Conjugate Gradient Descent
Conjugate gradient descent (CGD) is an iterative algorithm for minimizing quadratic functions. CGD uses a kind of orthogonality (conjugacy) to efficiently search for the minimum. I present CGD by building it up from gradient descent.
In statistics and optimization, we often want to minimize quadratic functions of the following form,
when is a symmetric and positive definite matrix. For example, optimizing a Gaussian log likelihood may reduce to this type of problem. Since is symmetric, the gradient is
which implies that the global minimum is the solution to the equation
See this section on quadratic programming if the derivation above was too fast. An efficient solution to this problem is conjugate gradient descent (CGD), which is gradient descent with a line search that accounts for the positive-definiteness of . CGD requires no tuning and is typically much faster than gradient descent.
The goal of this post is to understand and implement CGD. There are many excellent presentations of CGD, such as (Shewchuk, 1994). However, I found that many resources focus on deriving various terms rather than the main ideas. The main ideas of CGD are surprisingly simple, and my hope in this post is to make those simple ideas clear.
Gradient descent
Gradient descent is an iterative method. Let denote the gradient at iteration ,
Gradient descent moves away from the gradient (“downhill”) through the following update rule:
In words, given a point in -dimensional space, we compute the gradient and then move away from the steepest direction towards the minimum. Given that the size of the gradient has no relationship to how big a step we should to take, we rescale the size of the step with a step size hyperparameter . Typically, is constant across iterations, i.e. .
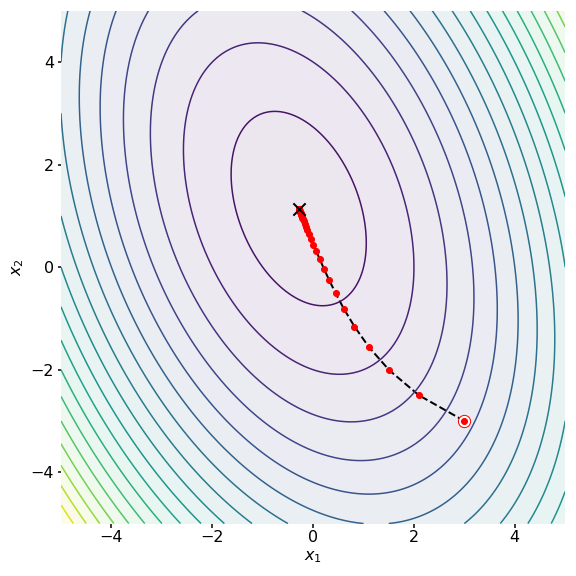
See Figure for an example of gradient descent in action on a -dimensional problem. We can see that with an appropriate step size, gradient descent moves smoothly towards the global minimum (Figure , black “X”). Throughout this post, I’ll use the values
for , , and in Equation .
In Python, gradient descent can be implement as follows:
def gd(A, b, alpha=1e-3):
"""Run gradient descent with step-size alpha to solve Ax = b.
"""
dim = A.shape[0]
x = np.random.randn(dim)
xs = [x]
while True:
g = A @ x - b
x = x - alpha * g
if np.linalg.norm(x - xs[-1]) < 1e-6:
break
xs.append(x)
return np.array(xs)
This implementation is didactic and obviously avoids many edge-cases for clarity.
Steepest descent
One challenge with gradient descent is that we must pick the step size . The gradient tells us in which direction we want to move, but it does not tell us how far we should move. For example, consider the left subplot of Figure . The gradient from the initial point (red dot) suggests that we move along the dashed blue line. However, it may not be obvious how far along this line we should go. Another problem with a fixed step size is that gradient descent can slow down as it approaches the minimum (Figure ). In fact, gradient descent took iterations to converge on this simple problem.
