Canonical correlation analsyis is conceptually straightforward, but I want to define its objective and derive its solution in detail, both mathematically and programmatically.
Published
17 July 2018
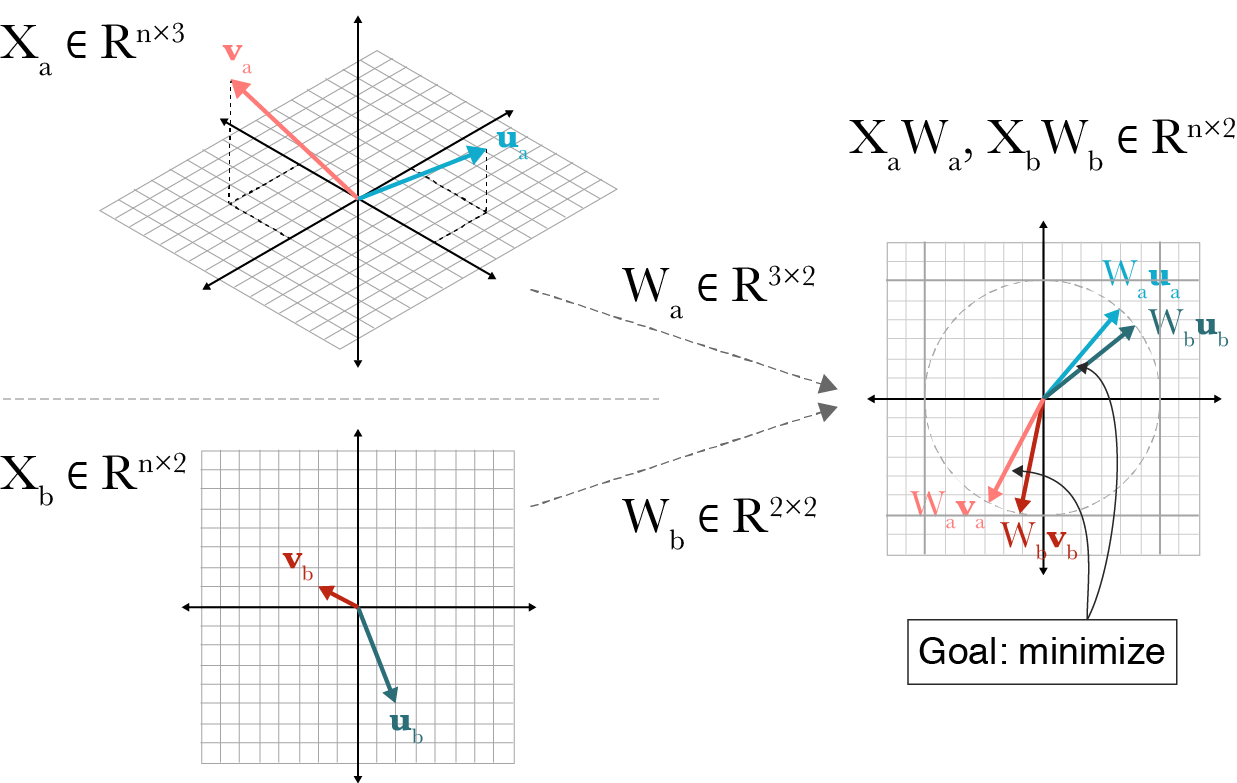
Canonical correlation analysis (CCA) is a multivariate statistical method for finding two linear projections, one for each set of observations in a paired dataset, such that the projected data points are maximally correlated. Provided the data are mean-centered, this procedure can be visualized fairly easily (Figure 1). CCA finds linear projections such that paired data points are close to each other in a lower-dimensional space. And since mean-centered points are vectors with tails at (0,0), CCA can be thought of as minimizing the cosine distance between paired points.
Figure 1: A visualization of canonical correlation analysis. Let n=2 be the number of observations. Two datasets Xa∈Rn×3 and Xb∈Rn×2 are transformed by projections Wa∈R3×2 and Wb∈R2×2 such that the paired embeddings, (va,vb) and (ua,ub), are maximally correlated with unit length in the projected space.
