I discuss generalized least squares (GLS), which extends ordinary least squares by assuming heteroscedastic errors. I prove some basic properties of GLS, particularly that it is the best linear unbiased estimator, and work through a complete example.
Published
03 March 2022
Ordinary least squares (OLS), when all its assumptions hold, is the best linear unbiased estimator (BLUE). This is the main result of the Gauss–Markov theorem. However, OLS with heteroscedasticity leads to incorrect and inefficient inference. In particular, the t-statistics are unreliable, and the estimator is no longer BLUE. See this post for a simple example and code.
However, if we do know the covariance structure of our data, we can use generalized least squares (GLS), developed by Alexander Aitken (Aitkin, 1935). The basic idea of GLS is to normalize our data using the known covariance such that the normalized data adheres to the OLS assumptions. We can then apply the OLS estimator, which is BLUE, to these transformed data.
The goal of this post is to walk through GLS in detail. I’ll present the model, an example, and then prove some basic properties.
Aitken’s generalized least squares
In generalized least squares, we assume the following model:
yE[ε∣X]V[ε∣X]=Xβ+ε,=0,=σ2Ω=Σ.(1)
Here, Ω is a positive definite matrix, and we assume it is known. This is called generalized least squares because OLS is just a special case of this model, when Ω=I.
The GLS optimization problem is to minimize the following Gaussian kernel (or Mahalanobis distance):
β^GLS=argβmin{(y−Xβ)⊤Ω−1(y−Xβ)}.(2)
This is different from the OLS optimization problem, which has constant variance which does not effect the optimal coefficients since it can be factored out:
β^OLS=argβmin{(y−Xβ)⊤(y−Xβ)}.(3)
Now we could take the gradient of Equation 2, set it equal to zero, and solve for βGLS. However, in my mind, there is a simpler way. Instead, simply notice that since Ω is a positive definite matrix, it has a matrix inverse which a Cholesky decomposition of the form
Ω−1=LL⊤.(4)
And we can rewrite the Gaussian kernel in Equation 2 as
In other words, the objective with transformed data L⊤y and L⊤X is just the OLS objective, and the transformed errors are homoscedastic,
E[L⊤εε⊤L∣L⊤X]=L⊤E[εε⊤∣L⊤X]L=L⊤(σ2Ω)L=σ2I.(6)
Why does this work? Since the univariate analog to Σ is σ2, then L⊤ is the multivariate analog to 1/σ. In other words, L⊤ represents a linear transformation to our data such that the new data’s variance is normalized.
Furthermore, note that L⊤y and L⊤X adhere to the standard assumptions of OLS: L⊤X is non-random since X is non-random and L is non-random (since Ω is known), L⊤X is full-rank since X is full-rank, and the conditional mean of our observations L⊤y is what we would expect, i.e.
E[L⊤y∣L⊤X]=L⊤Xβ.(7)
So GLS is OLS but with y and X mapped by the linear function L⊤. To make this point clear, it is common to use the following notation:
y∗X∗=L⊤y,=L⊤X,(8)
and to rewrite the GLS objective in Equation 2 as
β^GLS=argβmin{(y∗−X∗β)⊤(y∗−X∗β)}.(9)
Since the OLS estimator,
β^OLS=(X∗⊤X∗)−1X∗⊤y∗,(10)
is BLUE, this implies the GLS estimator, which can just Equation 10 but un-transformed, is also BLUE:
β^GLS=(X⊤LL⊤X)−1X⊤LL⊤y=(X⊤Ω−1X)−1X⊤Ω−1y.(11)
So the GLS estimator is BLUE in the presence of heteroscedastic errors, governed by Ω. The trick was to normalize the data by the known covariance and then apply the OLS estimator to these transformed data.
