Understanding Positive Definite Matrices
I discuss a geometric interpretation of positive definite matrices and how this relates to various properties of them, such as positive eigenvalues, positive determinants, and decomposability. I also discuss their importance in quadratic programming.
A real-valued matrix is positive definite if, for every real-valued vector ,
The matrix is positive semi-definite if
If the inequalities are reversed, then is negative definite or negative semi-definite respectively. If no inequality holds, the matrix is indefinite. These definitions can be generalized to complex-valued matrices, but in this post, I will assume real numbers.
I know these definitions by rote because the notion of positive definiteness comes up a lot in statistics, where covariance matrices are always positive semi-definite. However, this concept has long felt slippery. I could define and use it, but I didn’t feel like I had any real intuition for it. What do these definitions represent geometrically? What constraints imply that covariance matrices are always positive semi-definite? Why are these matrices featured heavily in quadratic programming? Why is the space of all positive semi-definite matrices a cone? The goal of this post is to fix this deficit in understanding.
This post will rely heavily on a geometrical understanding of matrices and dot products.
Multivariate positive numbers
To start, let’s put aside the definition of positive semi-definite matrices and instead focus on an intuitive idea of what they are.
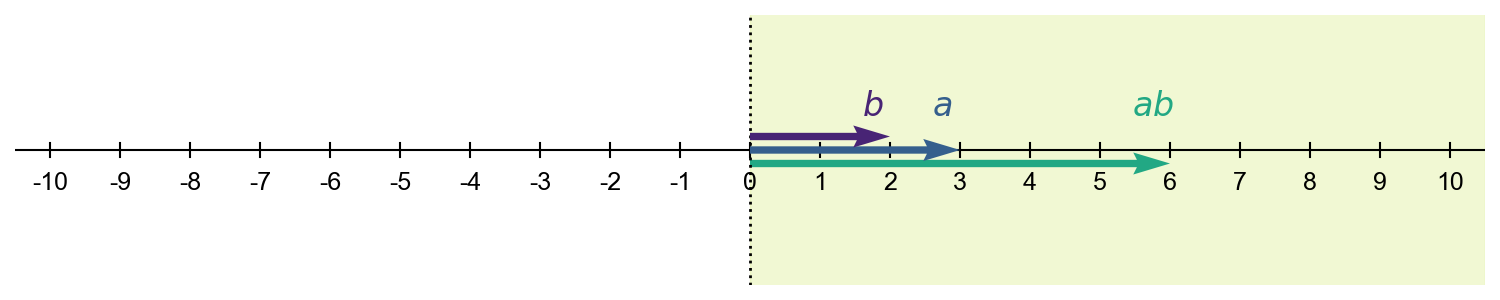
Positive definite matrices can be viewed as multivariate analogs to strictly positive real numbers, while positive semi-definite matrices can be viewed as multivariate analogs to nonnegative real numbers. Consider a scalar . If , then the sign of will depend on the sign of . However, if , then will have the same sign as . We can think about and as -vectors and about the product as a dot product,
When is positive, then will be on the same side of the origin as . So does not “flip” about the origin. Rather, it stretches in the same direction (Figure ).
Analogously, a positive definite matrix behaves like a positive number in the sense that it never flips a vector about the origin . The simplest example of a positive definite matrix is a diagonal matrix that scales a vector in the direction that it already points, and the simplest example of a matrix that is not positive definite is one which simply reverses the vector (Figure ).

