Bayesian Online Changepoint Detection
Adams and MacKay's 2007 paper, "Bayesian Online Changepoint Detection", introduces a modular Bayesian framework for online estimation of changes in the generative parameters of sequential data. I discuss this paper in detail.
Introduction
Given sequential data such as stock market prices or streaming stories in a newswire, we might be interested in when these data change in some way, such as a stock price falling or the document topics shifting. If we view our data as observations from a generative process, then we care about when the generative parameters change. An abrupt change in these parameters is called a changepoint, and changepoint detection is the modeling and inferring of these events.
The goal of this post is to explain Ryan P. Adams and David J.C. MacKay’s technical report on Bayesian online changepoint detection (Adams & MacKay, 2007) in my own words, and to work through the framework and code for a particular model. While I focus my discussion on Adams and MacKay’s paper, (Fearnhead & Liu, 2007) is a similar model for the same problem, and it is worth reading as a comparison.
Understanding this post will require understanding conjugacy and the exponential family. The example implementation requires understanding Bayesian inference for the Gaussian.
Model
Let denote the -th observation in a data sequence, and let denote the sequence for . We assume that our data points can be partitioned such that the data within each partition are i.i.d. samples from some distribution; this is the product partition model (Barry & Hartigan, 1992). Formally, let denote the generative parameters for partition and denote the hyperprior. Then are i.i.d. for partitions (Figure ).
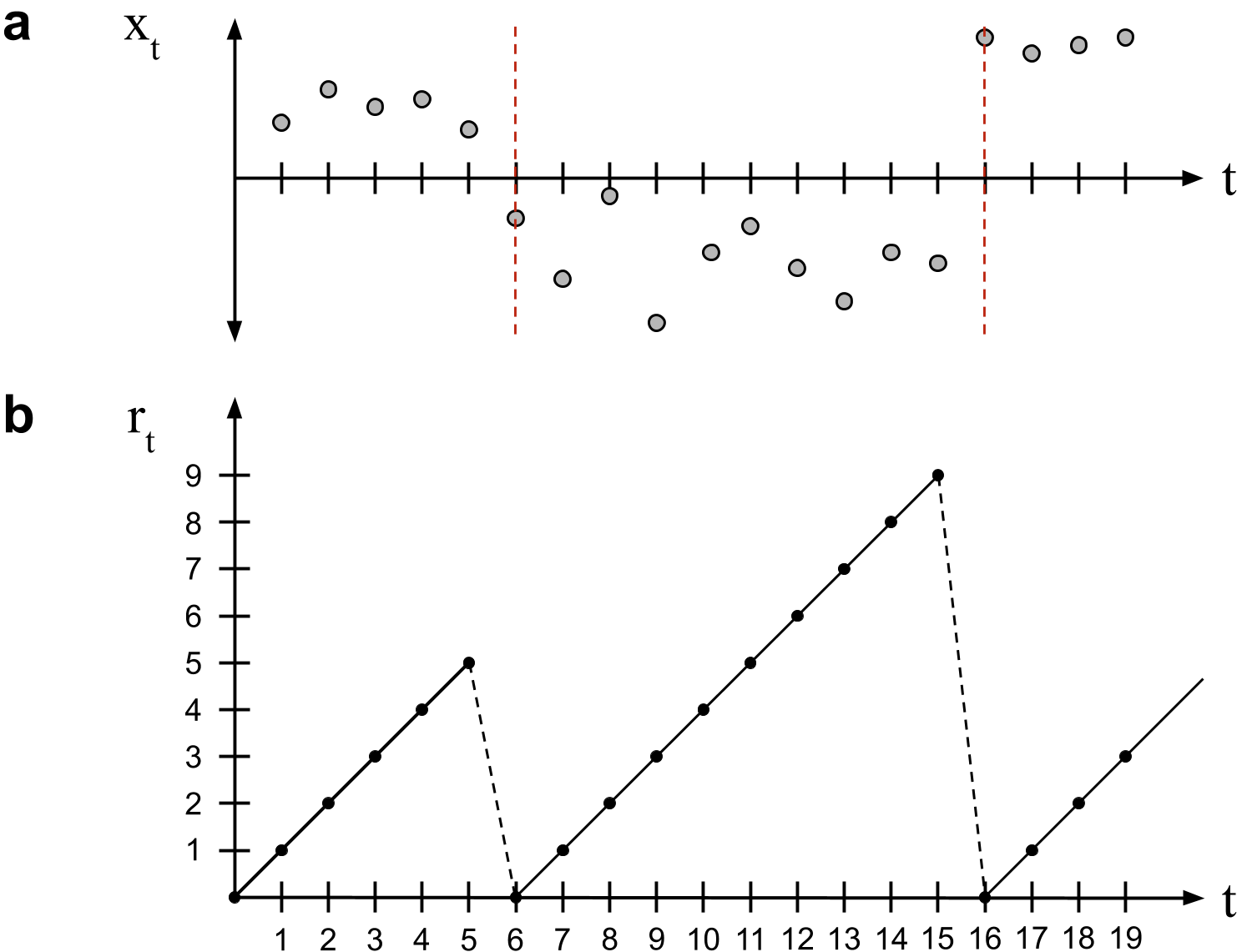
Bayesian online changepoint detection works by modeling the time since the last changepoint, called the run length. The run length at time is denoted . Logically, it can take one of two values,
In words, the run length only ever increases by one or drops to zero (Figure ). The transition probabilities are modeled by the changepoint prior , which is the assumption that is conditionally independent of everything else given .
Ultimately, we want to infer both the run-length posterior distribution and the posterior predictive distribution so that we can predict the next data point given all the data we have seen so far.
Recursive RL posterior estimation
In Bayesian inference, if is a set of i.i.d. observations and are model parameters, then the posterior predictive distribution over a new observation is
