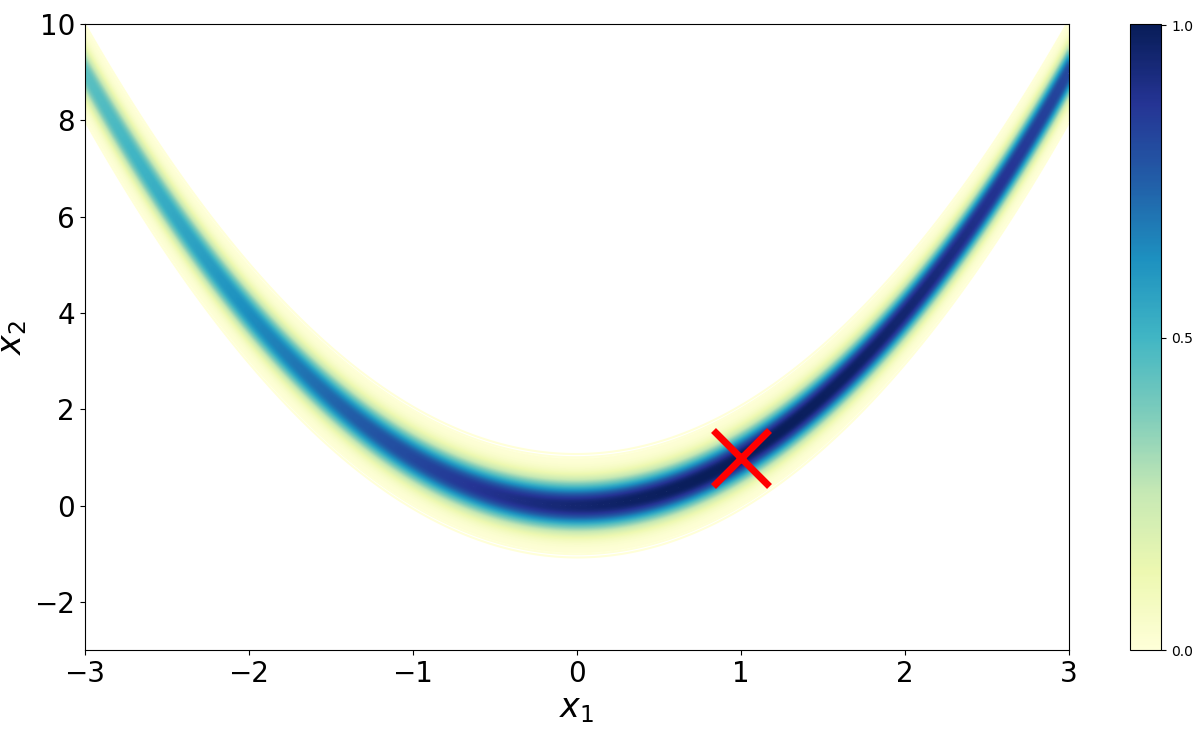
We must provide a candidate transition kernel . The only requirement is that we can sample conditionally from it and that for all . Perhaps the simplest possible kernel is to simply add Gaussian noise to . Thus, our candidate distribution is
where the variance controls how big each step is. Since the density is symmetric, we can implement the simpler Metropolis algorithm. We can accept a proposal sample with probability by drawing a uniform random variable with support , and checking if it is less than the acceptance criteria. For our setup, we have:
import numpy as np
from numpy.random import multivariate_normal as mvn
import matplotlib.pyplot as plt
n_iters = 1000
samples = np.empty((n_iters, 2))
samples[0] = np.random.uniform(low=[-3, -3], high=[3, 10], size=2)
rosen = lambda x, y: np.exp(-((1 - x)**2 + 100*(y - x**2)**2) / 20)
for i in range(1, n_iters):
curr = samples[i-1]
prop = curr + mvn(np.zeros(2), np.eye(2) * 0.1)
alpha = rosen(*prop) / rosen(*curr)
if np.random.uniform() < alpha:
curr = prop
samples[i] = curr
plt.plot(samples[:, 0], samples[:, 1])
plt.show()
That’s it. Despite its conceptual depth, Metropolis–Hastings is surprisingly simple to implement, and it is not hard to imagine writing a more general implementation that handles Equation for any arbitrary and .