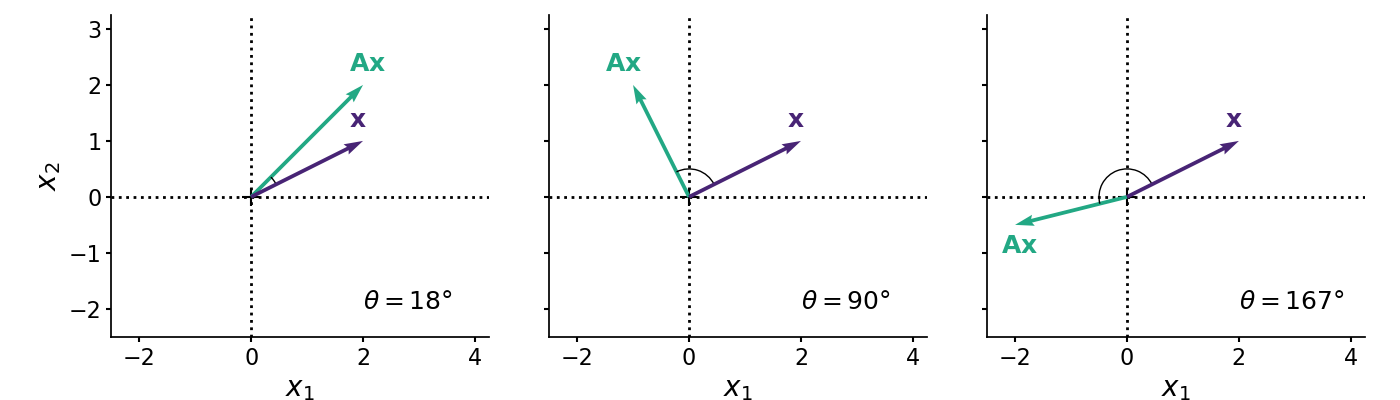
However, it is less clear how to think about scenarios in which a matrix projects a vector in a way that does not simply scale the vector by some constant. For example, does the matrix in the left subplot of Figure flip the vector about the origin or not? What about the matrix in the middle subplot? How can we make these intuitions precise? The answer is in the dot product. The dot product between two -vectors, defined as
can be viewed as vector-matrix multiplication, which in turn can be viewed as a linear projection: an -vector is projected onto a real number line defined by the columns of a matrix . See my posts on matrices and the dot product if this claim does not make sense. Another definition of the dot product is that it is the product of the Euclidean magnitudes of the two vectors times the cosine of the angle between them:
What these definitions imply is that two nonzero vectors and are orthogonal to each other if their dot product is zero,
Why? First, if their dot product is zero and if neither vector is the zero vector, then the cosine angle between the two vectors must be (Figure , middle).
If the dot product between two nonzero vectors is positive,
then both vectors point in a “similar direction” in the sense that the cosine angle between them is less than ; the angle is acute (Figure , left). And if the dot product is negative,
then both vectors point in a “dissimilar direction” in the sense that the cosine angle between them is greater than ; the angle is obtuse (Figure , right).
You can probably already see where we are going with this. One geometric interpretation of positive definiteness is that does not “flip” about the origin in the sense that the cosine angle between and is between and . In other words, and are in the same half of an -dimensional hypersphere (Figure ).
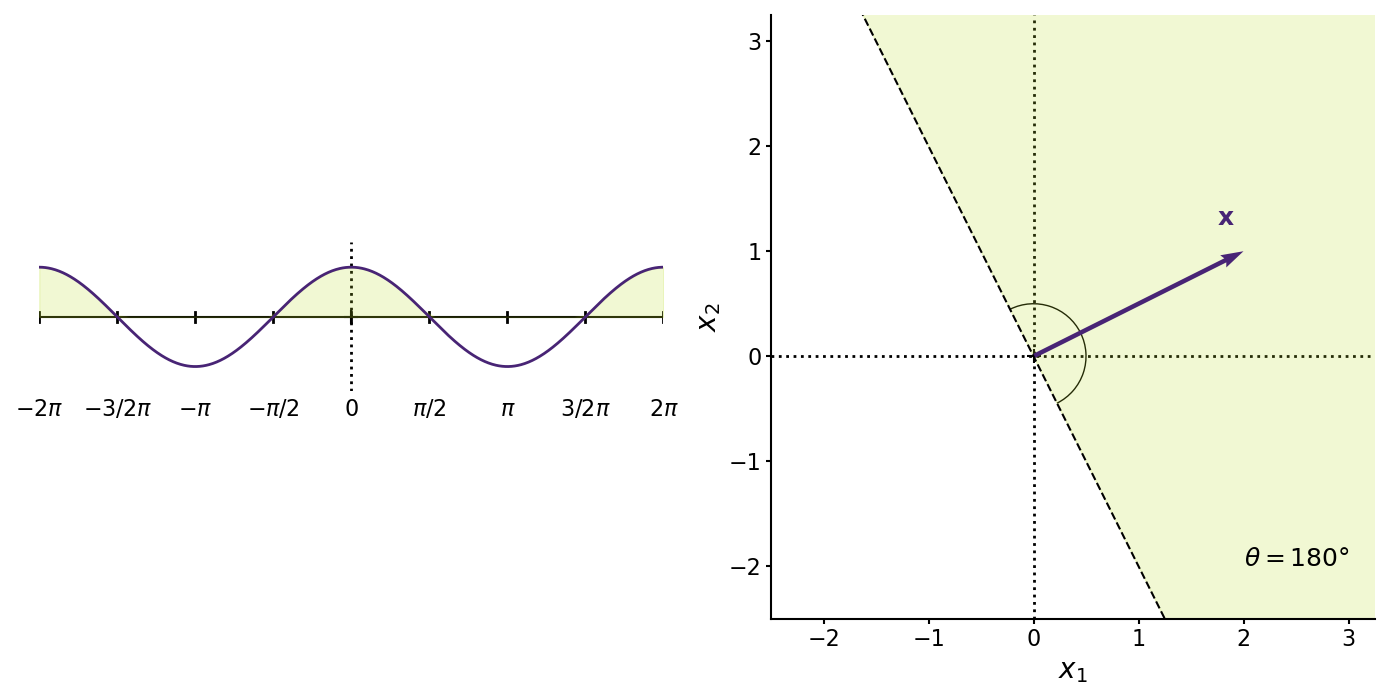
In my mind, Figure captures the geometric interpretation of Equation . It’s a bit easier to see this when we make the location of the dot product operator more explicit, i.e.
