Sampling: Two Basic Algorithms
Numerical sampling uses randomized algorithms to sample from and estimate properties of distributions. I explain two basic sampling algorithms, rejection sampling and importance sampling.
Introduction
In probabilistic machine learning, exact inference is often difficult or impossible when we cannot sample from or estimate the properties of a particular distribution. While we can leverage conjugacy to keep the distributions tractable or use variational inference to deterministically approximate a density, we can also use randomized methods for inference using numerical sampling, sometimes called Monte Carlo methods.
While we are sometimes interested in a posterior distribution per se, we are often only interested in properties of the distribution. For example, we need the first moment of a random variable for expectation–maximization. Thus, for many problems it is sufficient to either sample from or compute moments of a distribution of interest. I will introduce sampling in the context of two basic algorithms for these tasks.
I use bold and normal letters to indicate random variables and realizations respectively. So is a random variable, while is a realization of . I denote distributions with letters such as , , and so on. Thus, refers to the distribution of , while is the probability of under . Clearly we can evaluate for a realization from another random variable .
Rejection sampling
Consider the scenario in which we can evalute a density , but it is not clear how to sample from it. This may not be as abstract as it sounds. For example, consider the PDF of the exponential distribution with parameter ,
While we have a functional form for the distribution and can even prove that it satisfies some basic properties, e.g. it integrates to , it may not be obvious how to sample from . What if you did not have access to scipy.stats.expon on your computer?
Rejection sampling works by using a proposal distribution that we can sample from. The only constraint is that for some constant ,
In words, the area under the density curve for must be greater or equal to the area under the density curve for (Figure ).
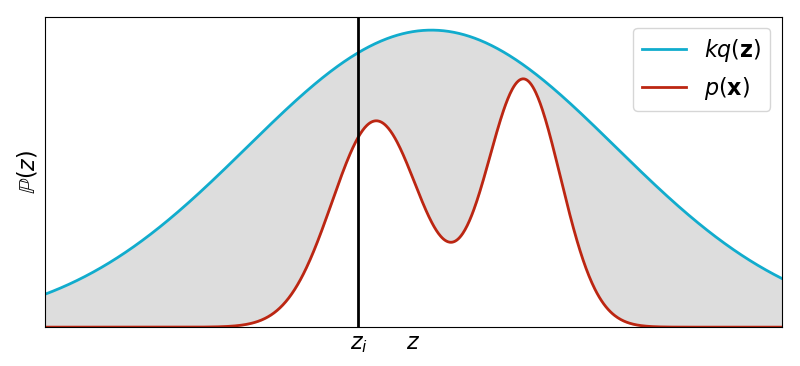
The algorithm for rejection sampling is,
- Sample from .
- Sample from .
- If , reject . Otherwise, accept it.
Why does this work? In words, the pair is uniformly distributed over the area under the curve of and since we reject samples outside of the area under the curve of , our accepted samples are uniformly distributed over the area under . While this makes some intuitive sense, I do not find such explanations particularly convincing. Let’s prove this works formally.
Proof
Let and be random variables with densities and . We assume can sample from . Let be a new random variable such that
This random variable represents the event that a sample is accepted; its conditional probability distribution is Bernoulli with a “success” parameter . We want to show that for any event , . In words, we want to show that the conditional probability of an event given that we accept a realization from is equal to the probability of that same event under . Using Bayes’ formula, we have
Let denote the conditional density of given . Then the numerator is
For the denominator, we compute the marginal of by integrating out , giving us
Putting everything together, we get
as desired.
Example
Consider the task of sampling from a bimodal distribution . We can use rejection sampling with a standard Gaussian scaled by an appropriate such that Equation holds (Figure ).