The goal of this post is to go through the CCA procedure in painstaking detail, denoting the dimensionality of every vector and matrix, explaining the objective and constraints, walking through a derivation that proves how to solve the objective, and providing working code.
CCA objective
Consider two paired datasets, Xa∈Rn×p and Xb∈Rn×q. By “paired”, I mean that the i-th sample consist of two row vectors, (xai,xbi), with dimensionality p and q respectively. Thus, there are n paired empirical multivariate observations. We assume the data are mean-centered. See the Appendix, Section 1 for a mathematical discussion of what this means.
Let wa∈Rp and wb∈Rq denote linear transformations of the data (note that these are vectors and not matrices, as in Figure 1; this will be explained). A pair of canonical variablesza∈Rn and zb∈Rn are the images of Xa and Xb after projection, i.e.:
za=Xawazb=Xbwb
The goal of CCA is to learn linear transformations wa and wb such that this pair of canonical variables are maximally correlated. Let Σij denote the covariance matrix between datasets Xi and Xj for i,j∈{a,b}. Then the CCA objective is:
Where the numerator is the cross-covariance of the projected data and the denominator is the standard deviations of the projected data, both in vectorized form. Notice that since the following derivation is true,
I like this formulation because it has a nice geometric interpretation for what is happening. We want projections such that our embedded data are vectors pointing in the same direction in lower-dimensional space (again, Figure 1). See my post on the dot product if the previous statement did not make sense.
There are two additional constraints to the above CCA objective. First, the objective is scale invariant, and therefore the canonical variables za and zb have unit length. See Appendix, Section 2 for a mathematical derivation of why correlation is scale invariant. This further simplifies our objective to:
cosθ=za,zbmax,{za⊤zb}∥za∥2=1,∥zb∥2=1
So far, we have only talked about finding p- and q-dimensional projections to n-dimensional canonical variables. But we can find multiple pairs of canonical variables that satisfy the above objective (we’ll see why later). If we would like to find a second pair of canonical variables, the second constraint is that these must be orthogonal or uncorrelated with the first pair. In general, for the i-th and j-th pair of canonical variables, we have:
zai⊤zaj=0,zbi⊤zbj=0
The number of pairs of canonical variables, call this r, cannot be greater than the minimum of p and q (again, we’ll see why later):
r=min(p,q)
Putting this objective and the constraints in one place, we have:
With this notation, we define the goal of CCA as finding r linear projections, (wai,wai) for i∈{1,2,…r}, that satisfy the above constraints. Now, let’s see how to find these projections.
Solving for the objective
There are multiple ways to solve for the projections wa and wa. I will discuss the one proposed by Hotelling (Hotelling, 1936), which uses the standard eigenvalue problem, solving for eigenvector vi and eigenvalue λi given a matrix A:
Let’s ignore the orthogonality constraints for now. We’ll see in a minute that these are handled by how we solve the problem. We can frame our optimization plus constraint problem using Lagrange multipliers to get:
Where ρ1 and ρ2 are the Lagrange multipliers, which we divide by 2 to make taking the derivative easier. Taking the derivative of the loss with respect to wa, we get:
By the linearity of differentiation, we can compute the derivative as the sum of the terms above. So the wa terms drop out, and we get:
∂wa∂(wa⊤Σabwb)=Σabwb
I won’t work through the other derivatives in the same detail because the reasoning is the same, but you can convince yourself that the derivatives are:
∂wa∂(2ρ1(wa⊤Σaawa−1))=ρ1Σaawa
∂wa∂(2ρ2(wb⊤Σbbwb−1))=0
The derivatives with respect to wb are symmetric. Putting it all together, we get:
∂wa∂L=Σabwb−ρ1Σaawa=0(7)
And for wb, we get:
∂wb∂L=Σbawa−ρ2Σbbwb=0(8)
Now, note that the Lagrange multipliers ρ1 and ρ2 are the same. If we multiply 7 by wa⊤, we get:
The same logic applies if we multiply wb⊤ by 8. Putting these two equations together, we get:
0=wa⊤Σabwb−ρ10=wb⊤Σbawa−ρ2↓ρ1=ρ2
Let ρ=ρ1=ρ2. Now we have two equations, (7) and (8), and three unknowns, wa and wb and ρ. Let’s solve for wa in 7 and then substitute it into 8. First, solving for wa:
We can see that this is the standard eigenvalue problem where λ=ρ2 and A=Σbb−1ΣbaΣaa−1Σab, which implies that wb is an eigenvector that satisfies this equation:
(Σbb−1ΣbaΣaa−1Σab−ρ2I)wb=0
We can solve for wa using (9) after solving for wb.
