Some important financial ideas are encoded in the geometry of the efficient frontier, such as the tangency portfolio and the Sharpe ratio. The goal of this post is to re-derive these ideas geometrically, showing that they arise from the mean–variance analysis framework.
Published
09 January 2022
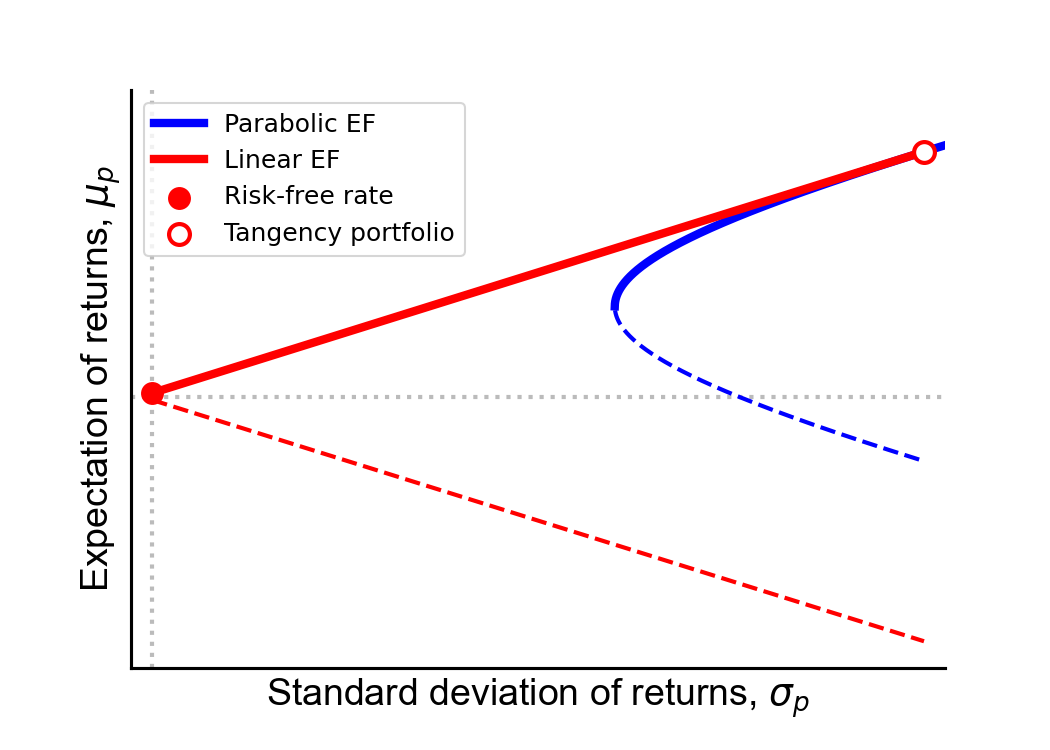
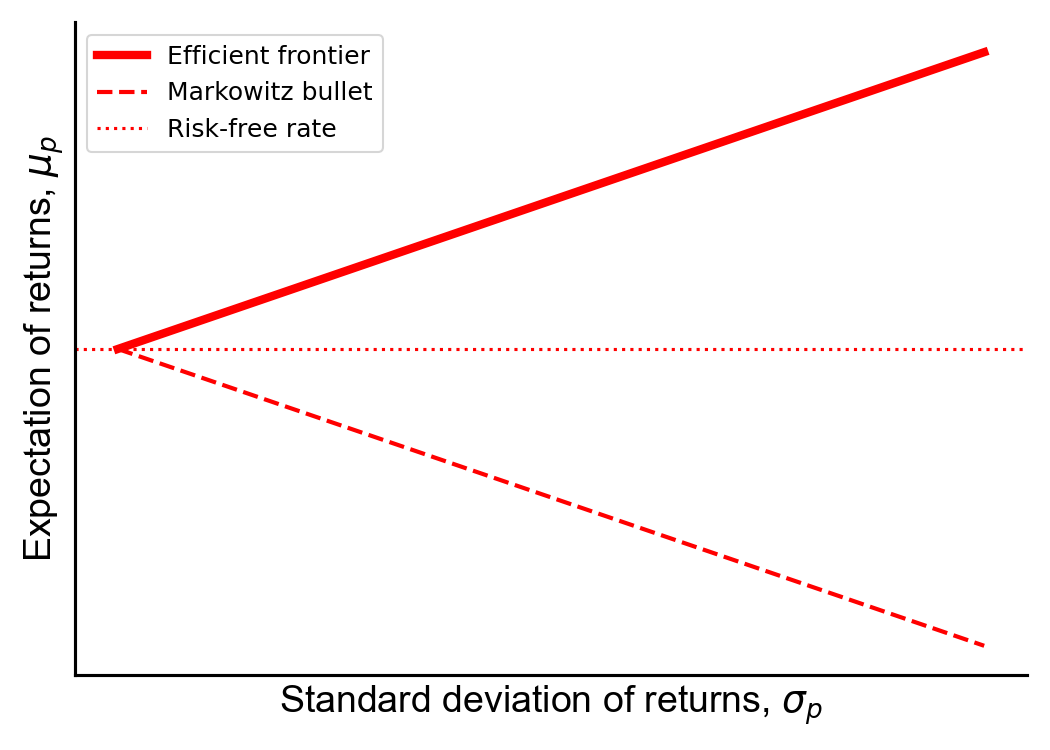
In modern portfolio theory, the efficient frontier is the locus of points {(σp,μp)} corresponding to optimal portfolios, where “optimal” means the lowest risk (standard deviation of the portfolio σp) for the highest reward (expected portfolio return μp). When a portfolio contains only risky (random) assets, the relationship between risk σp and reward μp is quadratic and is typically diagrammed as the Markowitz bullet (Figure 1, dashed blue line) on a risk–return spectrum, with risk on the x-axis and reward on the y-axis. For any given risk σp, there are two portfolios on the hyperbola with different rewards. Clearly, all things being equal, higher reward should be preferred for the same level of risk. Thus, only the top half of the hyperbola is called the efficient frontier (Figure 1, solid blue line).
This nonlinear efficient frontier only applies to portfolios with all risky assets. If we include a single risk-free asset—the canonical example is a United States treasury bill—then the Markowitz bullet becomes piecewise-linear (Figure 1, red dashed line), and the top half is again the efficient frontier (Figure 1, red solid line). For a given level of risk, every portfolio on this linear efficient frontier has a greater or equal expected return to any portfolio on the hyperbolic efficient frontier. The line crosses the y-axis at the rate of return of the risk-free asset, called the risk-free rate (Figure 1, red circle), and the line intersects the efficient frontier at a point called the tangency portfolio (Figure 1, white circle). The tangency portfolio gets its name because the linear efficient frontier is collinear to the tangent line at the point that the two frontiers intersect.
Finally, the slope of the linear efficient frontier is the Sharpe ratio, or the performance of a portfolio in excess of the risk-free rate after adjusting for risk. Put differently, every portfolio on the linear efficient frontier, including the tangency portfolio, has the same Sharpe ratio. Furthermore, this Sharpe ratio is the highest Sharpe possible, i.e. it is the highest expected excess return per unit risk of any portfolio.
