Returns and Log Returns
I discuss prices, returns, cumulative returns, and log returns, with a special focus on some nice mathematical properties of log returns.
Prices and returns
Prices between assets may be difficult to compare. For example, a large company might have a higher stock price than a smaller competitor. However, the bigger company’s price could be relatively stable, while the competitor’s smaller price is rapidly increasing. Thus, it is natural to want to think of prices in relative terms. Let denote the price of an asset at time . Then the return of an asset captures these relative movements and is defined as
In words, a return is the change in price of an asset, relative to its previous value. Note that , and therefore . Equation can be rewritten as
For example, if and , then the or a return of in one time period.
To highlight the difference between prices and returns, I have plotted the closing price and return of Apple Inc. (AAPL) for the past three years. Data is from Yahoo! Finance. We can see that AAPL returns were highest (and lowest) around March 2020, despite the closing price having a drawdown during that period.
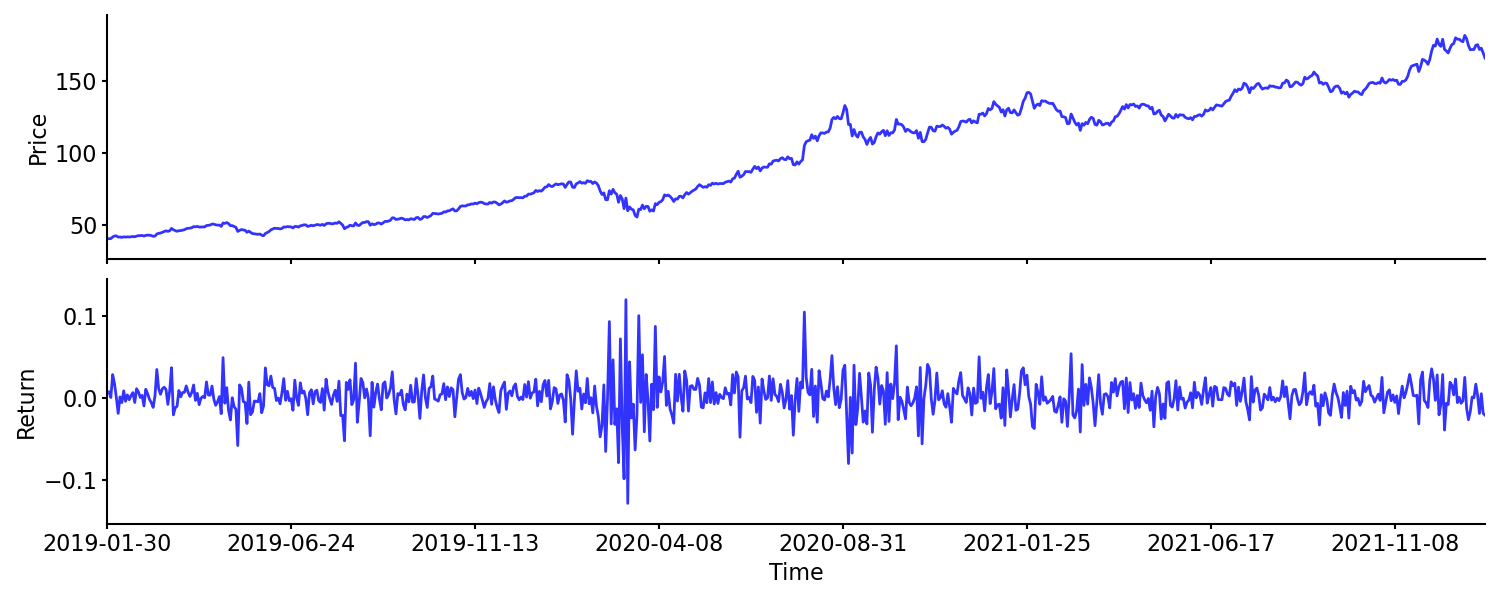
Cumulative returns
Imagine we invest principal into an asset with return sequence . What is our cumulative return, assuming we buy at and sell after , after realizing return ? For example, if we buy an asset for and see a , , and then return, our asset is worth
at time . So and . So our total return is
or a return. Since we started with and since our return was , our cumulative return was
This is just Equation over time periods:
Here, I use the notation with to refer to the cumulative return between periods and .
