Rahimi and Recht's 2007 paper, "Random Features for Large-Scale Kernel Machines", introduces a framework for randomized, low-dimensional approximations of kernel functions. I discuss this paper in detail with a focus on random Fourier features.
Published
23 December 2019
Kernel machines
Consider a learning problem with data and targets {(xn,yn)}n=1N where xn∈X and yn∈Y. Ignoring the bias, a linear model finds a hyperplane w such that the decision function
f∗(x)=w⊤x(1)
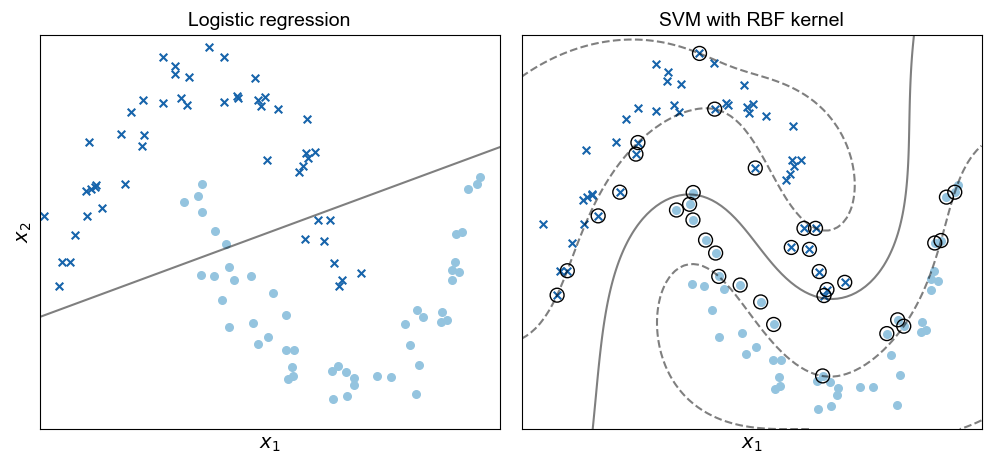
is optimal for some loss function. For example, in logistic regression, we compute the logistic function of f(x), and then threshold the output probability to produce a binary classifier with Y={0,1}. Obviously, linear models break down when our data are not linearly separable for classification (Figure 1, left) or do not have a linear relationship between the features and targets for regression.
In a kernel machine or a kernel method, the input domain X is mapped into another space V in which the targets may be a linear function of the data. The dimension of V may be high or even infinite, but kernel methods avoid operating explicitly in this space using the kernel trick: if k:X×X↦R is a positive definite kernel, then by Mercer’s theorem there exists a basis function or feature mapφ:X↦V such that
k(x,y)=⟨φ(x),φ(y)⟩V.(2)
⟨⋅,⋅⟩V is an inner product in V. If the kernel trick is new to you, please see my previous post. Using the kernel trick and a representer theorem (Kimeldorf & Wahba, 1971), kernel methods construct nonlinear models of X that are linear in k(⋅,⋅),
f∗(x)=n=1∑Nαnk(x,xn)=⟨w,φ(x)⟩V.(3)
In (3), f∗(⋅) denotes the optimal f(⋅). Taken together, (2) and (3) say that provided we have a positive definite kernel function k(⋅,⋅), we can avoid operating in the possibly infinite-dimensional space V and instead only compute over N data points. This works because the optimal decision rule can be expressed as an expansion in terms of the training samples. See (Schölkopf et al., 2001) for a detailed treatment on this topic.
If the representer theorem is new to you, note that you’ve already seen it in action. For example, the optimal coefficients in linear regression are
w^=(X⊤X)−1X⊤y,(4)
where X is an N×D matrix of training data. We make predictions on held out data X∗ as y∗=X∗w^. In other words, the optimal prediction for a linear model can be viewed as an expansion in terms of the training samples. For a second example, recall that the posterior mean of a Gaussian process (GP) regressor is
E[f∗]=KX∗,X[σ2I+KX,X]−1yβ,(5)
where the notation KX∗,X denotes the kernel function evaluated at all pairs of samples in X∗ and X. See my previous post on GP regression if needed. For each component in the M-vector E[f∗] (each prediction ym), the GP prediction is a linear-in-β model of the kernel evaluated at the test data xm against all the training points.