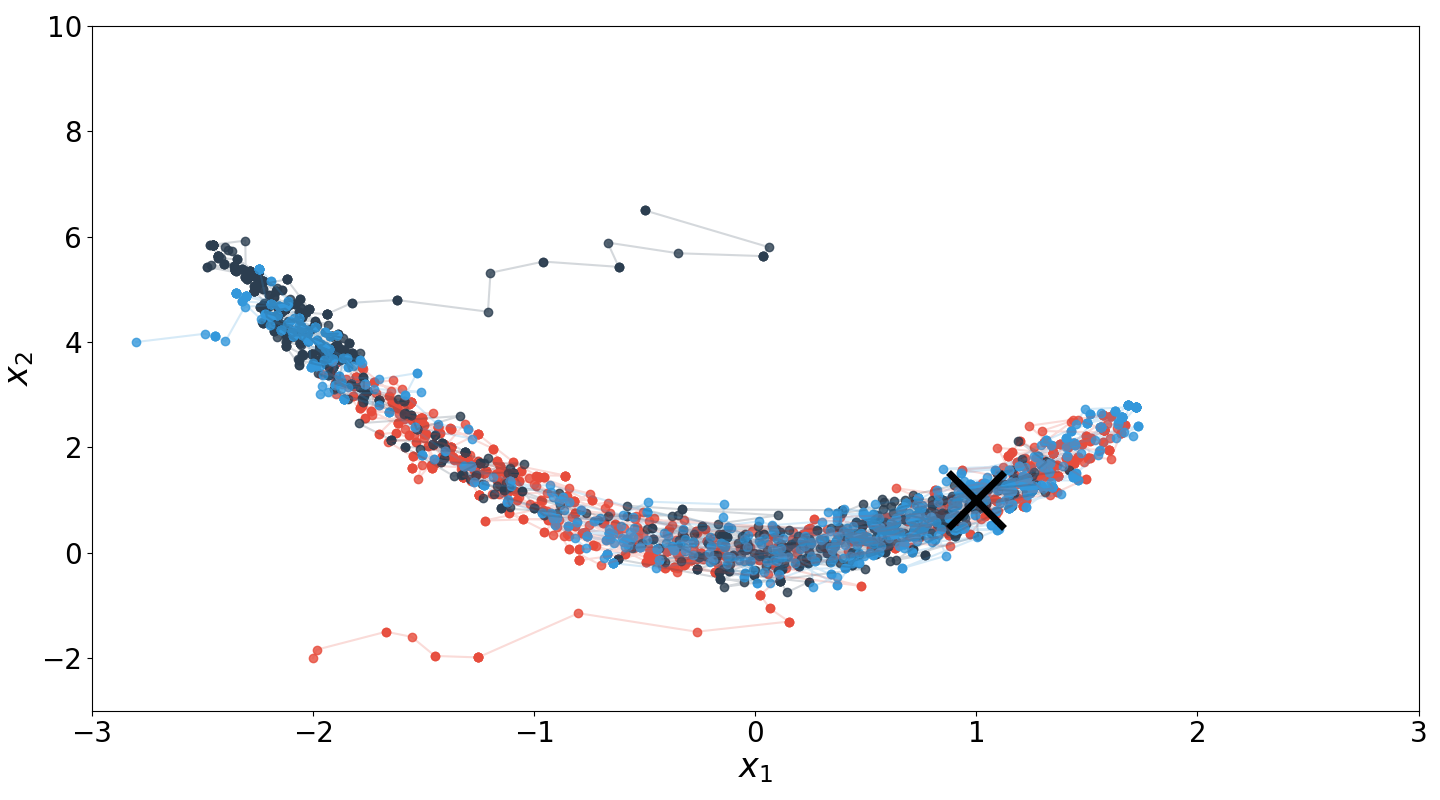
The above code is the basis for Figure , which runs three Markov chains from randomly initialized starting points. This example highlights two important implementation details for Metropolis–Hastings. First, step size (or for our candidate distribution) is important. If the step size were too large relative to the support of the Rosenbrock density, it would be difficult to sample near the distribution’s mode. Second, a so-called burn-in period in which initial samples are discarded is typically used. This is because samples before the chain starts to mix are not representative of the underlying distribution.
Conclusion
Metropolis–Hastings is a beautifully simple algorithm based on a truly original idea. We have these mathematical objects called Markov chains that, when ergodic, converge to their respective stationary distirbutions. We turn this idea on its head, and imagine that our target distribution is the stationary distribution for a given chain, and then implicitly construct that chain on the fly. The acceptance criteria ensures that the transition kernel will, in the long-run, induce the stationary distribution. Despite the algorithm being based on many deep ideas—think about how much intellectual machinery is embedded in this single paragraph—implementing the algorithm takes fewer than a dozen lines of code.
Acknowledgements
I thank Wei Deng for catching a couple typos around step .
- Bishop, C. M. (2006). Pattern Recognition and Machine Learning.
- MacKay, D. J. C. (2003). Information theory, inference and learning algorithms. Cambridge university press.
- Murphy, K. P. (2012). Machine learning: a probabilistic perspective. MIT press.
- Chib, S., & Greenberg, E. (1995). Understanding the metropolis-hastings algorithm. The American Statistician, 49(4), 327–335.
- Metropolis, N., Rosenbluth, A. W., Rosenbluth, M. N., Teller, A. H., & Teller, E. (1953). Equation of state calculations by fast computing machines. The Journal of Chemical Physics, 21(6), 1087–1092.
- Hastings, W. K. (1970). Monte Carlo sampling methods using Markov chains and their applications.
- Rosenbrock, H. H. (1960). An automatic method for finding the greatest or least value of a function. The Computer Journal, 3(3), 175–184.
- Goodman, J., & Weare, J. (2010). Ensemble samplers with affine invariance. Communications in Applied Mathematics and Computational Science, 5(1), 65–80.