In words, we weigh our probabilistic model’s predictions by our posterior uncertainty of the model’s parameters. Marginalization means doing this for every possible parameter value. In Bayesian online changepoint detection, this posterior takes a slightly different form. The posterior predictive is the probability of the next data point, , given the observations so far, , and it is computed by marginalizing out the run length ,
We use to denote all observations associated with . If this is confusing, think of as a hypothesis that a changepoint occurred time steps ago. Thus, only data within the past time points should contribute to our predictive distribution over . This notation is a little sloppy, and we could write equation more explicitly as
While Adams and MacKay refer to the term analogous to “model” as a “marginal predictive”, I will use underlying probabilistic model (UPM) predictive to clearly disambiguate it from other predictives in this discussion. In the next section, we will see how to efficiently compute this term. For now assume that it is straightforward.
If we can compute the UPM predictive, then we just need to compute the RL posterior, which is proportional to the joint,
We can write this joint recursively as
The first two steps are just marginalization and the chain rule. However, the third step is trickier because it only holds if our modeling assumptions are made. Both of these equations
fall out of our modeling assumptions. Summarizing and annotating the derivation, we have
We now have a recursive algorithm for computing the RL posterior. The algorithm is recursive because after we compute the joint distribution , we can forward message-pass this distribution’s mass to the calculation for . Of course, a recursive algorithm must define its initial conditions (what is ?), and we will address this later.
As an aside, when I first read the paper, Equation seemed as if it arose ex nihilo. In my mind, the authors dreamed up , knew to marginalize out , and voilà! a recursive algorithm. In fact, Equation is similar to the forward algorithm for hidden Markov models. In this context, is the latent variable, and there are no generative parameters. Wikipedia’s derivation is quite clear; for stable reference, consult either (Bishop, 2006) or (Murphy, 2012).
It is useful to think about this recursive algorithm visually. Borrowing language from the paper, we can visualize the message-passing algorithm as living on a trellis (Figure ). At each time point, mass is either passed “upward” such that the run-length is incremented or “downward” where it is truncated to zero. At each time point , the discrete RL posterior distribution has support over values.