Perhaps the most famous kernel machine is the nonlinear support vector machine (SVM) (Figure 1, right). However, any algorithm that can be represented as a dot product between pairs of samples can be converted into a kernel method using (2). Other methods that can be considered kernel methods are GPs, kernel PCA, and kernel regression.
Figure 1. Logistic regression (left) with decision boundary denoted with a solid line and SVM with radial basis function (RBF) kernel (right) on the Scikit-learn half-circles dataset. Support vectors are denoted with circles, and the margins are denoted with dashed lines.
While the kernel trick is a beautiful idea and the conceptual backbone of kernel machines, the problem is that for large datasets (for huge N), the machine must operate on a covariance matrix KX, induced by a particular kernel function, that is N×N,
For example, in the Gaussian process regressor in (5), the right-most covariance kernel KX,X is an N×N matrix. To compute β, we must invert this. Furthermore, to evaluate a test data point, the model must evaluate the sum in (3). While we’re avoiding computing in V, we are stuck operating in RN. In the area of big data, kernel methods do not necessarily scale.
Random features
In their 2007 paper, Random Features for Large-Scale Kernel Machines(Rahimi & Recht, 2007), Ali Rahimi and Ben Recht propose a different tack: approximate the above inner product in (2) with a randomized map z:RD↦RR where ideally R≪N,
k(x,y)=⟨φ(x),φ(y)⟩V≈z(x)⊤z(y).(7)
See this talk by Rahimi for details on the theoretical guarantees of this approximation. Why does this work and why is it it a good idea? The representer theorem tells us that the optimal solution is a weighted sum of the kernel evaluated at our observations. If we have a good approximation of φ(⋅), then
In other words, provided z(⋅) is a good approximation of φ(⋅), then we can simply project our data using z(⋅) and then use fast linear models in RR rather than RN because both β and z(⋅) are R-vectors. So the task at hand is to find a random projection z(⋅) such that it well-approximates the corresponding nonlinear kernel machine.
According to this blog post by Rahimi, this idea was inspired by the following observation. Let ω be a random D-dimensional vector such that
ω∼ND(0,I).(9)
Now define h as
h:x↦exp(iω⊤x).(10)
Above, i is the imaginary unit. Let the superscript ∗ denote the complex conjugate. Importantly, recall that the complex conjugate of eix is e−ix. Then note
In other words, the expected value of h(x)h(y)∗ is the Gaussian kernel. See A1 for a complete derivation.
This is quite cool, and it is actually a specific instance of a more general result, Bochner’s theorem (Rudin, 1962). Quoting Rahimi and Recht’s version with small modifications for consistent notation, the theorem is:
Bochner’s theorem: A continuous kernel k(x,y)=k(x−y) on RD is positive definite if and only if k(Δ) is the Fourier transform of a non-negative measure.
The Fourier transform of a non-negative measure, call it p(ω), is
k(Δ)=∫p(ω)exp(iωΔ)dω.(12)
Rahimi and Recht observe that many popular kernels such as the Gaussian (or radial basis function), Laplace, and Cauchy kernels are shift-invariant. The upshot is that the transformation h(⋅) is an unbiased estimate of k(x−y). Which kernel is k(x−y)? It depends on the non-negative measure p(ω).
This gives us a general framework to approximate any shift-invariant kernel by re-defining h(⋅) in (10) to depend on ω from any non-negative measure p(ω), not just the spherical Gaussian in (9). Furthermore, if we sample R i.i.d. realizations {ωr}r=1R, we can lower the variance of this approximation:
Step 1 is a Monte Carlo approximation of the expectation. Step 2 is the definition of a random map h:RD↦RR, so an R-vector of normalized h(⋅) transformations.
Note that we’ve talked about the dot productz(x)⊤z(y), but above we have h(x)h(y)∗. As we will see in the next section, the imaginary part of our random map will disappear, and the new transform is what Rahimi and Recht call z.