(Here, is another common notation for the dot product.) This is similar to defining a real number as a number such that
for any number . To summarize everything so far, an matrix is positive definite if it maps any vector into the same half of an -dimensional hypersphere. Geometrically, this is analogous to a positive number (Figure ).
Examples
Now that we have a definition of and some geometric intuition for positive semi-definite matrices, let’s look at some examples. First, consider the matrix
This is positive semi-definite since
We can see that it would be straightforward to prove that any diagonal matrix with positive elements is positive semi-definite. Since the diagonal elements in a diagonal matrix are the matrix’s eigenvalues, we might wonder if positive semi-definite matrices have nonnegative eigenvalues. Indeed, they do, which we’ll see in the next section.
Next, consider a singular matrix,
This is positive semi-definite since
Thus, a matrix does not need to be invertible to be positive semi-definite. However, we will see in the next section that a positive definite matrix must be invertible. As you might have guessed, this is because positive definite matrices must have strictly positive eigenvalues.
Now let’s look at an example of an indefinite matrix:
This is indefinite since
However, a matrix need not have negative entries to be indefinite. Consider this matrix with only positive values:
Then
Is this quadratic equation always positive? It’s hard to say because it’s not clear if the positive terms will grow faster than the potentially negative term, . (In fact, this matrix is not positive semi-definite because for large enough values of , the quadratic .)
To me, these examples make clear that we need to understand some general mathematical properties that make identifying positive definiteness and positive semi-definiteness easier. Let’s do that now.
Properties
Positive semi-definite matrices have some convenient and important properties that make identifying and working with them relatively easy. I’ll only mention a few that come up often (for me). See (Bhatia, 2009) for a detailed discussion and rigorous proofs.
Eigenvalues. First, a positive definite matrix has strictly positive eigenvalues. Let be an matrix. Recall that the definition of the -th eigenvector with eigenvalue is
We can take the dot product between and both sides of Equation to get
If is positive definite, then clearly . Note that , since this would imply that , which breaks our assumption about . In words, an eigenvector of a matrix is simply scaled by when transformed by (Figure ). Thus, cannot be negative or else could represent flipping about the origin. Note that if is positive semi-definite rather than positive definite, then the eigenvalues are nonnegative rather than strictly positive.
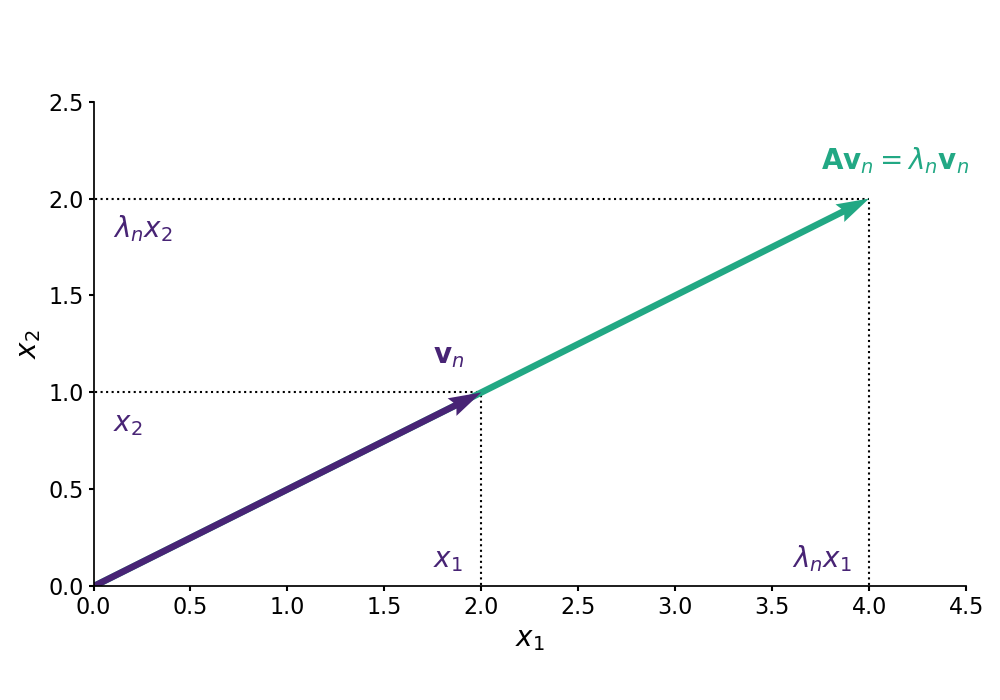
This is geometrically intuitive to me. We can think of the eigenvectors as defining how a matrix maps any vector transformed by the matrix, and the eigenvalues define the sign of each eigenvector. So if a matrix is to behave like a multivariate positive number, then the eigenvalues should be nonnegative so that the “action” of the matrix keeps the vector on the same side of the origin (as defined by Equation and visualized in Figure ).