Figure 1. The efficient frontier (EF) for risky-only assets (blue) and for a portfolio with risky and one risk-free asset (red). The inefficient frontiers are the dashed lines, since any portfolio above the axes of symmetry have higher expected return for the same risk. The linear efficient frontier is a line between the risk-free rate (red dot) and the tangency portfolio (white dot).
The above three paragraphs make a lot of claims. In many resources discussing modern portfolio theory, mean–variance analysis, or related topics such as the capital asset pricing model, these claims are often made without proof. The reader is expected to know, understand, or simply accept that everything I’ve written above makes sense. The goal of this post is to re-derive these geometric properties for myself.
These questions have already been answered in (Merton, 1972), and this post is, essentially, my notes on that paper. I’ve also relied on these notes by Eric Zivot for some of the matrix algebra required.
Setup and notation
If this section does not make sense, please see my post on mean–variance analysis first.
Suppose a portfolio has N risky assets. Let Rn, a random variable, be the return for the n-th asset. Let’s denote the first moment as μn≜E[Rn], and let’s denote the covariance between Rn and Rm as σnm≜Cov(Rn,Rm). Thus, the variance of Rn is σnn=σn2≜V[Rn]. Finally, let wn denote portfolio weight of the n-th asset. We can pack these symbols into vectors and a matrix as follows:
We assume that the covariance matrix Σ is non-singular, so Σ−1 exists.
A portfolio’s return Rp, also a random variable, is simply an accounting identity,
Rp≜n∑wnRn,(2)
and we can derive it’s mean μp≜E[Rp] and variance σp≜V[Rp] from Equation 2:
μpσp2≜w⊤μ,≜w⊤Σw.(3)
The optimal portfolio weights are defined in the following quadratic programming problem:
wminsubject toandw⊤Σw,w⊤μ=μp,w⊤1=1,(4)
In words, Equation 4 means: minimize the portfolio’s variance subject to the constraints that the portfolio’s expected return is μp and the weights sum to unity. Thus, for a given expected return μp, we can solve the optimization problem for w and then calculate σp2.