Fine tuning
Now that we understand the big idea of a low-dimensional, randomized map and why it might work, let’s get into the weeds. First, note that since both our distribution ND(0,I) and the kernel k(Δ) are real-valued, we can write
We now have a simple algorithm to estimate a shift invariant, positive definite kernel. Draw R samples of ω∼p(ω) and b∼Uniform(0,2π) and then compute z(x)⊤z(y).
An alternative version of random Fourier features that you might see is
Before fitting a more complex model, let’s first approximate a Gaussian kernel using random Fourier features. Sample R i.i.d. ω variables from a spherical Gaussian and then compute
for each (x,y) pair in the data. The resultant N×N object is the approximate covariance matrix induced by the Gaussian kernel function. Concretely, let ZX denote z(⋅) applied to all N samples xn. Thus, ZX is N×R and therefore
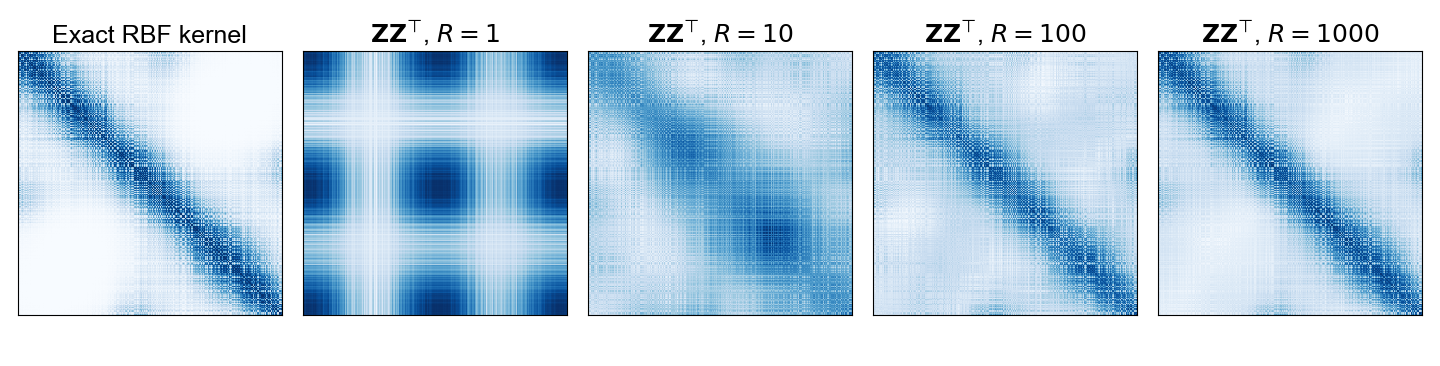
We see in Figure 2 that as R increases, the covariance matrix approximation improves because each cell value uses more Monte Carlo samples to estimate the basis function ϕ(⋅) associated with k(⋅,⋅) for the pair of samples associated with that cell. See my GitHub for the code to generate this figure.
Figure 2. A comparison of a Gaussian kernel on the Scikit-learn S-curve with random Fourier features (left) and an approximated covariance matrix with an increasing number of Monte Carlo samples (right four frames).