We now have a straightforward way to verify that the matrix in Equation is not positive semi-definite. It has a negative eigenvalue:
>>> A = np.array([[3, 5], [5, 4]])
>>> eigvals, eigvecs = np.linalg.eig(A)
>>> any(eigvals < 0)
True
We can also easily check that the matrix in Equation is positive semi-definite, since it has nonnegative eigenvalues, but that it is not positive definite, since one eigenvalue is zero.
Determinant. Another way to think about this is via the determinant. Recall that the determinant of a matrix is the product of its eigenvalues,
The geometric intuition for the determinant of an matrix is that it is the signed scale factor representing how much a matrix transforms the volume an -cube into an -dimensional parallelepiped. So if all the eigenvalues of a positive semi-definite matrix are nonnegative, then the determinant of a positive semi-definite matrix is nonnegative. This is just another way of quantifying what we mean by whether or not a matrix “flips” a vector about the origin.
So here is a second check that the matrix in Equation is not positive semi-definite. It has a negative determinant:
>>> A = np.array([[3, 5], [5, 4]])
>>> np.linalg.det(A) # 3*4 - 5*5 = -13
-13.0
Decomposition. Recall that every positive number has two square roots, and . The positive square root is the principal square root, which is typically what is meant when someone refers to “the square root of ”. Analogously, every symmetric matrix is positive semi-definite if and only if it can be decomposed as a product
Thus, is the multivariate analog to the principal square root .
Let’s see why this is true. In the “only if” direction, let . Then
This is similar to an argument that if , then is positive (for real numbers).
In the “if” direction, let be a symmetric, positive semi-definite matrix. Since it is symmetric, it has an eigendecomposition
where is a matrix of eigenvectors. Since is positive semi-definite, all the eigenvalues are nonnegative. Thus, we can use to denote a diagonal matrix, where each element in is the square root of the associated eigenvalue in . Then can be written as
and clearly . This is why a convenient and fast way to construct a positive semi-definite matrix in code is to simply compute for a full-rank matrix .
>>> B = np.random.randn(100, 10) # Construct full-rank matrix B.
>>> A = B.T @ B # Construct positive semi-definite matrix A.
>>> L = np.linalg.cholesky(A) # Verify A is positive semi-definite.
I’m glossing over some finer points about the rank of and the Cholesky decomposition here, but hopefully the main idea is clear.
We can now see why covariance matrices are positive semi-definite. The sample covariance is obviously positive semi-definite using the property above. If is a full-rank design matrix with samples and predictors, then the sample covariance matrix,
is positive semi-definite matrix. We can also prove this is true for the population covariance. Let be a random variable with mean and population covariance
For any non-random vector, , we have
This works because the dot product is commutative. This is a result that is intuitive once we think of positive semi-definite matrices as nonnegative numbers. Since variance is nonnegative, it makes sense that covariance is positive semi-definite. And just as we can take the square root of , we can decompose the covariance .
Quadratic programming
There is a second geometric way to think about positive definite matrices: they are useful for optimization because an equation in quadratic form is convex when the matrix is symmetric and positive definite. Recall that a quadratic equation is any equation that can be written in the following form:
(As we will see in a moment, the coefficients and just make the math a little cleaner for our purposes.) The generalization of a quadratic equation to multiple variables is any scalar-valued function in quadratic form:
What does this quadratic form have to do with definiteness? We will show that if is a symmetric, positive-definite matrix, then in Equation is minimized by the solution to . This a very cool connection. It means that there are two ways of viewing . Let the notation denote the vector that solves . The claim is that
This is fairly easy to prove, but let’s start with some geometric intuition.