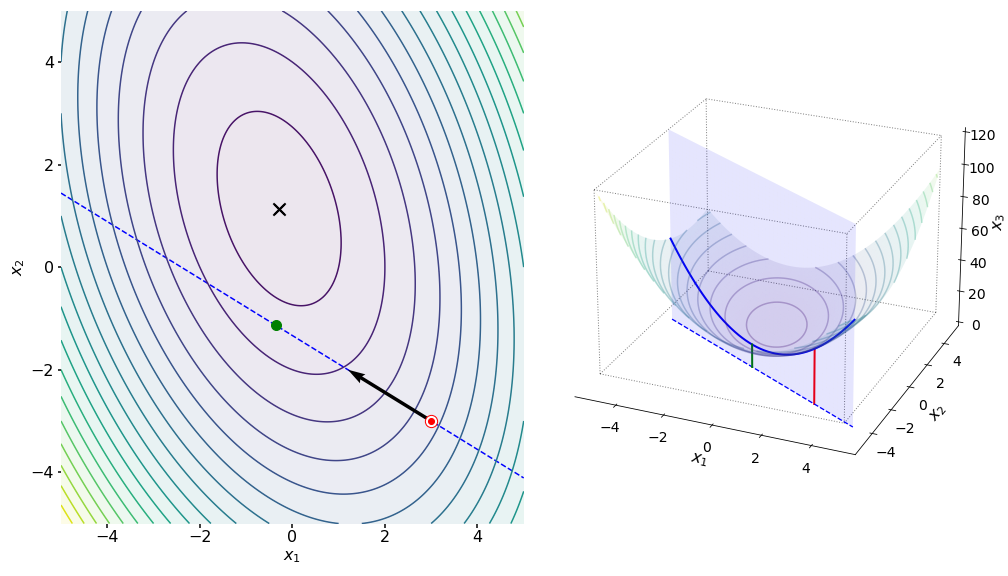
A natural extension to gradient descent is a method sometimes called steepest descent, which automatically computes the optimal step size at each iteration. One way to visualize this is to imagine a line collinear with the gradient (Figure , left, dashed blue line) as being a plane that slices through the quadratic surface. The intersection between this plane and the quadratic surface is a parabola (Figure , right, solid blue line). Intuitively, we want to take a step size that moves us to the minimum of this parabola.
Mathematically, this means that we want to minimize the following:
To compute the minimizer , we take the derivative,
and set it equal to zero to solve for (as usual, I am ignoring verifying that is not an endpoint or a maximizer):
So the optimal (Equation ) leverages the gradient at iteration and . Putting it all together, the steepest descent update rules are
See Figure for an example of steepest descent in action on the same -dimensional problem as in Figure . While gradient descent took iterations, steepest descent took only iterations. While it is possible that gradient descent could be faster with a bigger step size, we would have to know the optimal step size a priori or tune the algorithm.

In Python, steepest descent can be implement as follows:
def sd(A, b):
"""Run steepest descent to solve Ax = b.
"""
dim = A.shape[0]
x = np.random.randn(dim)
xs = [x]
while True:
r = b - A @ x
alpha = (r.T @ r) / (r.T @ A @ r)
x = x + alpha * r
if np.linalg.norm(x - xs[-1]) < 1e-6:
break
xs.append(x)
return np.array(xs)
Now consider the following important idea, which will also arise in CGD: in steepest descent, the directions vectors are orthogonal. This is not an accident. Imagine we start at the red dot with a white border in Figure , the initial point . Then imagine that we search along a line that is collinear with the gradient (Figure , blue dashed line). If we compute the gradient at each point along this blue line, the function is minimized when the gradient is orthogonal to the search line. In Figure , I’ve illustrate this by plotting lines that are collinear with the gradients at various points along the blue line.

I think this is geometrically intuitive, but we can also prove it from the definition of :
This derivation proves that at each iteration , the current gradient will be orthogonal to the next gradient . This is precisely why, in Figure , steepest descent repeatedly takes only two directions which are orthogonal to each other, since there are only two dimensions in the problem. Thus, a failure mode of steepest descent is that it can search in the same direction repeatedly. It would be ideal if we could avoid these repeated steps.
The basic idea of conjugate gradient descent is to take steps that are orthogonal with respect to . This property of orthogonality with respect to a matrix is called “-orthogonality” or “conjugacy”. (In the phrase “conjugate gradient descent”, “conjugate” modifies “gradient descent”, not the word “gradient”. Thus, CGD is gradient descent with conjugate directions, not conjugate gradients.) Thus, before we can understand conjugate gradient descent, we need to take an aside to understand -orthogonality. Let’s do that now.
-orthogonality
Let be a symmetric and positive definite matrix. Two vectors and are -orthogonal if
The way I think about this is that since is symmetric and positive definite, it can be decomposed into a matrix such that
So we can think of Equation above as
So -orthogonal means that the two vectors are orthogonal after being mapped by —loosely speaking, after accounting for the structure of .
Just as vectors that are mutually orthogonal form a basis in , vectors that are -orthogonal form a basis of . To prove this, let be a set of mutually -orthogonal vectors. Now consider the linear combination
To prove that forms a basis, it is sufficient to prove that the set is linearly independent, and to prove that, we must prove that for all . We can do this using the fact that is symmetric and positive definite. First, let’s left-multiply Equation by where :
Since is positive definite, it must be the case that
This implies that for all , which proves that is a linearly independent set, i.e. spans .