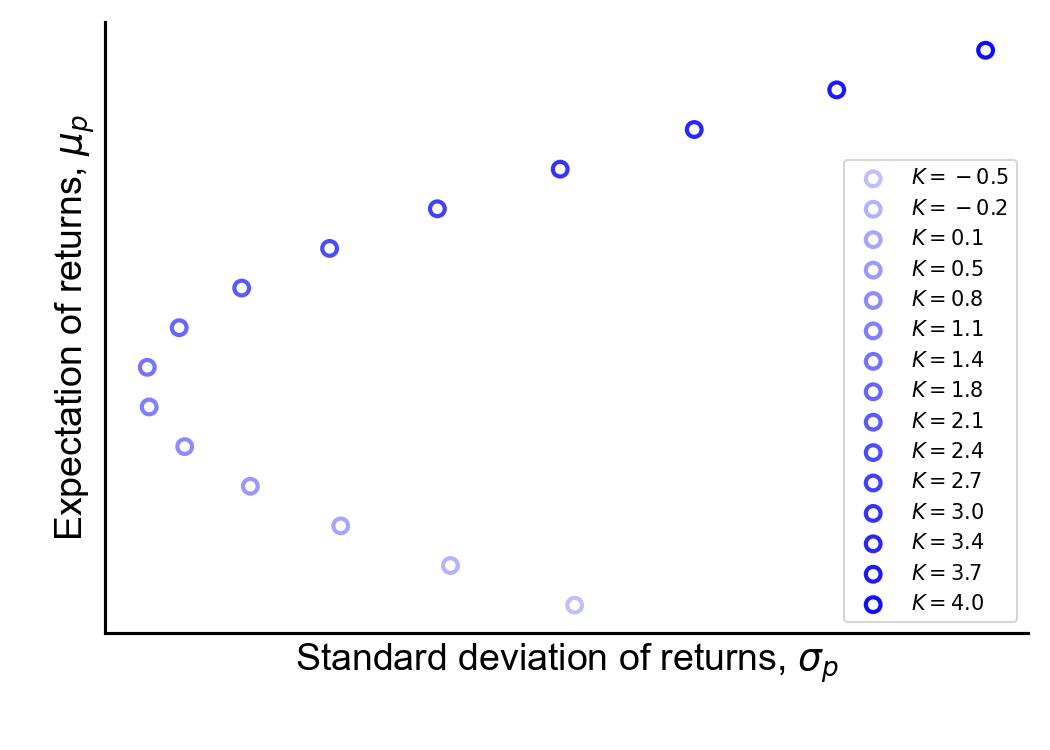
Figure 2. Fifteen portfolios on the efficient frontier, computed numerically using quadratic programming.
The Markowitz bullet is the locus of points {(μp,σp)} that satisfy Equation 4 for all μp, and the efficient frontier is the top half of this bullet.
In Figure 2, I’ve drawn the Markowitz bullet for fifteen different μp values using synthetic expected returns μ and covariances Σ. For each μp, I used SciPy’s minimize function to find the optimal weights w and then solved for σp. (See A1 for code.) Empirically, we can see that the Markowitz bullet is a hyperbola. Now, let’s prove it.
Efficient frontier with only risky assets
First, let’s derive the efficient frontier when our portfolio only contains
risky assets, i.e. when each Rn is a random variable. As we will see, in this
case, the efficient frontier in mean-standard deviation space is a hyperbola because
the portfolio variance σp2 is a quadratic function of the portfolio
mean μp, i.e. the efficient frontier in mean-variance space is a
parabola. We’ll prove this by solving for the optimal weights w using the method of Lagrange multipliers, and then expressing σp2 in terms of these optimal weights.
Solving for optimal portfolio weights
Let’s write Equation 4 using a Lagrangian function:
L(w,λ)=w⊤Σw+λ1(w⊤μ−μp)+λ2(w⊤1−1),(5)
where λ=[λ1λ2]⊤ are Lagrange multipliers. We want to take the derivative of L w.r.t. each wi and each λi, set each equation equal to zero, and solve. In other words, we want to solve
∇w1,…,wN,λ1,λ2L(w,λ)=0.(6)
This is a system of N+2 equations. The gradient of the Lagrangian function is
The derivative of the first term in the top row of Equation 7 is because, in general,
∇xx⊤Bx=(B+B⊤)x,(8)
for a vector x and matrix B. In our case, B=Σ is symmetric. You can easily derive this result yourself by hand or see Equation 81 in (Petersen et al., 2008). The derivatives of the other terms are fairly straightforward.
We can solve for w after setting the first line of Equation 7 to zero:
w=−21λ1Σ−1μ−21λ2Σ−11.(9)
This can be written more compactly as
w=−21Σ−1[μ1][λ1λ2]=−21Σ−1Uλ.(10)
where U is an N×2 matrix, U≜[μ1].