First, observe that our claim is true in the univariate case. The first-order necessary condition for optimality is that the first derivative of is zero. We can find the critical points of by taking the derivative of , setting it equal to zero, and solving for :
So satisfies the first-order condition for optimality. But is it a minimum? Let’s assume that , the univariate analog to positive definiteness. Then the second derivative is always positive:
Thus, is a local minimum by the second derivative test. But notice we can make a stronger claim: is a convex function, since for all . So is a global minimum (Figure ).

Now let’s look at the multivariate case. Perhaps you have already guessed what I will write next: just as must be positive for to be the global minimum at , the matrix must be symmetric and positive definite for to attain the global minimum at . Let’s see that. Let be a symmetric and positive matrix. Since it is symmetric, , and the derivative is
See Equation in (Petersen et al., 2008) for the derivative of . So we can see that satisfies the first-order condition for optimality. And since the Hessian is positive definite, ,
then is a local minimum by the second partial derivative test. Finally, we can repeat our stronger claim: since the Hessian of is a positive definite for all , then is a convex function, and is the global minimum.
All that said, the above doesn’t provide much intuition as to why positive definiteness is the key property. Let’s try a different approach, which I found in (Shewchuk, 1994). Suppose that is a symmetric matrix, and let . Let be an “error term” in the sense that it is a random perturbation to . Then
Note that step , we again use the first-order condition for optimality when we replace with . This derivation relies on the fact that when is symmetric, . So if is a positive definite matrix, then . (Clearly, if is positive semi-definite, then .) In my mind, this derivation helps explain why the critical point minimizes when is a positive definite matrix.
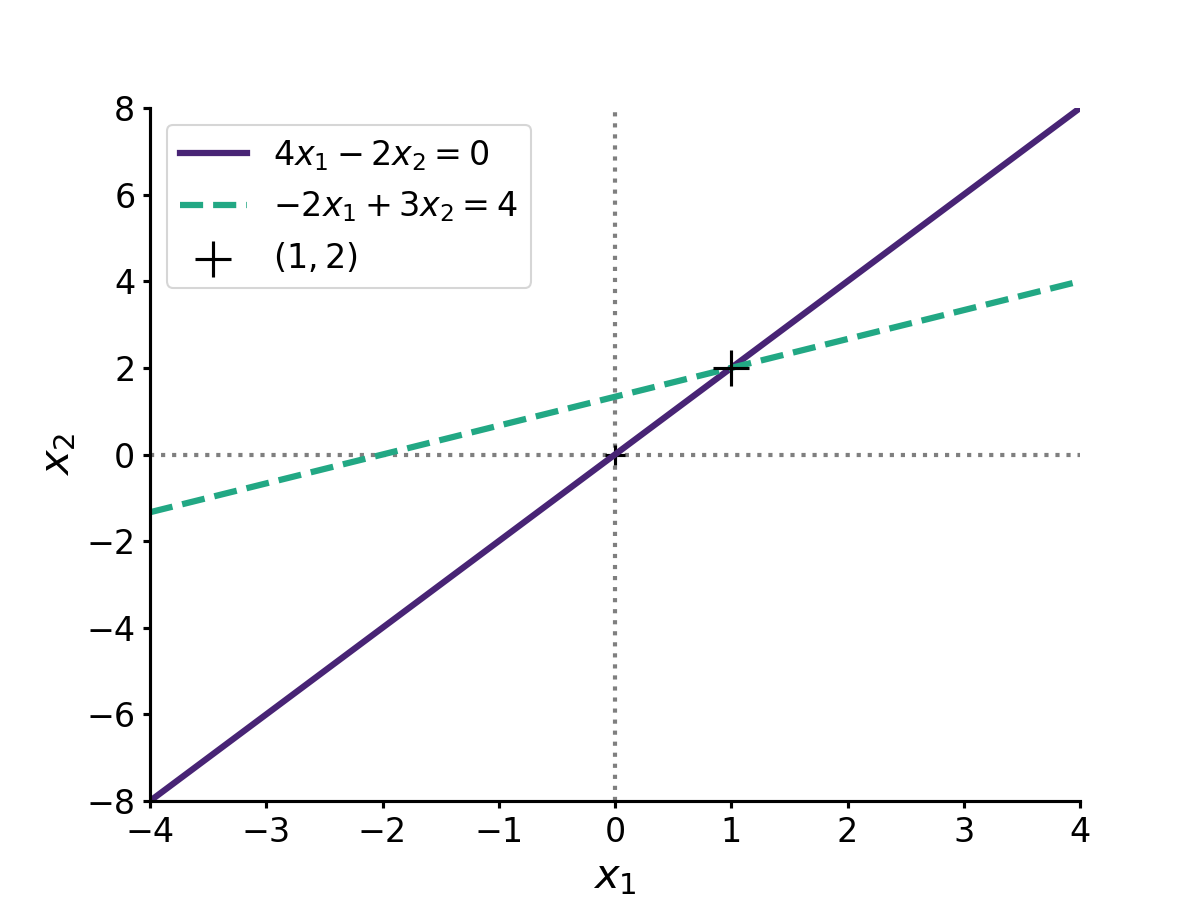
Now that we understand the math, let’s look at an example. Imagine, for example, that the values , and are
We can easily confirm this is positive definite since its determinant is strictly positive. The solution of the linear system is
Geometrically, the solution is just the point where the two linear equations intersect, since this intersection is the point that satisfies both equations (Figure ).