Example
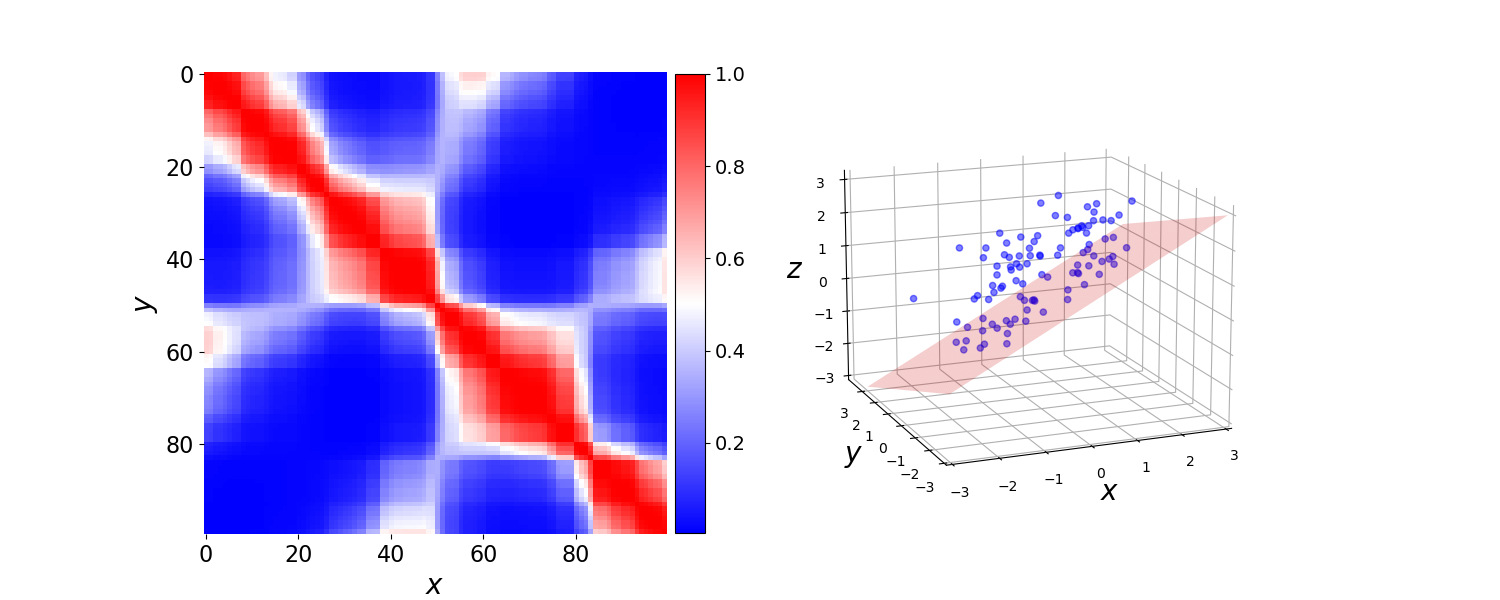
Before discussing GLS any further, let’s look at a simple example of data with heteroscedasticity and show that GLS outperforms OLS on these data. First, let’s construct a positive definite matrix with dependencies between the samples, to break the homoscedasticity assumption for OLS:
This constructs a covariance matrix that is definitely not just spherical errors (Figure 1, left). Then if we assume the error terms are multivariate normal, this implies that our observations are multivariate normal, and we can construct random data (Figure 1, right) as
We can see that the inference is not great. The t-statistics are high, but inferred parameter values are incorrect. For example, the second parameter has a t-statistic over 3 but is off from the true value by roughly 20%.
Figure 1. (Left) Heatmap of covariance matrix for multivariate normally distributed error terms. (Right) 100 samples drawn from y∼N(Xβ,Ω). Red plane is the true hyperplane β=[0.7,−0.3].
Finally, let’s apply GLS rather than OLS to these data, specifying the structure of our noise terms using the sigma argument:
We can see that the inference is improved. The estimated values are correct, and the t-stats are huge. This empirically validates the argument so far. If we know the structure of our error terms, we can still use OLS for efficient inference.
Sampling distribution
Finally, let’s derive some basic properties of GLS.
Unbiasedness. We know that the GLS estimator is unbiased, that
E[β^GLS]=β.(12)
This is because Equation 10 is unbiased, since OLS is unbiased. However, we can also follow the standard derivation for OLS unbiasedness to prove this directly:
where P is the data’s dimension. Of course, we are now assuming Equation 1, meaning the OLS assumptions do not hold. However, we can immediately derive an equivalent estimator since
s2=N−Pe∗⊤e∗(18)
is unbiased, when e∗=y∗−X∗β^. Thus, unbiased estimator of the GLS variance is
When our data have heteroscedasticity and when we know the structure of that heteroscedasticity, we can use generalized least squares. This is just OLS applied to the normalized data. In practice, I suspect that knowing precisely Ω is rare, although perhaps it can be estimated from held out data. Another approach, which I will discuss in a future post, is using estimators of standard errors that are robust to heteroscedasticity.
Aitkin, A. C. (1935). On least squares and linear combination of observations. Proceedings of the Royal Society of Edinburgh, 55, 42–48.