We can solve for λ while adhering to the equation for w by plugging Equation 10 into the second and third lines of Equation 7 after setting these lines equal to zero:
We can simplify Equation 12 by writing it in terms of U, λ, u≜[μp1]⊤, and M≜U⊤Σ−1U:
u=−21U⊤Σ−1Uλ=−21Mλ.(13)
Now we can solve for the λ values which hold for Equation 10:
λ=−2M−1u.(14)
And finally, we can solve explicitly for the optimal weights that give the efficient frontier w by plugging Equation 14 into the second line of Equation 10:
w⋆=Σ−1UM−1u.(15)
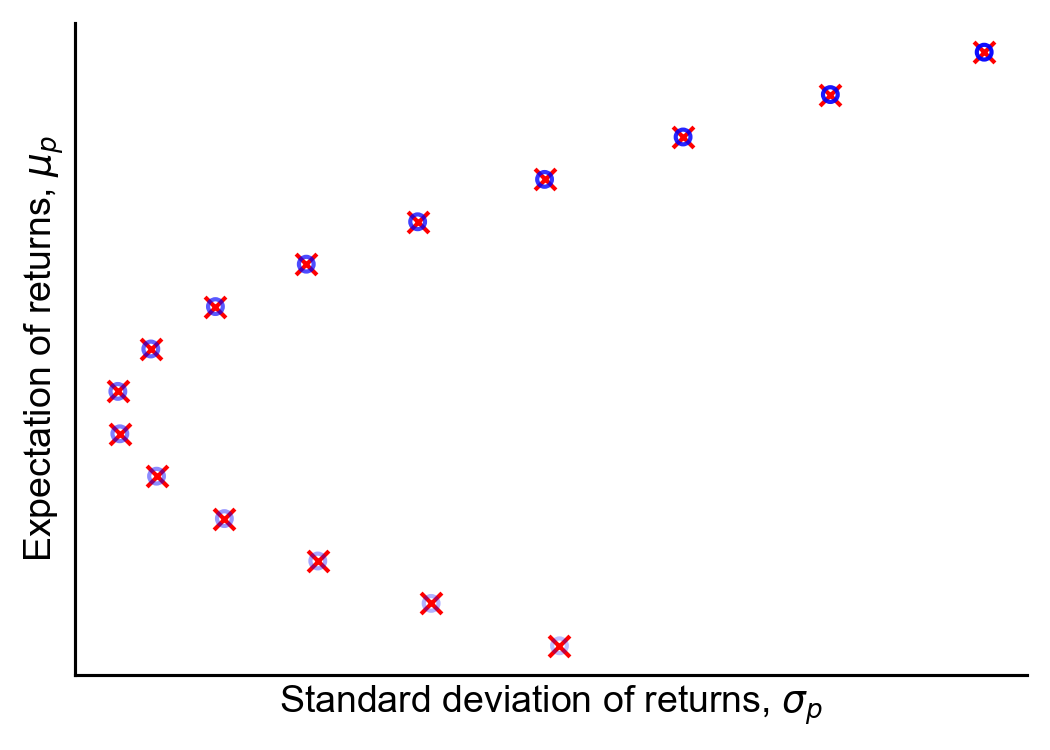
To check that this is correct, I’ve re-created Figure 2 using both numerical minimization of Equation 4 and analytical computation of Equation 15 (Figure 3). (See A2 for code.)
Figure 3. Fifteen portfolios on the efficient frontier, computed numerically using quadratic programming (blue dots) and analytically using Equation 15 (red "x" marks).
Why the Markowitz bullet is a hyperbola
So why is the Markowitz bullet a hyperbola? We can now express the portfolio variance σp2 as a function of its expected return μp (encoded in u):
This is just a vectorized formulation of Equation 12 in (Merton, 1972). To quote Merton on his Equation 12, “Thus, the frontier in mean-variance space is a parabola.” Later, we will find it easier to work with this quadratic equation if we introduce some notation:
Putting it together, we can write μp in terms of σp as
σp=f(μp)=ds11μp2−2s1μμp+sμμ.(22)
And this is just a vectorized formulation of Equation 15 in (Merton, 1972). To quote Merton again, “It is usual to present the
frontier in the mean-standard deviation plane instead of the mean-variance
plane… Figure II graphs [this] frontier which is a hyperbola…” To summarize,
the efficient frontier in terms of (μp,σp2) is a parabola, while
the efficient frontier in terms of (μp,σp) is a hyperbola. And
“Markowitz bullet” typically refers to the frontier in mean-standard deviation
space, i.e. the bullet is a hyperbola. This is a subtle distinction which was
pointed out to me by a reader (see the acknowledgements). See this mathematics StackExchange
post for further discussion.