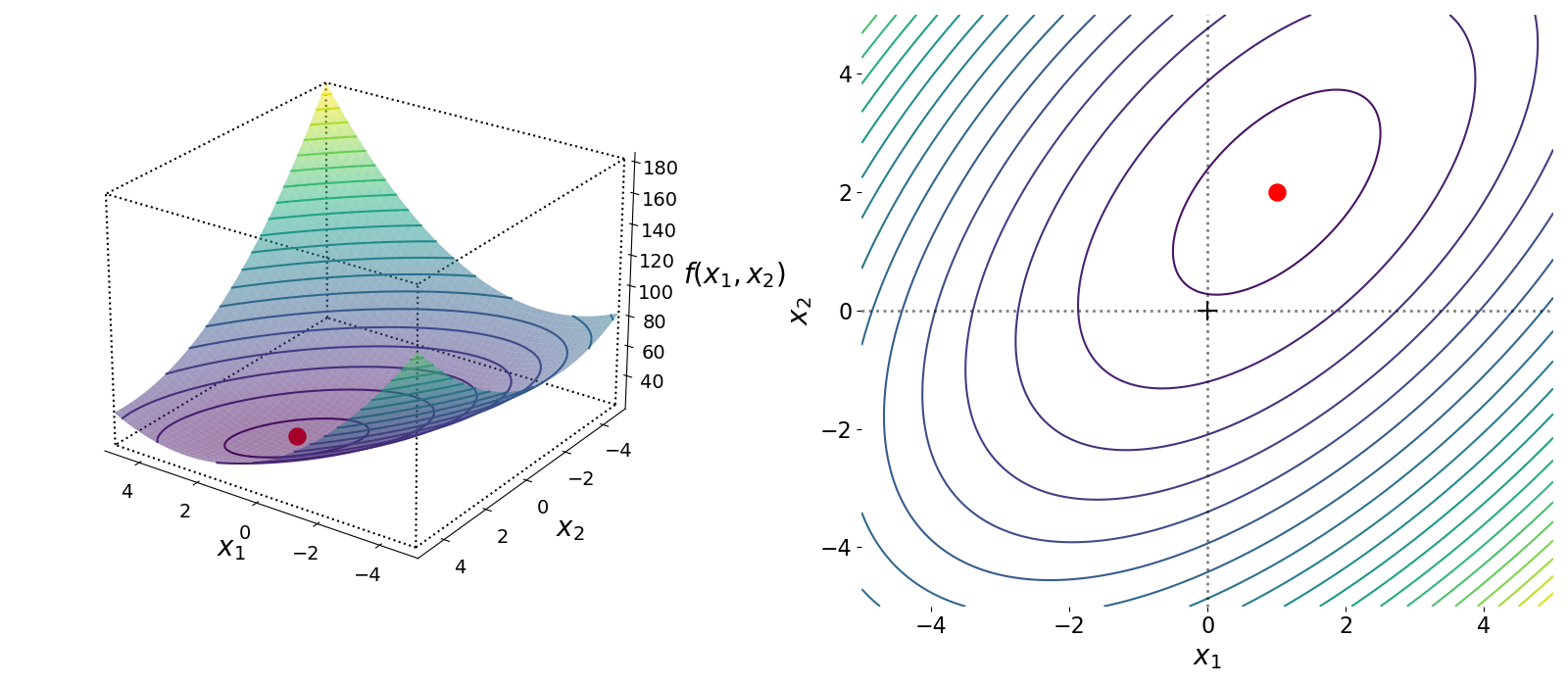
We proved above that this solution is the minimum point for the quadratic form in Equation . We can visualize this function in three-dimensions, , , and where . Geometrically, we can see that Equation is a convex function in three dimensions, and the point is the global minimum (Figure ).