Conjugate gradient descent
Let’s return to our problem. How would someone come up with an idea like CGD? Put differently, why would someone think searching in conjugate directions is a good idea? Let be the error or distance between and the global minimum at iteration ,
Notice that this error term must be -orthogonal to the gradient. This falls out of the fact that the gradients are orthogonal:
In other words, imagine we take the optimal first step using steepest descent (Figure , blue arrow). Then the error between and (Figure , green arrow) is conjugate to the initial direction. The blue and green arrows are -orthogonal by Equation .

What this suggests is that we should search in directions that are -orthogonal to each other. This is precisely what CGD does.
To see that this approach will work, consider a set of mutually -orthogonal or conjugate vectors
Since we proved that these form a basis in , we can express the minimum as a unique linear combination of them
Following the proof of linear independence in the previous section, let’s left-multiply both sides of Equation by , where :
The sum disappears because the vectors are mutually conjugate, so
And here is the magic. Since , we can solve for without using :
This is beautiful and surprising to me. What it says is that one way to find the minimum is the following: find , a set of mutually conjugate search directions. Next compute each . Finally, compute using Equation . This derivation also makes clear why we need -orthogonality rather than orthogonality.
This also suggests why we need conjugacy rather than just orthogonality. If was a basis formed by orthogonal directions, then the left-hand side of Equation would be . We would not be able to eliminate from the equation.
In Python, this “direct” version of CGD can be implement as follows:
def cgd_direct(A, b):
"""Solve for x in Ax = b directly using an A-orthogonal basis.
"""
dim = A.shape[0]
# Run Gram–Schmidt like process to get A-orthogonal basis.
D = get_conjugate_basis(A)
# Compute the step size alphas.
alphas = np.empty(dim)
for i in range(dim):
d = D[i]
alphas[i] = (d @ b) / (d @ A @ d)
# Directly compute minimum point x_star.
x_star = np.sum(alphas[:, None] * D, axis=0)
return x_star
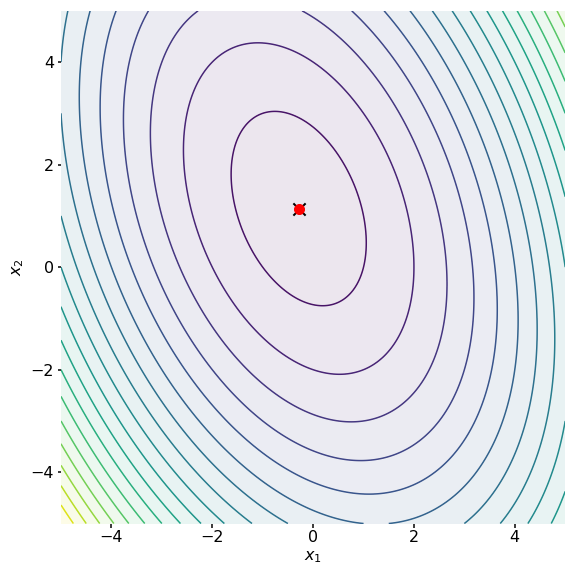
We can see that this correctly computes the minimum point (Figure ). Notice that this algorithm does not need an initial point or a step size. It does not even explicitly compute the gradient. It simply constructs an -orthogonal basis and then expresses the solution as a linear combination of the basis vectors.
-projections
How did we construct a set of mutually -orthogonal vectors? The basic idea is to run a Gram–Schmidt-like process, ensuring at each step that the newly added vector is -orthogonal (rather than just orthogonal) to the previous vectors. To understand this approach, let and be two vectors, and define the -projection of onto as
This allows us to construct a new vector that is -orthogonal to by subtracting the -projection of onto :
We can verify that the resulting vector is -orthogonal to :
If why this works does not make sense, I suggest drawing a picture of -orthogonalization based on my figures on the Gram–Schmidt algorithm in this post. While this is not a proof of correctness for an iterative approach to constructing , I think it captures the main idea for why it works. A proof would be similar to an induction proof for the correctness of the Gram–Schmidt process.
Here is code to compute an -orthogonal basis a la the Gram–Schmidt process:
def get_conjugate_basis(A):
"""Run a Gram-Schmidt-like process to get a conjugate basis.
"""
dim = A.shape[0]
# Select arbitrary vectors `vs` that form a basis (not necessarily
# conjugate) in R^dim. Technically, we should verify that `vs` form a basis
# and handle it if not.
vs = np.random.randn(dim, dim)
v = vs[0]
u = v / np.linalg.norm(v)
us = [u]
for i in range(1, dim):
v = vs[i]
for j in range(i):
v -= proj(A, v, us[j-1])
u = v / np.linalg.norm(v)
us.append(u)
return np.array(us)
def proj(A, v, u):
"""A-project v onto u such that v*A*u is A-orthogonal.