Now that we know how to solve for the linear projections wa and wb using the standard eigenvalue method, I think a few points make more sense, and I’d like to review them.
n-th pair of canonical variables
In my experience, people typically talk about finding multiple vector projections, each wbr∈Rn, rather than a single matrix projection, Wb∈Rn×r, for the view Xb (and likewise for Xa). This makes more sense once you realize that each eigenvector wbr is a solution to the optimization objective. The final projections Wa and Wb are indeed matrices, but their columns represent different solutions to the same problem.
The number of pairs of canonical variables
Furthermore, this also explains why the number of canonical variable pairs is r=min(p,q), where p and q are the dimensionality of Xa and Xb respectively. Now we can say that r is simply the maximum number of linearly independent eigenvectors. Recall that our matrix A in the characteristic equation det(A−λI)=0 was:
A=Σbb−1ΣbaΣaa−1Σab∈Rq×p
Orthogonality
Finally, we can show that our respective canonical variables are orthogonal to each other. Consider Equations (7) and (8) after rearranging terms and setting ρ1=ρ2=ρ:
Σabwb=ρΣaawa(10)
Σbawa=ρΣbbwb(11)
Consider a new pair of canonical variables, denoted za⋆ and zb⋆ with projections wa⋆ and wb⋆. We want to show that the respective canonical variables are uncorrelated, i.e.:
Now, notice that we can switch the ordering of the canonical pairs. This is because both pairs of canonical variables satisfy the same constraints, namely Equations (10) and (11):
Since the dot product is commutative, we can set (12) equal to (15) and (13) equal to (14). To make it easy on the eyes, I’ve color-coded the same values in the equations below:
ρ(za⊤za⋆)=ρ⋆(zb⋆⊤zb)ρ(zb⊤zb⋆)=ρ⋆(za⋆⊤za)
These equations are both true only when ρ=ρ⋆ or za⊤za⋆=zb⊤zb⋆=0. In words, the correlations among canonical variables are zero except when when they are associated with the same canonical correlation.
Conclusion
CCA is a powerful tool for finding relationships between high-dimensional datasets. There are many natural extensions to this method, such as probabilistic CCA (Bach & Jordan, 2005), which uses maximum likelihood estimates of the parameters to fit a statistical model and deep CCA (Andrew et al., 2013), which uses nonlinear projections, i.e. neural networks, while constraining the outputs of the networks to be maximally linearly correlated. The former has the benefit of handling uncertainty and modeling the generative process for the data using probabilistic machine learning. The latter leverages the rich representational power of deep learning.
Acknowledgements
I relied heavily on Hotelling’s original paper (Hotelling, 1936) and Uurtio’s fantastic survey (Uurtio et al., 2017) while writing this post and implementing CCA.