Visualizing definiteness
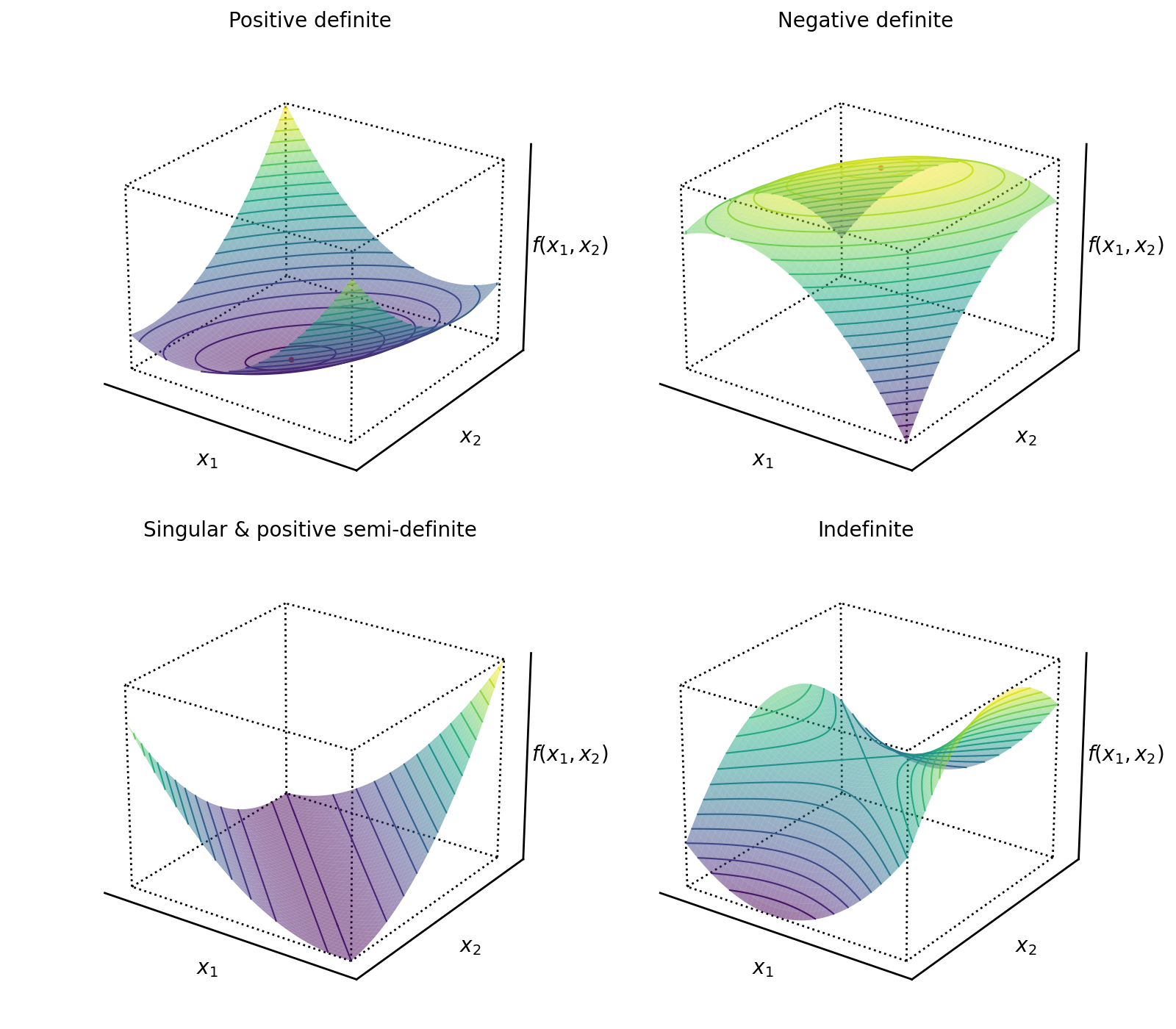
The previous example highlights a useful way to visualize the definiteness or indefiniteness of matrices via the quadratic form in Equation : we can plot the bivariate function
in three dimensions to see how changes for different types of matrices .
The quadratic form of a positive definite matrix is a convex function (Figure , top left). The quadratic form of a negative matrix is a concave function (Figure , top right). The quadratic form of a singular matrix is a function with a “trough”, since the linear system is overdetermined (has multiple solutions) (Figure , bottom left). Singular matrices can be positive semi-definite provided the non-zero eigenvalues are positive. And the quadratic form of an indefinite matrix is a function with a saddle point (Figure , bottom right).