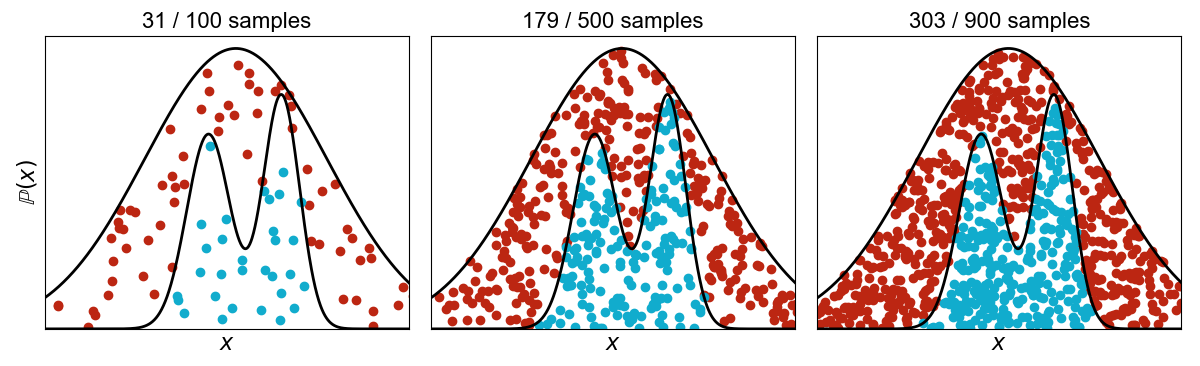
This highlights the main challenge of rejection sampling, which is computational efficiency. In this small example, we must discard roughly two-thirds of the samples in order to sample from , where is a univariate random variable. If were high-dimensional, we would throw out exponentially more samples.
Importance sampling
Importance sampling is a Monte Carlo method for approximating integrals. The word “sampling” is a bit confusing since, unlike rejection sampling, the method does not approximate samples from a desired distribution . In fact, we do not even have to be able to sample from .
The intuition is that a well-defined integral,
can be viewed as an expectation for a probability distribution,
where is
Provided when , then . Provided we can evaluate , we can approximate our integral using the Law of Large Numbers. We sample i.i.d. samples from the density and then compute
This estimator is unbiased and converges to in the limit of .
Now that we understand the main idea, let be a density that we cannot sample from but that we can evaluate. Provided are i.i.d. samples from , then for a function ,
where is defined as
Thus, provided we can sample from and evaluate and , we can get an unbiased estimator of the expectation .
The terms in Equation are called the importance weights because for each sample, they correct the bias induced by sampling from the wrong distribution, instead of .
There are some additional technical details, for example if we do not know the normalizing constants of or , but the goal of this post is to provide a high-level understanding. Please consult a standard textbook for these details.
Example
Let be a continuous random variable that we know to be beta distributed with specific parameters and . (Really, we just need to be able to evaluate .) Imagine that we did not know this random variable’s moments. We can use importance sampling to estimate them. Recall that a continuous random variable’s expectation is
Then if we set , we can use importance sampling to approximate the mean. We sample i.i.d. samples from and then estimate the first moment as
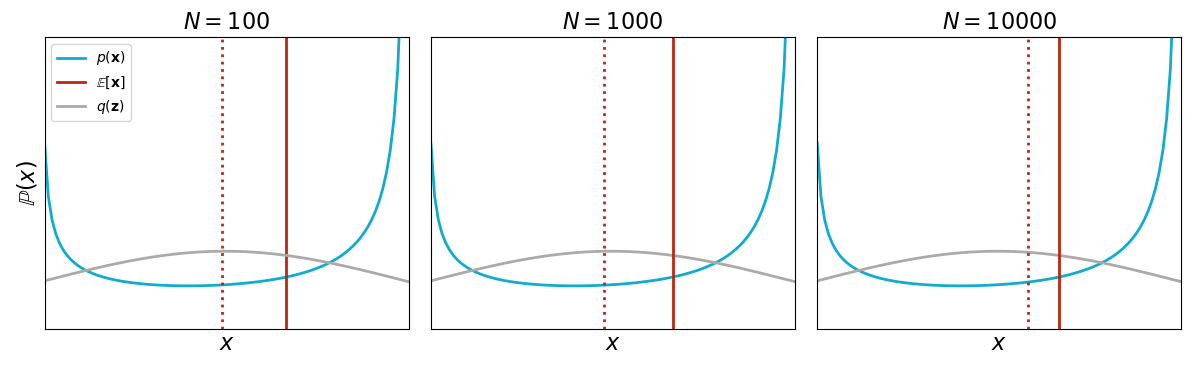
Let’s draw i.i.d. samples from a Gaussian distribution, and then use the importance weights to correct the bias of drawing from the wrong distribution. As with rejection sampling, our estimate of improves as increases (Figure ).
Conclusion
Numerical sampling is used widely in machine learning, and the goal of this post was to give a small flavor for how these methods work. In future posts, I hope to cover more advanced methods such as Metropolis–Hastings and Gibbs Sampling.