"""
Au = A @ u
beta = (v @ Au) / (u @ Au)
return beta * u
Notice that if we swapped the function proj for a function that performs the standard projection, we would have the original Gram–Schmidt algorithm. The only difference here is that proj is defined in such a way to ensure that and are -orthogonal rather than orthogonal.
An iterative algorithm
While the “direct” method of CGD is conceptually beautiful, it is actually quite expensive if is large. Observe that the Gram–Schmidt-like process is repeatedly computing the matrix-vector multiplication . Furthermore, the algorithm runs for iterations regardless of the structure of the problem. It may be the case that we get close enough to the minimum in fewer than steps. Ideally, we would early return in this case, but it’s not possible as implemented.
Thus, in practice, CGD does not compute the set explicitly beforehand. Instead, it simply starts out in a direction specified by the initial gradient given an initial position, and then constructs each next direction by ensuring it is conjugate to all previous directions. In other words, we simply merge the Gram–Schmidt like process directly into steepest descent, constructing an -orthogonal basis on the fly. As we’ll see, at each iteration, all but one of the projections are unnecessary, making the algorithm very efficient.
Let’s first look at the basic idea of the iterative approach and then refine it.
Basic idea
Let denote the residual or negative gradient at iteration :
Let denote the direction of the step. At each step, we want to construct a new direction vector such that it is -orthogonal to all previous directions.
We initialize with . This just means that we start by following the negative gradient. At iteration , we want the direction to be conjugate to all the previous directions. Therefore, we subtract the -projections of all previous directions onto a la Gram–Schmidt:
where is the conventional notation for the -projection scalar in Equation ,
Finally, the step we want to take is in the direction of with step size :
The optimal is no longer Equation . Instead, we minimize to get:
I’ll omit this calculation, since we have already done a similar calculation in Equation . Notice that nothing we have done so far should be too surprising. We have just decided that our initial direction vector will be the first residual, and that each subsequent direction will be constructed on the fly from the next residual by subtracting out all -projections of the residual onto the previous direction vectors. This is essentially a Gram–Schmidt process with -projections merged into an iterative steepest descent algorithm.
In Python, this iterative version of CGD can be implement as follows:
def cgd_iter(A, b):
"""Run inefficient conjugate gradient descent to solve x in Ax = b.
"""
dim = A.shape[0]
x = np.random.randn(dim)
xs = [x]
ds = []
for i in range(dim):
# Compute next search direction.
r = b - A @ x
# Remove previous search directions.
projs = 0
for k in range(i):
d_k = ds[k-1]
beta_k = (r @ A @ d_k) / (d_k @ A @ d_k)
projs += beta_k * d_k
d = r - projs
# Take step.
alpha = (r @ d) / (d @ A @ d)
x = x + alpha * d
xs.append(x)
ds.append(d)
return np.array(xs)
At each step, we compute the negative gradient and then subtract out all the previously computed conjugate directions. What is left is a direction that is conjugate to all the previous directions so far. See Figure for this version of CGD on our running example.

However, the algorithm above is still not the iterative CGD typically used in practice. This is because we can make the algorithm far more efficient. Let’s look at two optimizations.
Eliminating matrix-vector multiplications
First, observe that there is a recursive relationship between the residuals (and gradients):
This falls out of the update step for the position vector (Equation ). First, left-multiply the update step by and then subtract each side from
Alternatively, we could have subtracted from each side to get
This is useful because it means that at each iteration, we do not have to compute
Instead, after computing to get , we can simply subtract these from the current value of to get the next residual. This eliminates an unnecessary matrix-vector multiplication. (Steepest descent is typically optimized using an equation similar to Equation to ensure that only one matrix-vector multiplication, , is used per iteration.)
Eliminating projections
The second refinement is avoiding most of the steps in -orthogonalization. In particular, we can prove that
In other words, at each iteration, we simply compute a single coefficient using the previous data. There is no need for an inner for-loop or to keep a history of previous directions. In my mind, Equation is probably the least intuitive aspect of CGD. However, the proof is not that tricky and is instructive for why CGD is so efficient.
First, we need two facts about CGD, two lemmas. The first lemma is that the gradient at iteration is orthogonal to all the previous search directions, that
This is not too surprising if you think about it. We start with an initial gradient, which we follow downhill. We’ve carefully constructed to find the minimum point along the line that is collinear with this gradient, and it makes sense that this minimum point is when the next gradient is orthogonal to the current search direction (Figure again). However, why is the current search direction orthogonal to all previous gradients? This falls out of the recursive relationship between gradients (Equation ). Since the difference between two successive gradients is proportional to , then the term is zero for all . So we can easily use induction to prove Equation must hold. See A1 for a proof.