Anyway, Equation 22 is useful is because now we can use basic properties of quadratic equations for quick computation, such as finding the vertex of the hyperbola (where the efficient frontier starts), taking derivatives, or solving for μp.
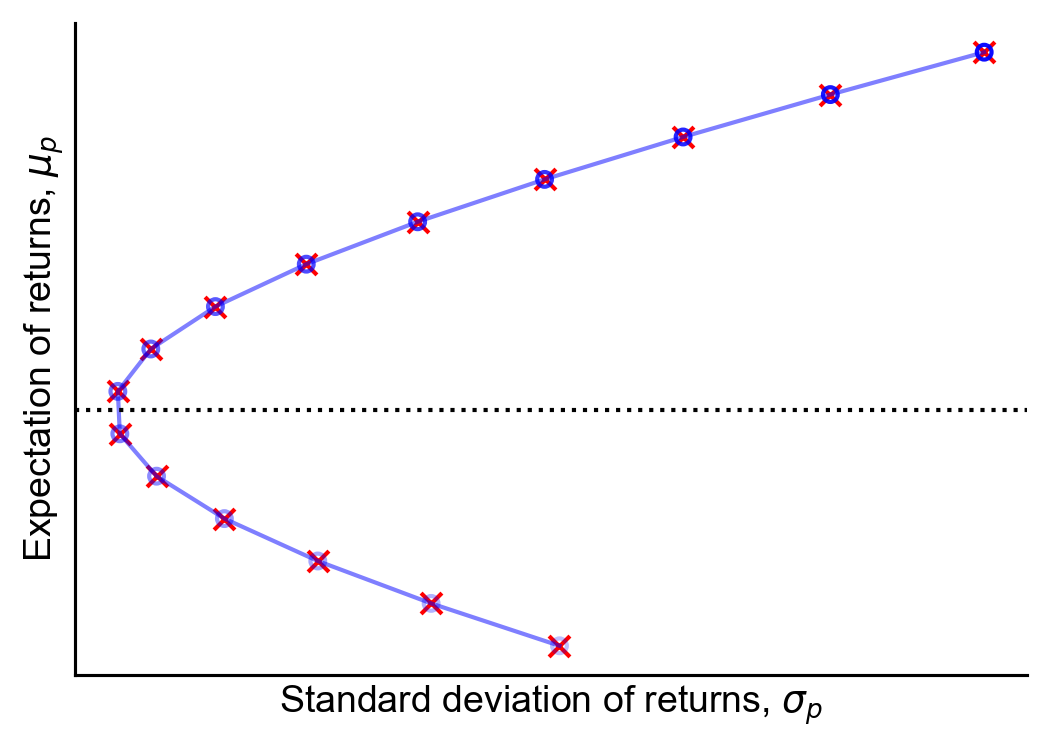
Figure 4. The Markowitz bullet (blue line), visualized by drawing ten thousand portfolios that satisfy Equation 20. Also, fifteen portfolios on the efficient frontier, computed numerically using quadratic programming (blue dots) and analytically using Equation 15 (red "x" marks).
Furthermore, we can easily vectorize the computation required to draw the efficient frontier. Rather than computing the optimal w and then computing σp2, we can simply compute the three scalar coefficients in Equation 22—which do not depend on w—and the normalization term d to compute the correct (minimum) standard deviation σp for any input expected return μp. In Figure 4, I have drawn the Markowitz bullet using this vectorized computation over ten thousand μp values. (See A3 for code.)
Relationship between reward and weights
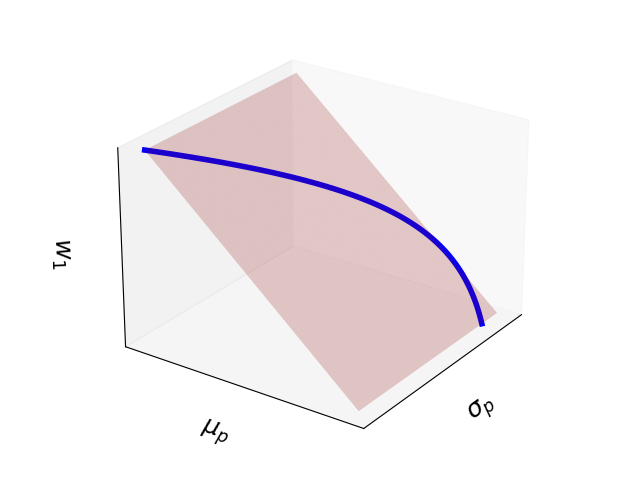
Finally, note that Equation 15 has an important implication. While the relationship between risk and reward is quadratic, the relationship between optimal weights and expected returns is linear. Thus, the Markowitz bullet is just hyperplane in weight-space. To visualize this, I’ve plotted the Markowitz bullet for N=2 assets. When N=2, the two optimal weights are fully specified by w1, since w2=1−w1. Thus, we can plot the Markowitz bullet in 3-dimensional space, with σp, μp, and w1 as the axes (Figure 5).