Appendix
1. Mean-centered data
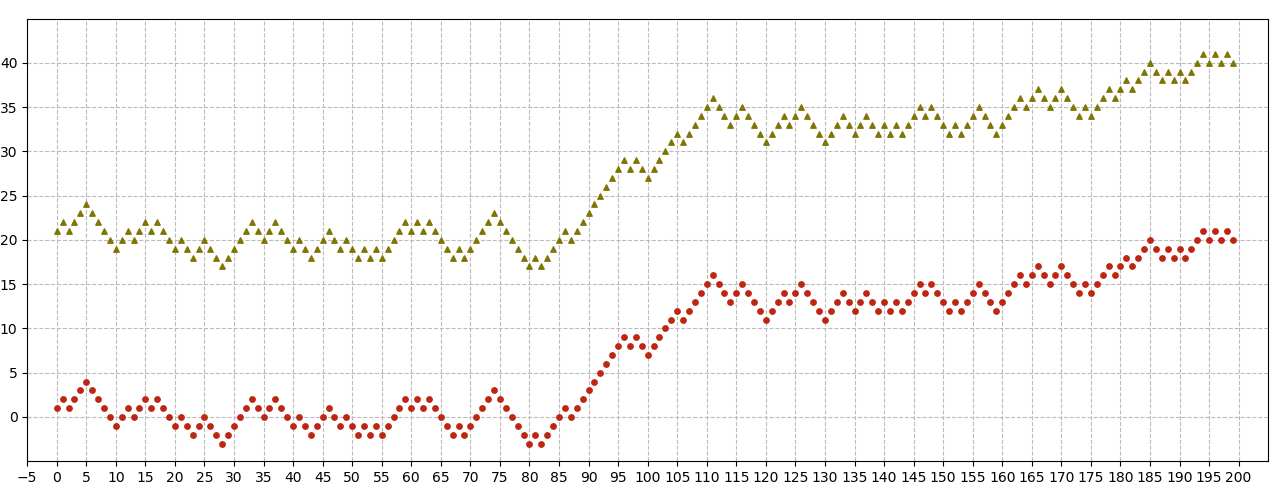
To visualize mean-centering, let’s consider two time series datasets. We can think of time-series data as 1-dimensional, where each time step represents an observation. If two series are identical except for a difference in their y-intercepts (Figure 2), we would expect them to have a correlation coefficient of 1. Note that if their y-intercepts are different, their means will be proportionally different.
Figure 2: Two 1-D time series datasets that are perfectly correlated but have different y-intercepts and therefore different means.
The standard mathematical way to deal with this problem is to subtract the mean from each series. To see why this works, look at what happens mathematically when one series is simply the other series with some additive offset, i.e. y=x+α. First, let’s put the mean of y, μy, in terms of the mean of x, μx:
μy=n∑inxi+α=n∑inxi+nnα=μx+α
Now let’s compute the correlation between x and y:
In words, by subtracting the mean, we allow the series to move up or down without effecting the measure of correlation. If we had an K-dimensional dataset, we would subtract the means from all K dimensions.
2. Scale invariance
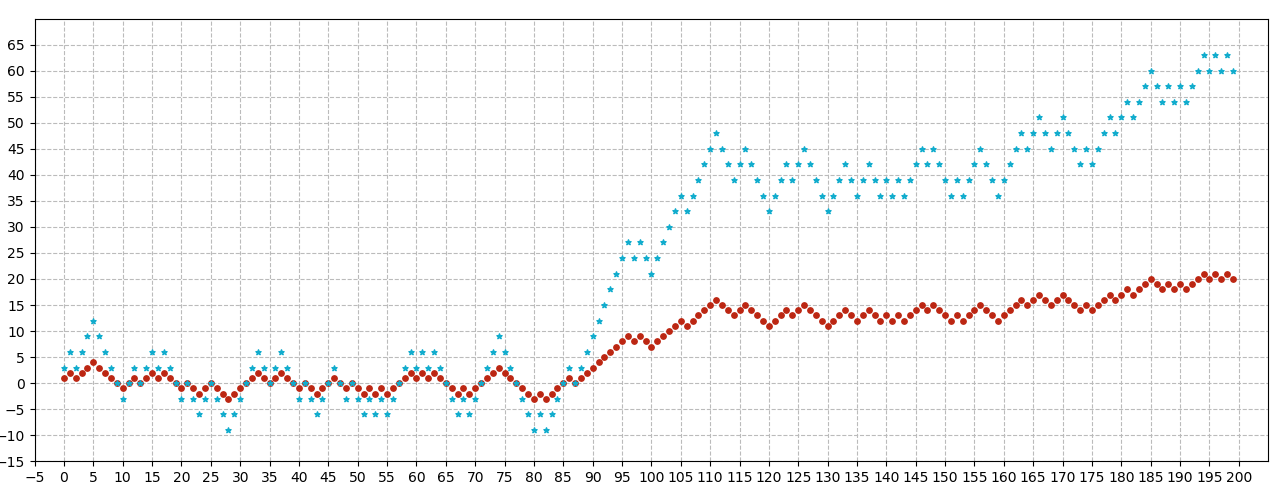
Another important property for correlation is scale invariance. This means that two variables can be perfectly correlated even though one variable changes at a scale that is disproportionate to the other. For example, the two time series in Figure 3 are perfectly correlated.