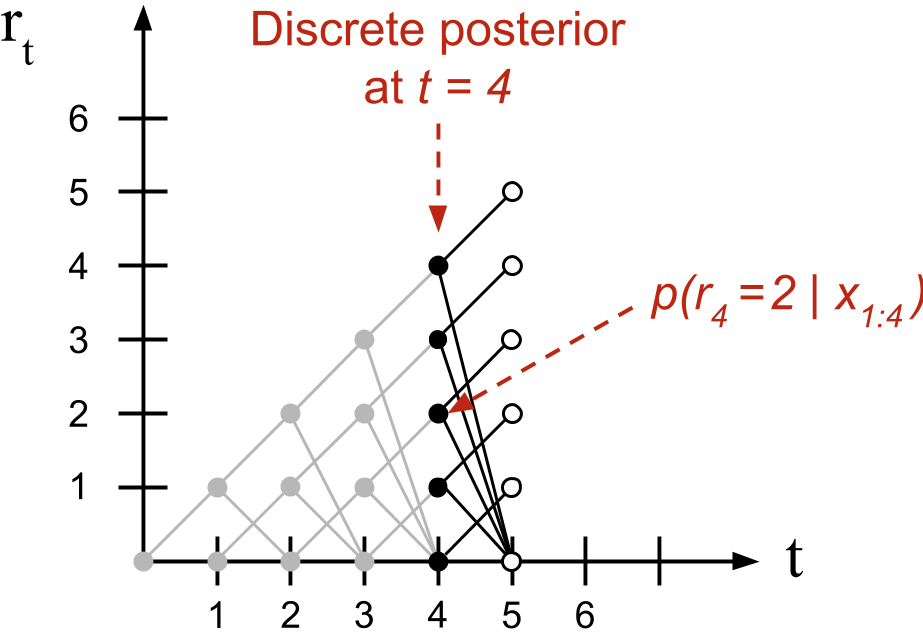
This observation has an important algorithmic consequence. When we compute what Adams and MacKay call the growth probabilities or the probability that the run-length increases, the summation in Equation disappears because each term in the summation is zero except when . It is only when calculating the changepoint probabilities, when the mass is passed downwards, that we sum over previous joint probabilities.
In summary, provided we can compute the UPM predictive and the changepoint prior in Equation and can initialize our recursive algorithm, we will have everything we need for both inference and prediction. Let’s tackle these in that order.
Underlying probabilistic model
Computing the UPM predictive leverages conjugacy and the exponential family. In principle, one could abbreviate this section as most of it is not methodologically novel to the paper. However, when I first read the paper, computing the UPM predictive was not obvious to me, and I will go into detail to explain it.
We assume our model is from an exponential family (EF) member with parameters . To compute , we could integrate over the model’s parameters,
We know the EF model in Equation because it is by construction; we can decide that our data is best modeled by any member of the exponential family. But what is our EF posterior and how do we compute this integral? A useful fact about exponential family models is that we can avoid computing these integrals directly.
Posterior predictive for conjugate models
Before discussing the exponential family, let’s review the prior predictive for any conjugate model. Let be our observations, be a new observation, be our parameters, and be our hyperparameters. The prior predictive distribution is the distribution on given marginalized over ,
Since our prior on is conjugate, we know that
for some different hyperparameters . This is not a deep statement; we are just observing that if we are using a conjugate prior, then the prior is same functional form as the posterior. This implies
Thus, the posterior predictive is the same as the prior predictive but with hyperparameter instead of . If we can compute , we can compute the posterior predictive without integration and without computing the posterior . And conjugate-exponential models allow us to efficiently compute .
Posterior predictive for exponential family models
Now let’s discuss the prior predictive for the exponential family. Recall that the general form for any member of the exponential family is
where is the natural parameter, is the underlying measure, is the sufficient statistic of the data, and is a normalizer. The conjugate prior with hyperparameters and is
where depends on the form of the exponential family member and and are the same as before. If we multiply the likelihood times the prior to get the posterior, we have
Since the first terms are constant with respect to , we can write
Note that this is the same exponential family form as the prior, with parameters:
In other words, we have an efficient way to compute the updated hyperparameters and , which allow us to compute the posterior predictive (Equation ) without integration and without computing the posterior over . This is what Adams and MacKay mean when they write,
This [UPM predictive] distribution, while generally not itself an exponential-family distribution, is usually a simple function of the sufficient statistics.