Figure 5. The Markowitz bullet in 3-dimensional space defined by expected return μp, return variance σp, and optimal weight w1. The bullet is a hyperbola lying on a hyperplane defined by w1.
Intuitively, this makes sense. All this geometry is representing is that, if we want bigger expected returns for our portfolio, we should put more weight on assets with bigger expected returns. However, our risk grows nonlinearly.
Efficient frontier with a risk-less asset
Now that we have proven that the Markowitz bullet with risky assets is a hyperbola, let’s consider the efficient frontier when we include a risk-free asset with return rf (lowercase because non-random). As I mentioned, this is often called the risk-free rate and the canonical example of a risk-free asset is a United States treasury bill. We’ll prove that, in this case, the Markowitz bullet is a piecewise linear function, and that the slope of the top half of this frontier—the efficient part—is the Sharpe ratio. Where the hyperbolic and linear functions intersect is called the tangency portfolio (Figure 1).
Note that we will assume the risk-free rate rf is lower than the y-coordinate of the vertex of the hyperbolic efficient frontier. In other words, we assume that a portfolio of risky assets has higher expected return than the risk-free rate. See Section IV of (Merton, 1972) for a discussion of when this does not hold.
To compute this new efficient frontier, let’s repeat our process from the previous section, but this time, let’s include a risk-free asset. Let wf denote the weight of rf in a portfolio with N+1 assets. Since the portfolio weights sum to unity, we have
w⊤1+wf=1.(23)
The expected return on a portfolio with both risky and risk-free assets can be written as
Since rf is risk-free, we want to minimize our portfolio’s variance, which is still w⊤Σw, while targeting a given expected excess return, which is just the expected return less the risk-free rate,
μp−rf=w⊤(μ−rf1).(25)
We target the excess return because rf is fixed. To simplify things, let’s use the following notation:
μ~μ~p≜μ−rf1,≜μp−rf.(26)
Now the new optimization problem is
wminsubject tow⊤Σw,w⊤μ~=μ~p.(27)
Notice that w⊤1=1 is no longer a constraint. While the portfolio weights must sum to unity, w need not. This is because we can allocate whatever proportion of our portfolio we would like to the risk-free asset. The portfolio variance is unchanged since rf is risk-free. Again, we can solve this using Lagrange multipliers. The Lagrangian is
L(w,λ)=w⊤Σw+λ(w⊤μ~−μ~p).(28)
Again, we can find the first-order conditions by computing the gradient, setting it equal to zero, and following for w in terms of λ. The first-order conditions are
∇wL∂λ∂L=2Σw+λμ~=0,=w⊤μ~−μ~p=0.(29)
As before, let’s solve the first first-order condition for w:
w=−2λΣ−1μ~.(30)
We can then solve for λ while adhering to the definition of w as before:
This time, rather than leaving this as a function of μp, let’s rewrite it as a function of σp, so that we can easily plot it the standard mean–variance axes:
Note that this is Merton’s Equation 35. Clearly, the Markowitz bullet is now a piecewise linear function, and again, the efficient frontier is only the top-half of this bullet (Figure 6).
Figure 6. The Markowitz bullet is a piecewise linear function when a portfolio can contain one risk-less asset. The efficient frontier is the top half of this bullet, a line. The vertex is the risk-free rate.
Notice that the slope of this new frontier with a risk-less asset is the Sharpe ratio:
σpμp−rf=(μ−rf1)⊤Σ−1(μ−rf1).(35)
Thus, we have a geometric interpretation of the Sharpe ratio: it is reward (expected excess return) per unit risk (standard deviation) on the risk–return spectrum. A higher Sharpe is a steeper slope, meaning more reward for the same risk. The right-hand side of Equation 35 is just the Sharpe ratio of any portfolio along the linear efficient frontier.
Sharpe-maximizing portfolio
So all portfolios on the linear efficient frontier have the same Sharpe
(Equation 35). A natural question to ask at this point is: since portfolios on
the hyperbolic efficient frontier have varying Sharpe ratios, which one has maximum Sharpe?