We needed the first lemma to prove the second lemma, which that each residual is orthogonal to the previous residuals, that
This immediately follows out of the definition of and the previous lemma (see A2).
Finally, we needed the second lemma to prove the main result. Recall the definition of :
We want to prove that when . To do this, we will prove that the numerator is zero under the same conditions, that
To see this, let’s take the dot product of with Equation at iteration :
This allows us to write the numerator of as
When , both dot products between residuals on the right-hand side are zero, meaning that is zero. Finally, when , the numerator of is
So when . The only search direction we need to -orthogonalize w.r.t. is the previous one (when )! As if by magic, all but one of the terms in the Gram–Schmidt-like -orthogonalization disappear. We no longer need to keep around a history of the previous search directions or to -orthogonalize the current search direction with any other search direction except the previous one. As I mentioned above, this is probably the least intuitive aspect of CGD, but it simply falls out of the recursive nature of the updates. It’s a bit tricky to summarize at a high level, and I suggest going through the induction proves in the appendices if you are unconvinced.
Since we have proven that we only need to compute a single coefficient at iteration , let’s denote it with instead of . This gives us
We can show that can be simplified as
This isn’t obvious, but I don’t think it adds much to include the derivation in the main text. See A3 for details. Finally—and this is the final “finally”—let’s redefine as the negative of Equation . Then the final update rule is:
Putting it all together, conjugate gradient descent is
Note that we could early return whenever the residual is small, since it quantifies how good of an estimate is of the true minimum .
In Python, conjugate gradient descent can be implemented as follows:
def cgd(A, b):
"""Run conjugate gradient descent to solve x in Ax = b.
"""
dim = A.shape[0]
x = np.random.randn(dim)
r = b - A @ x
d = r
rr = r @ r
xs = [x]
for i in range(1, dim):
# The only matrix-vector multiplication per iteration!
Ad = A @ d
alpha = rr / (d @ Ad)
x = x + alpha * d
r = r - alpha * Ad
rr_new = r @ r
beta = rr_new / rr
d = r + beta * d
rr = rr_new
xs.append(x)
return np.array(xs)
While this code may look complex, observe that there is only a single matrix-vector multiplication per iteration. All the other operations are scalar and vector operations. If is large, this results in an algorithm that is significantly more efficient than all the other approaches in this post. And ignoring issues related to numerical precision, we are guaranteed to converge in at most iterations.
Conclusion
Conjugate gradient descent is a beautiful algorithm. The big idea, to construct the minimum point from a basis of conjugate vectors, is simple and easy to prove. An iterative algorithm that constructs this conjugate basis on the fly is efficient because we can prove that the next direction vector is already conjugate to all the previous search directions except for the current one. The final implementation relies on only a single matrix-vector multiplication. If this matrix is large, then CGD is significantly faster than gradient descent or steepest descent.
Acknowledgements
I thank Patryk Guba for correcting a few mistakes in figures and text.
Appendix
A1. Proof of orthogonality of gradients and search directions
Let’s prove
The base case, iteration , is
We can actually prove a stronger claim, that
As before (Equation ), this simply falls out of the definition of :
And as before, this is intuitive. Since we have a picked a step size that puts us at the bottom of the parabola described by the intersection of the line-search plane and the quadratic surface (Figure , right), then the next gradient is orthogonal to the previous line search (Figure ).
Now for the induction step. Assume that the claim holds at iteration :
We want to prove that, at iteration ,
In other words, we’re proving that at each subsequent iteration, all new gradients are still orthogonal to . Let’s left-multiply both sides of Equation by :
The left term must be zero because of the induction hypothesis and the right term must be zero because of -orthogonality. Thus, we have proven that each gradient is orthogonal to all the previous search directions so far.
A2. Proof of orthogonality of gradients
Let’s prove
(If this holds for the gradients, it holds for the residuals.) This immediately follows from the lemma in A1 and the definition of :
So the gradient at iteration is orthogonal to all the previous gradients, since these are linear functions of the previous search directions.
A3. Simplification of
Recall the definition of :
We have proven that except when . We want to show that when , the following simplification is true:
We know that the numerator can be written as
when . By Equation , the denominator can be written as
And by the recursive relationship between residuals (Equation ), we rewrite the last line of Equation as
Putting it all together and plugging into Equation , we get:
- Shewchuk, J. R. (1994). An introduction to the conjugate gradient method without the agonizing pain. Carnegie-Mellon University. Department of Computer Science Pittsburgh.