Kernel ridge regression
As a more complex example and to see concretely why random Fourier features are efficient, let’s look at kernel ridge regression. If needed, see (Welling, 2013) for an introduction to the model. Also, the Scikit-learn docs have a nice tutorial comparing kernel ridge and Gaussian process regression. (8) tells us that f∗(x) is linear in z(x). Therefore, we just need to convert our input x into random features and apply linear methods. Concretely, we just want to solve for the coefficients β in
β^=(AZX⊤ZX+λIR)−1ZX⊤y.(24)
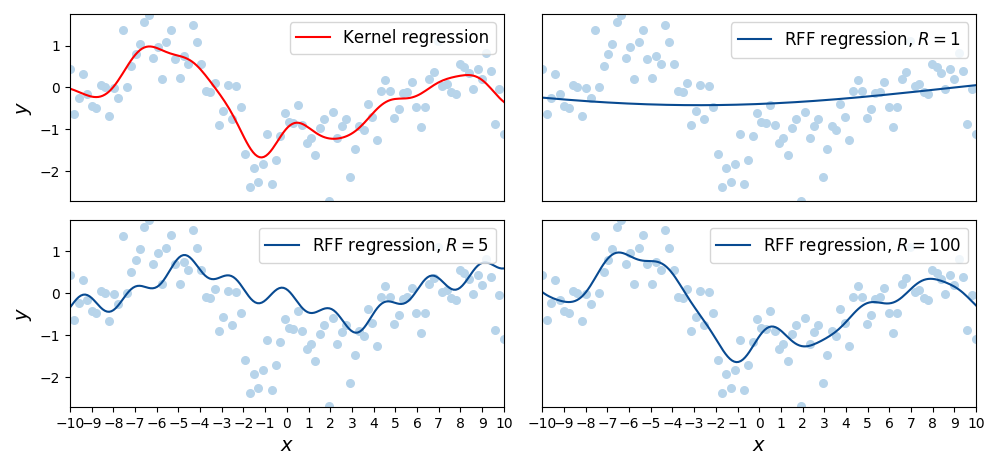
Above, λ is the ridge regression regularization parameter. See Figure 3 for the results of comparing Gaussian kernel regression with random Fourier feature regression.
Figure 3. Comparison of Gaussian kernel ridge regression (top left) with ridge regression using random Fourier features (RFF regression) on N=100 data points with R∈{1,5,100}.
With (24) in mind, it is clear why random Fourier features are efficient: inverting A has time complexity O(R3) rather than O(N3). If R≪N, then we can have big savings. What is not shown is that even on this small data set, random Fourier feature regression is over an order of magnitude faster than kernel regression with a Gaussian kernel. Since kernel machines scale poorly in N, it is easy to make this multiplier larger by increasing N while keeping R fixed.
Again, see my GitHub for a complete implementation. Note that we need to cache the random variables, ω1,ω2,…,ωR and b1,b2,…bR, for generating ZX so that we have the same transformation when we predict on test data.
Conclusion
Random features for kernel methods is a beautiful, simple, and practical idea; and I see why Rahimi and Recht’s paper won the Test of Time Award at NeurIPS 2017. Many theoretical results are impractical or complicated to implement. Many empirical results are not well-understood or brittle. Random features is neither: relatively speaking, it is a simple idea using established mathematics, yet it comes equipped with good theoretical guarantees and good results with practical, easy-to-implement models.
Acknowledgements
I thank Era Choshen for pointing out an error in appendix A3.
In other words, k(⋅) is the Gaussian kernel with p(ω) is a spherical Gaussian.
A2. Trigonometric identity
Recall from trigonometry that
cos(x+y)=cos(x)cos(y)−sin(x)sin(y).(A2.1)
See this Khan Academy video for a proof. Furthermore, note that cos(−x)=cos(x) since the cosine function is symmetric about x=0. This is not true of the sine function. Instead, it has odd symmetry: sin(−x)=−sin(x). Thus, with a little clever manipulation, we can write
The right-most terms above cancel in (A4.3), and we get 2cos(x−y).
Kimeldorf, G., & Wahba, G. (1971). Some results on Tchebycheffian spline functions. Journal of Mathematical Analysis and Applications, 33(1), 82–95.
Schölkopf, B., Herbrich, R., & Smola, A. J. (2001). A generalized representer theorem. International Conference on Computational Learning Theory, 416–426.
Rahimi, A., & Recht, B. (2007). Random features for large-scale kernel machines. Advances in Neural Information Processing Systems, 1177–1184.
Rudin, W. (1962). Fourier analysis on groups (Vol. 121967). Wiley Online Library.
Sutherland, D. J., & Schneider, J. (2015). On the error of random fourier features. ArXiv Preprint ArXiv:1506.02785.
Welling, M. (2013). Kernel ridge regression. Max Welling’s Classnotes in Machine Learning, 1–3.