To find this portfolio, we just need to compute
μpmax=argxmax{σpminx−rf},(36)
where σpmin is the minimum variance (Equation 22). We can drop the determinant since it does not depend on x, giving us the following optimization problem:
μpmax=argxmax{s11x2−2s1μx+sμμx−rf}.(37)
Again, we take the derivative, set it equal to zero, and solve for x. The first-order condition is:
Thus, we have shown that the optimal portfolio weights are:
μpmax=s1μ−rfs11sμμ−rfs1μ.(41)
Let’s plug this into Equation 15, since these are the optimal weights for a portfolio on the quadratic efficient frontier. The only place that μpmax appears is in u. Let’s compute just M−1u first, since it is tedious. To be clear, we want to compute
Thus, the portfolio weights which maximizes the Sharpe ratio on the hyperbolic efficient frontier are
wmax≜1⊤Σ−1(μ−rf1)Σ−1(μ−rf1).(46)
Tangency portfolio
Now let’s derive the weights of the portfolio that sits at the intersection of hyperbolic and linear efficient frontiers. This is called the tangency portfolio, and we’ll see why in the next section. The point for this section is that the tangency portfolio has the same weights as in Equation 46, i.e. the tangency portfolio maximizes the Sharpe ratio.
By definition, the tangency portfolio is fully invested in risky assets and has no stake in rf. But since it has the weight wf, it must sit at the intersection of the hyperbolic and linear efficient frontiers. Let ω denote this (N+1)-vector of weights:
ω=[wwf].(47)
So while ω⊤1=1, we know that wf=0. Thus, we can use the result from Equation 32 to write:
1=1⊤ω=1⊤w=μ~p(μ~⊤Σ−1μ~1Σ−1μ~),(48)
which implies
μ~p=1Σ−1μ~μ~⊤Σ−1μ~.(49)
Equation 49 is a closed-form solution for the expected excess return of the tangency portfolio. And we can plug this excess return back into our equation for the portfolio weights (again Equation 32) to get
Here, I’ve written wtp to emphasize that this derivation only holds if we assume wf=0, i.e. that these weights are the tangency portfolio. And we see that these weights wtp are equal to the weights wmax for the Sharpe-maximizing portfolio.
Tangent line at tangency portfolio
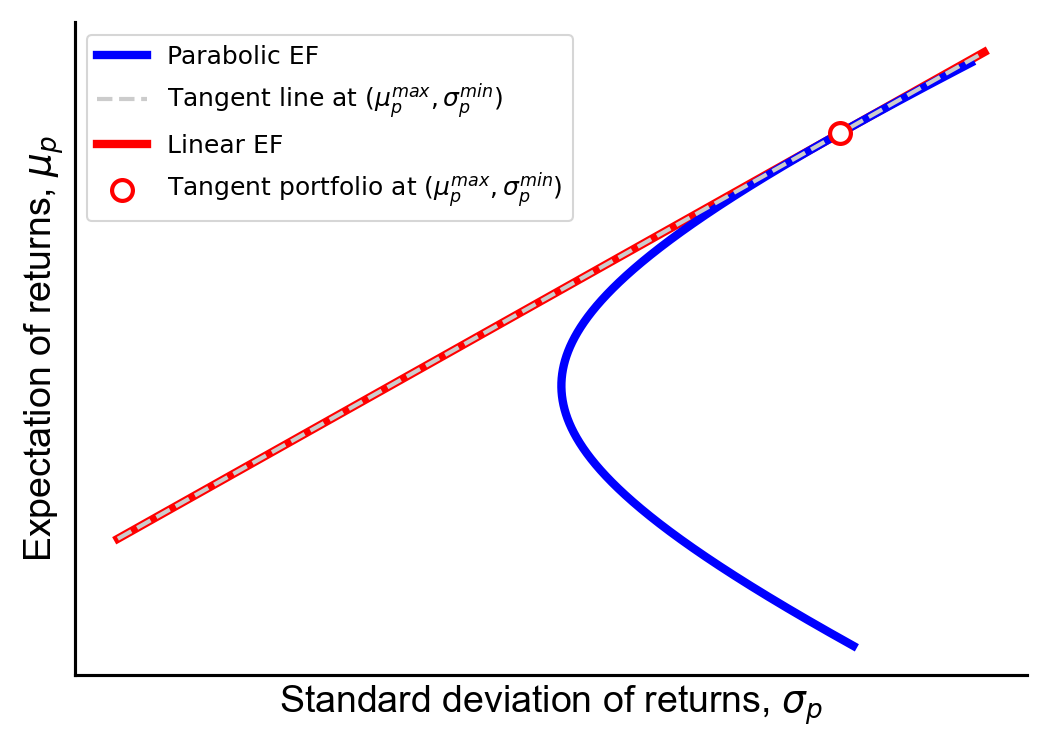
Finally, let’s see why the tangency portfolio has the name it does. We will compute the tangent line at the tangency portfolio and show that its slope is equal to the slope of the linear efficient frontier (Figure 7). This will prove that the two lines (the linear EF and the tangent line at the tangency portfolio) are collinear, since we already know that the tangency portfolio is on the linear efficient frontier.