Notice that we are letting our returns compound continuously, meaning we are reinvesting any gains between time periods. However, we may want to constantly rebalance our portfolio, so that we have a constant exposure . What this means is that after each day (or time period), we either take a profit (if positive return) or buy more of the asset (if negative return) to ensure that we always have of the asset at the beginning of each period. In that case, after days, our profit (not return) is
Here, I use rather than to disambiguate prices from profit. For example, if we invest into an asset, which then has returns , then our profit is
And our cumulative return with rebalancing is again similar to Equation for time periods:
However, something subtle is happening here. Notice that our profit, , can be negative, unlike prices. And while a single return is lower-bounded by , since prices are lower-bounded by zero, the return with rebalancing could be infinitely negative. This is because we could be reinvesting over an infinite series of negative returns.
To summarize, we have two kinds of cumulative returns:
Which is being referred to often depends on context. However, for the remainder of this post, let’s focus on continuously compounded cumulative returns.
Log returns
In practice, “returns” often means “log returns”. Log returns are defined as
This can be expressed in terms of and (as in Equation ) as
Let’s look at a few reasons why log returns are sometimes preferred over raw returns.
Infinite support
Returns are lower-bounded by . One cannot lose more than all of one’s money. However, log returns have an infinite support. And since the log function suppresses big positive values while emphasizing small negative values, log returns are more symmetric than returns. This is a natural consequence of logarithms (Figure , left).
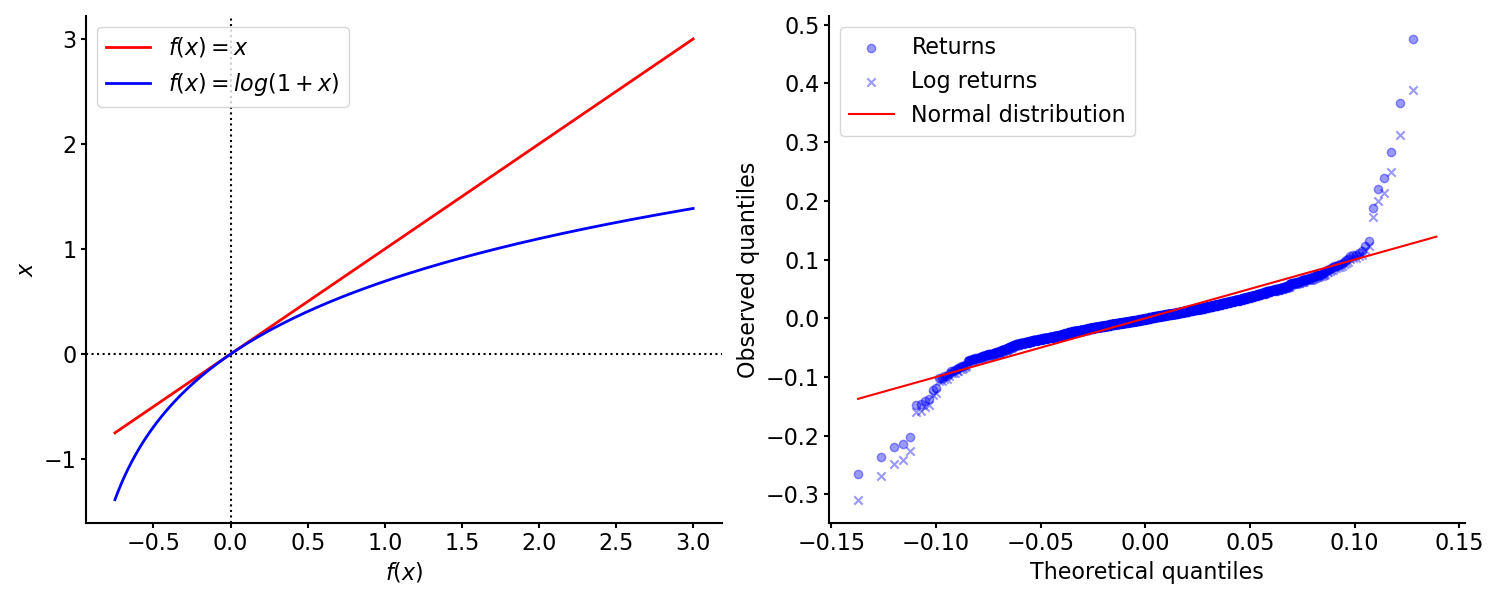
Another way to see this is to plot the theoretical quantiles of a symmetric distribution against the observed quantiles of our data. This is sometimes called a probability plot. In Figure (right), I’ve created a probability plot for Snap Inc. (SNAP) returns using the normal distribution as the theoretical distribution. We can see that both raw and log returns have fatter tails than the normal distribution, while log returns are slightly more symmetric. (Again, data is from Yahoo! Finance.)