Importantly, these sufficient statistics are additive and can therefore be computed sequentially.
Message-passing parameters
The upshot of the previous subsection is that rather than computing the UPM predictive by computing the EF posterior and integrating out the parameters, we just need to keep track of the exponential family parameters by time to make a prediction at time . Recall that at each time point , can take possible values (Figure ). Let and denote exponential family parameters at time when takes value , then
While Adams and MacKay do not describe it this way in the paper, I find it useful to imagine the parameter updates as another message-passing algorithm living on a trellis of possible run lengths, similar to Figure (Figure ).
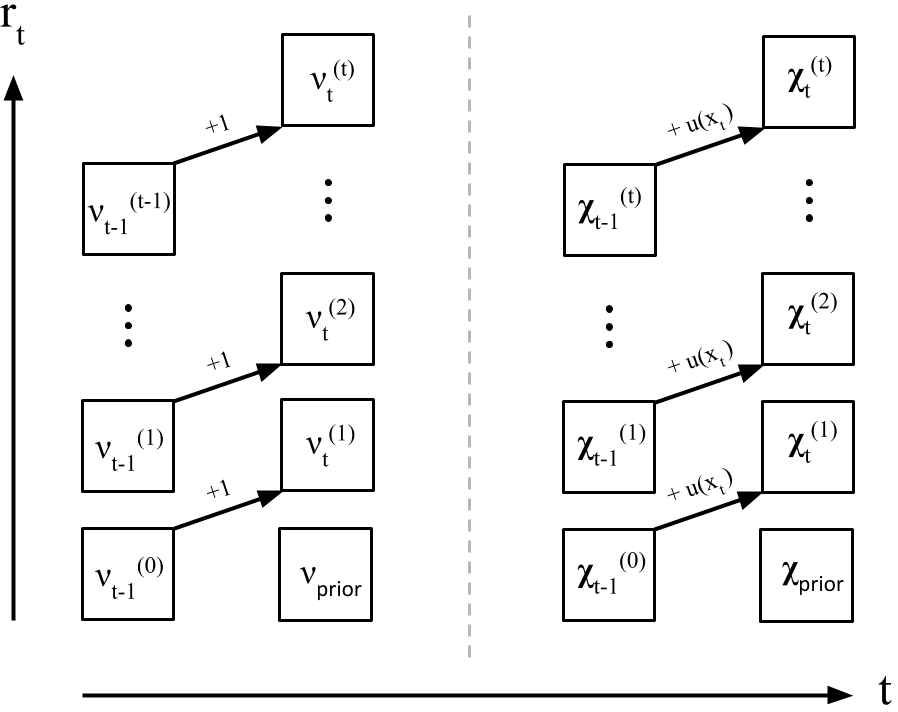
At each time point , we want to model a new possible run-length. In this case, each parameter value is just its prior. Otherwise, we compute and for each run length value by message-passing up the trellis. Formally,
Changepoint prior
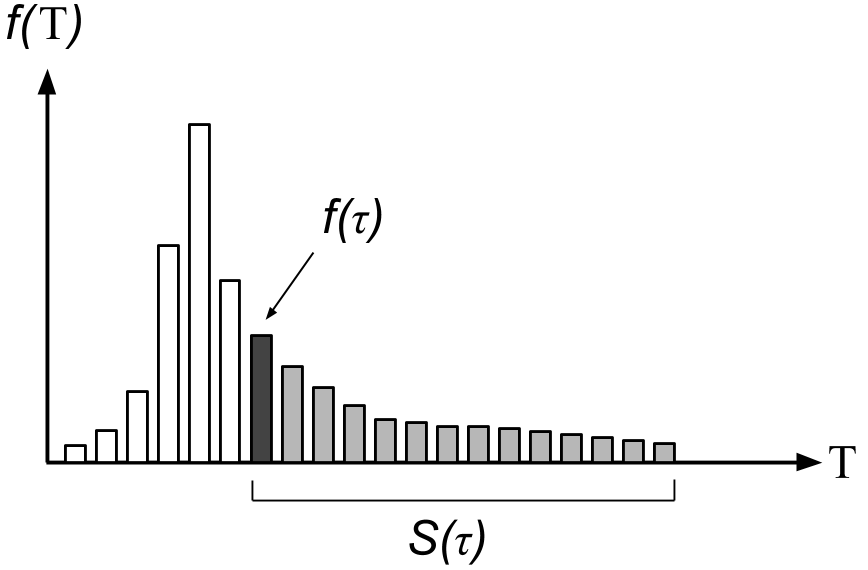
The changepoint prior allows us to encode our knowledge about our data’s changepoints into the model. Let be a discrete, nonnegative random variable for the current run length. Let denote the probability that the current run length is . Let be the survival function at , which is the probability that takes a value greater than or
Then hazard function is
The hazard function quantifies the answer to the question: “Provided a changepoint has not occurred by run length , what is the probability that it will occur at ?” The actual form of the hazard function clearly depends on the distribution of (Figure ).
Our modeling assumption is that our changepoint prior is
For Equation , we only need to compute two cases. The first case is the probability of a changepoint, which is just the hazard function. The second case is the probability that a changepoint does not occur, which is just one minus the probability of a changepoint. This prior is computationally efficient because we only have two cases with nonzero mass, and we only need to compute the hazard function once to compute both cases.
If is a geometric random variable with a probability of success , then (Forbes et al., 2011). This kind of process is called memoryless because the hazard function does not depend on time.
Initial conditions
Earlier, we punted on discussing the initial conditions of our recursive algorithm,