Figure 3: Two time series that are perfectly correlated. Every value in the red time series is multiplied by 3 to generate the blue series.
We can see this property mathematically by exploring what happens when we compute the correlation between two vectors x and y=αx where α is a scalar. First, let’s again note the mean of y:
In words, y is perfectly correlated with x despite the two series being scaled differently.
3. Code
For completeness, here is the code to solve for wa and wb using Hotelling’s standard eigenvalue problem method. See my GitHub repository for a complete working version.
importnumpyasnp# ------------------------------------------------------------------------------
inv=np.linalg.invmm=np.matmul# ------------------------------------------------------------------------------
deffit_standard_eigenvalue_method(Xa,Xb):"""
Fits CCA parameters using the standard eigenvalue problem.
:param Xa: Observations with shape (n_samps, p_dim).
:param Xb: Observations with shape (n_samps, q_dim).
:return: Linear transformations Wa and Wb.
"""N,p=Xa.shapeN,q=Xb.shaper=min(p,q)Xa-=Xa.mean(axis=0)Xa/=Xa.std(axis=0)Xb-=Xb.mean(axis=0)Xb/=Xb.std(axis=0)p=Xa.shape[1]C=np.cov(Xa.T,Xb.T)Caa=C[:p,:p]Cbb=C[p:,p:]Cab=C[:p,p:]Cba=C[p:,:p]# Either branch results in: r x r matrix where r = min(p, q).
ifq<p:M=mm(mm(inv(Cbb),Cba),mm(inv(Caa),Cab))else:M=mm(mm(inv(Caa),Cab),mm(inv(Cbb),Cba))# Solving the characteristic equation,
#
# det(M - rho^2 I) = 0
#
# is equivalent to solving for rho^2, which are the eigenvalues of the
# matrix.
eigvals,eigvecs=np.linalg.eig(M)rhos=np.sqrt(eigvals)# Ensure we go through eigenvectors in descending order.
inds=(-rhos).argsort()rhos=rhos[inds]eigvals=eigvals[inds]# NumPy returns each eigenvector as a column in a matrix.
eigvecs=eigvecs.T[inds].TWb=eigvecsWa=np.zeros((p,r))fori,(rho,wb_i)inenumerate(zip(rhos,Wb.T)):wa_i=mm(mm(inv(Caa),Cab),wb_i)/rhoWa[:,i]=wa_i# Sanity check: canonical correlations are equal to the rhos.
Za=np.linalg.norm(mm(Xa,Wa),2,axis=0)Zb=np.linalg.norm(mm(Xb,Wb),2,axis=0)CCs=np.zeros(r)foriinrange(r):za=Za[:,i]zb=Zb[:,i]CCs[i]=np.dot(za,zb)assertnp.allclose(CCs,rhos)returnWa,Wb
Note that according to NumPy’s documentation on the eig function, eigenvalues and eigenvectors are not necessarily ordered, hence the ordering using argsort.
Hotelling, H. (1936). Relations between two sets of variates. Biometrika, 28(3/4), 321–377.
Bach, F. R., & Jordan, M. I. (2005). A probabilistic interpretation of canonical correlation analysis.
Andrew, G., Arora, R., Bilmes, J., & Livescu, K. (2013). Deep canonical correlation analysis. International Conference on Machine Learning, 1247–1255.
Uurtio, V., Monteiro, J. M., Kandola, J., Shawe-Taylor, J., Fernandez-Reyes, D., & Rousu, J. (2017). A tutorial on canonical correlation methods. ACM Computing Surveys (CSUR), 50(6), 95.