Normality
A common argument for log returns is that they are normally distributed if prices are log normally distributed. Recall that a random variable is log normally distributed with mean and standard deviation if
Equivalently, we could write this as
Now assume that prices are log normally distributed. Then clearly
is the sum of two normal random variables.
scipy.stats.lognorm.fit.
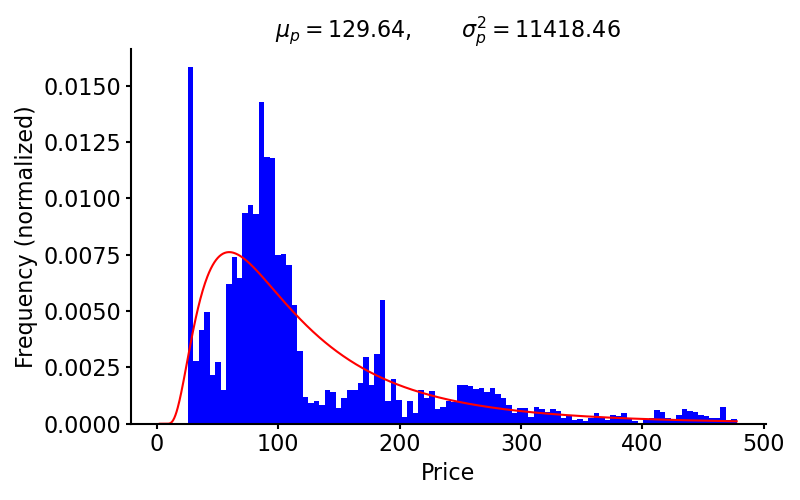
Does it make sense to assume that prices are log normally distributed? Prices are lower bounded at zero. Therefore, the typical justifications for this assumption are that (1) the log normal distribution has the correct support, , and that (2) it is mathematically convenient.
To illustrate this assumption, I have plotted a histogram of the SPDR S&P 500 Trust ETF’s (SPY) prices along with the best-fit log normal distribution (Figure ). I used scipy.stats.lognorm.fit to fit the distribution, and again, data is from Yahoo! Finance. We can see that, as a first approximation, the log normal distribution is not completely unreasonable, but it’s certainly not a good model of these data.
Compounded return
Consider Equation for computing continuously compounded returns. If we take of both sides, we get
Furthermore, notice that implicit in each term are the prices and , and that most of these terms will cancel:
So one nice mathematical fact about log returns is that we can compute continuously compounding returns by subtracting the log of the initial price from the log of the final price.
For example, using the data in Figure , AAPL’s total compounded return is approximately . If we had invested in AAPL at the beginning of January and held until the end of , we would now have over . We can verify that our calculations are consistent, regardless of whether we use Equation or Equation :
>>> (1 + returns).prod() - 1
3.1448448132962152
>>> np.exp(np.log(closes[-1]) - np.log(closes[0])) - 1
3.1448448132962152
Note that we had to back out the raw return from the log return using the inverse of Equation ,
Clearly, the second calculation is faster, especially if we have a lot of data.
Approximations
A final reason for log returns is that, in addition to their nice mathematical properties, they often approximate raw returns well. This is because
when is close to zero, and returns are typically close to zero. The easiest way to see this is to note that at the origin, the tangent line approximates well (Figure , left).
Formally, we can see this using a first-order Taylor approximation of at a point :
So when at the origin, then . This is for the natural logarithm, of course, since otherwise
where is the base. So (natural) log returns are a good approximation of raw returns when the raw returns are close to zero.