Positive semi-definite cone
As a final note, the class of symmetric positive semi-definite matrices forms a “cone”, sometimes called the PSD cone. Mathematically, this is straightforward easy to see. Let and be two positive semi-definite matrices (not necessarily symmetric), and let and . Then
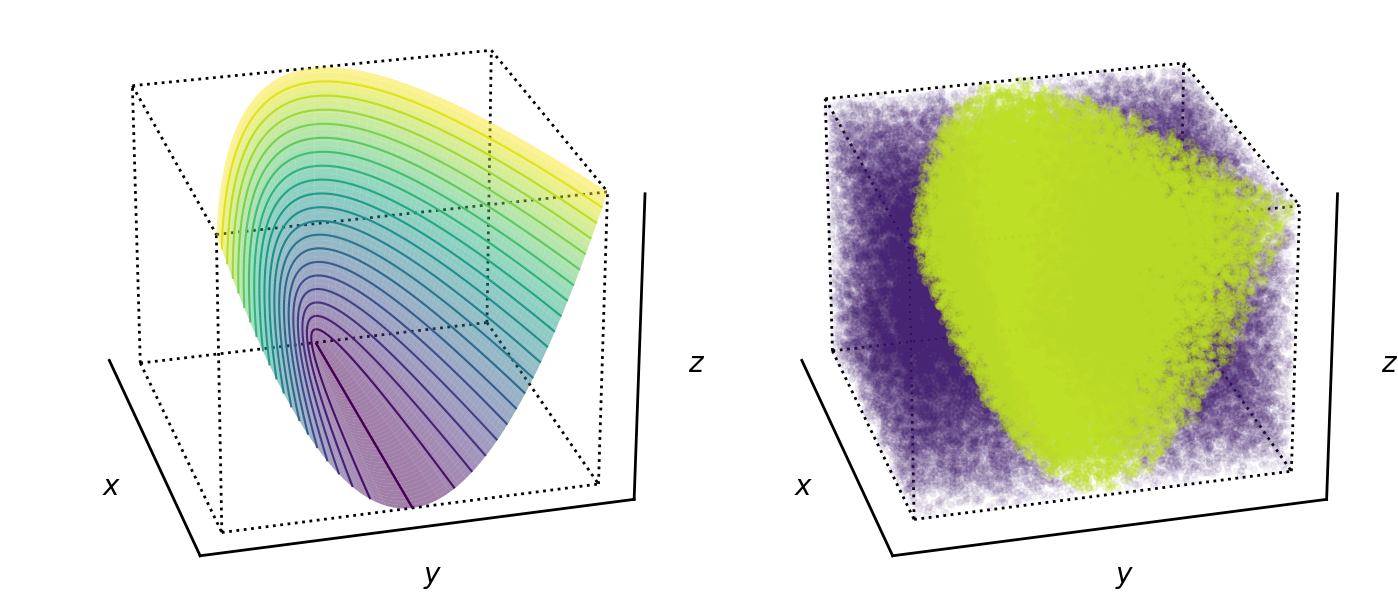
So the convex combination of two positive semi-definite matrices is itself a positive semi-definite matrix. This means that we can think of the space of all positive semi-definite matrices as a convex space. We can even visualize this in three dimensions for a two-dimensional matrix. Consider any arbitrary two dimensional symmetric matrix,
I have not proven it here, but one equivalent definition of a symmetric, positive semi-definite matrix is that all its leading principal minors are nonnegative. At a high-level, this captures the same idea as nonnegative eigenvalues or nonnegative determinant. This amounts to the constraint that
So the surface of the positive semi-definite cone is
i.e. any positive semi-definite matrix will be “inside the cone” in the sense that if we plot its coordinates (as defined by Equation ) using Equation , the location of the point will be inside the surface defined by Equation (Figure ).
Conclusion
An positive definite matrix is analogous to a strictly positive number but in -dimensional space, while a positive semi-definite matrix is analogous to a nonnegative number. This is because positive definite and positive semi-definite matrices transform vectors such that the output vector is in the same half of an -dimensional hypersphere as the input vector. Positive semi-definite matrices have important properties, such nonnegative eigenvalues and a nonnegative determinant. Finally, positive definite matrices are important in optimization because a quadratic form with an positive matrix is a convex function in dimensions
Acknowledgements
I thank for Melih Elibol for providing several detailed suggestions for clarifying this post.
- Bhatia, R. (2009). Positive definite matrices. Princeton university press.
- Petersen, K. B., Pedersen, M. S., & others. (2008). The matrix cookbook. Technical University of Denmark, 7(15), 510.
- Shewchuk, J. R. (1994). An introduction to the conjugate gradient method without the agonizing pain. Carnegie-Mellon University. Department of Computer Science Pittsburgh.