Figure 7. The tangent line at the tangency portfolio (μpmax,σpmin) has a slope equal to the slope of the linear efficient frontier (EF). This point is the intersection of the hyperbolic and efficient frontiers.
Let’s see that the slope of the tangent line at (μpmax,σpmin) is indeed Equation 35. To find the slope of the tangent line of a function
y=f(x)+b(51)
at a point (x1,y1), we need to compute the derivative at x1, i.e. compute f′(x1).
The derivative of Equation 23 is
f′(μ)=d(s11μ2−2s1μμ+sμμ)s11μ−s1μ.(52)
To find the slope of the tangent line at the tangency portfolio, we simply plug in μpmax. For simplicity, since the derivations are tedious, let’s call this optimal value x. Then we have
We can see here that the denominator in Equation 54 will cancel with the denominator in Equation 55. So we only need to simplify the numerator in Equation 55. This is
And this is the slope of the linear efficient frontier (Equation 35).
Conclusion
To summarize, we have proven the geometric facts implicit in Figure 1. When only considering risky assets, the Markowitz bullet is a hyperbola because the portfolio variance is a quadratic function of the portfolio’s expected return. When also considering a risk-free asset whose rate of return is less than the expected return of any portfolio on the hyperbolic frontier, the Markowitz bullet is a piecewise linear function with a vertex at the risk-free rate.
Put differently, any portfolio on the linear efficient frontier has the same Sharpe and this Sharpe is optimal! While I didn’t discuss this here, this idea is closely related to the mutual fund separation theorems in (Merton, 1972). The tangency portfolio sits at the intersection of these two efficient frontiers and has maximum Sharpe out of all risky portfolios. We call it the “tangency portfolio” because the tangent line at this vertex is collinear with the linear efficient frontier. Thus, holding a single risk-free asset or holding the tangency portfolio—or any linear combination of the two—have the same Sharpe ratio. However, the tangency portfolio has a higher expected return.
In a future post, I’ll discuss the capital asset pricing model (CAPM). As I understand it now, the main argument of the CAPM is that the tangency portfolio must be the market portfolio, or a portfolio that holds assets in proportion to the market. Thus, the CAPM argues that the market is “efficient” in the sense that it has maximum return per unit risk.
Acknowledgments
Thanks to Christopher Jordan-Squire and Đồng Khau Tú for pointing out mistakes
in this post. In particular, Christopher observed that the efficient frontier
in mean-standard deviation space is a hyperbola, not a parabola.
Appendix
A1. Solving for w numerically
defget_ef_port_numerically(rets,covm,targ):"""Solve for the efficient frontier weights for a given expected return
vector `rets`, covariance matrix `covm`, and expected portfolio return
`targ`.
"""defobjective(weights):returnweights.T@covm@weights-targ*rets.T@weightsnorm_constraint=lambdaweights:1-weights.sum()targ_constraint=lambdaweights:np.dot(rets,weights)-targresp=minimize(objective,x0=np.random.dirichlet([1]*len(rets)),method='SLSQP',bounds=[(-2,2)]*5,constraints=[{'type':'eq','fun':norm_constraint},{'type':'eq','fun':targ_constraint}])weights=resp.xreturnweights
A2. Solving for w analytically
defget_ef_port_analytically(rets,covm,targ):"""Solve for the efficient frontier weights for a given expected return
vector `rets`, covariance matrix `covm`, and expected portfolio return
`targ`.
"""N=rets.shape[0]u=np.array([targ,1])[:,None]U=np.vstack([rets,np.ones_like(rets)]).Tcovm_inv=np.linalg.solve(covm,np.eye(N))M=U.T@covm_inv@UM_inv=np.linalg.solve(M,np.eye(2))weights=covm_inv@U@M_inv@ureturnweights
A3. Solving for σp2 directly from μp
defget_sigma_from_mu(rets,covm,means):"""Solve for portfolio variances `vars_` for every value in a vector
`means`, given expected return vector `rets` and covariance matrix `covm`.
"""N=len(rets)ones=np.ones_like(rets)covm_inv=np.linalg.solve(covm,np.eye(N))a=ones.T@covm_inv@onesb=ones.T@covm_inv@retsc=rets.T@covm_inv@retsd=a*d-b*cvars_=(1/d)*np.sqrt(a*means**2-2*b*means+c)returnvars_
Merton, R. C. (1972). An analytic derivation of the efficient portfolio frontier. Journal of Financial and Quantitative Analysis, 7(4), 1851–1872.
Petersen, K. B., Pedersen, M. S., & others. (2008). The matrix cookbook. Technical University of Denmark, 7(15), 510.