Simulating Geometric Brownian Motion
I work through a simple Python implementation of geometric Brownian motion and check it against the theoretical model.
In mathematical finance, a standard assumption is that an asset follows a geometric Brownian motion (GBM). Formally, this means that the asset follows this stochastic differential equation (SDE):
where is the asset price at time , is its drift, is its volatility, and is a Brownian motion. To rigorously understand this equation, we would need stochastic calculus in order to manipulate the stochastic differential , but let’s elide the technical details and focus on the discrete-time analog of this process, which I’ll write as
Here, is a discrete change in time, and is the change in the discrete-time process or
I’ve divided both sides of the equation by to underscore that the SDE is modeling the relative change in the asset price (the return). For example, imagine that time is in years, and that is one day or
Then the drift should the average annualized return of the asset. For example, if , then this means the asset’s average annualized return is , and therefore that the daily average return is
Of course, should also be in annualized terms. For example, if , then this means that the asset’s annualized volatility is , and therefore that the daily volatility is
Here, the falls naturally out of either properties of the normal distribution or the square-root of time rule, since we are assuming returns are i.i.d.
At this point, we have enough understanding to simulate the discrete-time process in Equation . But a little theory will help us sanity check our results. So let’s go back to the continous-time process for a moment. A standard result is that the solution to the SDE in Equation is
With a little algebra, we can easily see that this implies that the asset’s log return is normally distributed:
Equivalently, this means that the asset price is lognormally distributed. To disambiguate the parameters of the log normal distribution from the parameters of GBM, let’s use the following notation:
(We’ll see this distinction more clearly in the simulations.) While deriving Equation —technically, solving the SDE—requires stochastic calculus, the results here should make sense, since log returns approximate raw returns or
We can see that the average raw return ( in Equation ) differs from the average log return ( in Equation ) by the adjustment factor
This factor arises from applying the Itô–Doeblin lemma to solve the SDE, but you can safely ignore this point if it does not make sense. Anyway, what this means is that we can simulate GBM in discrete time using Equation , and then sanity check the results by confirming that over many simulations, various quantities converge to their theoretical (continuous-time) values. Let’s do that now.
Here is the basic code to simulate GBM:
# annualized drift of returns
mu = 0.04
# annualized volatility of returns
sigma = 0.18
# change in time in years
dt = 1/365
# annualized mean of log returns
m = (mu - 0.5 * sigma**2)
# annualized volatility of log returns
s = sigma
# daily log returns
logret = np.random.normal(m * dt, s * np.sqrt(dt), size=int(1/dt))
# daily raw returns
ret = np.exp(logret) - 1
# daily prices assuming S0=1
price = np.exp(logret.cumsum())
Using this code, we can simulate GBM over many trials (Figure ). Of course,
one should do this by changing the size argument above to account for
the number of trials. (Don’t write a for-loop.)
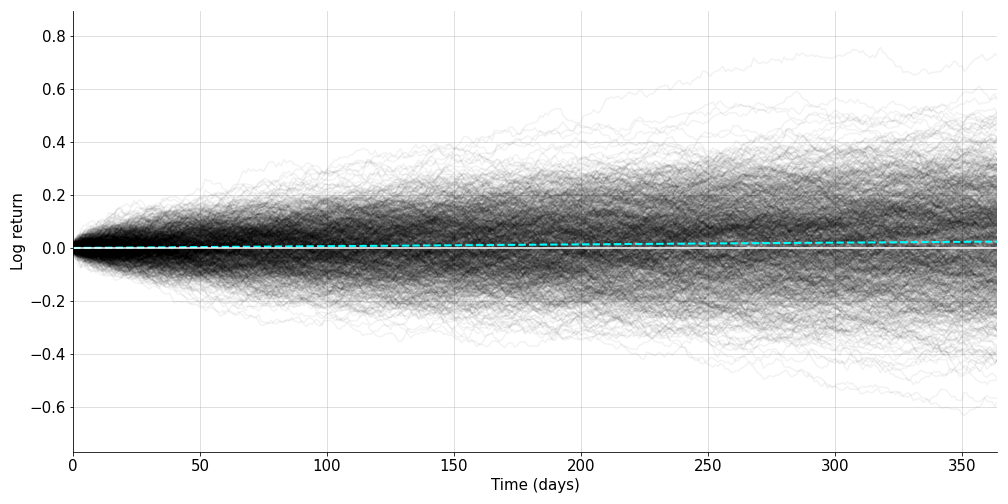
This looks directionally correct, but we can sanity check it quantitatively by comparing the simulations’ terminal distribution with the theoretical distribution (Equation ). Running one-hundred thousand simulations, I produced the normalized histogram in Figure and overlayed the theoretical distribution in cyan.
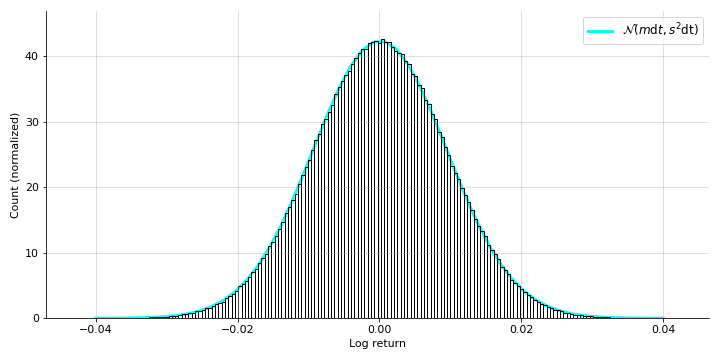
Now from Equation , we can see that the expected value of the log returns should be
while the expected value of the raw returns should be
We can also verify these claims quantitatively, although it’s hard to see visually with these particular numbers. For my simulations, I have the following results:
print(logrets.mean(), m * dt)
# (0.001050319587857524, 0.0010515068493150686)
print(rets.mean(), mu * dt)
# (0.0010952854516645238, 0.0010958904109589042)
And of course, we can make all our results tighter with more trials.