We now have the notation to address this question. We have two scenarios. The first scenario is that a changepoint occurred just before the first data point is observed or . This may not be the most realistic modeling assumption, but it is simple to implement.
The second scenario is that the first changepoint is in the future but we have access to some recent data. The example Adams gives is that of climate change. We have access to historic and current climate data and hypothesize that a changepoint will occur in the future. In this case, the prior over the initial run length is the normalized survival function
where is an appropriate normalizing constant. In words, this is all the mass in the future (note the sum starts at , not ) divided by all the mass of the distribution . The greater the value of , the more mass the sum accumulates or the higher the probability that a changepoint will occur by some large .
Sequential inference algorithm
We are now prepared to understand Bayesian online changepoint detection in algorithmic detail. This algorithm estimates the RL posterior distribution and performs prediction at each time point . Let’s walk through the paper’s Algorithm with annotations as needed:
-
Set priors and initial conditions.
-
Observe new datum .
-
Compute UPM predictive probabilities. This calculation is for each possible run length value
At time , there are possible run lengths; we forward message-pass the mass for these values up the trellis to compute the UPM predictive over ; therefore there are probabilities .
-
Compute growth probabilities. The growth probabilities are the probabilities for each possible run length value. To compute the probability for a specific value , Equation is
Note that there is no sum over because for a given run length, the only valid “growth value” is .
-
Compute changepoint probability. The changepoint probability is the probability that the run length drops to . Again using Equation , we see
In this case we have a sum over because can take any value between and .
-
Compute the evidence. This is just the normalizer in Equation .
-
Compute the RL posterior. Equation .
-
Update sufficient statistics. Equation .
-
Perform Prediction. Equation .
-
Set . Return to Step 2.
A complete example
Now let’s work through a complete example and implementation of the algorithm. Consider the sequence of i.i.d. observations, , in Figure . The groundtruth changepoints are denoted with red dashed lines. We might guess that these data look approximately Gaussian distributed and that while the mean sometimes changes, the variance looks fairly consistent. Thus, to model these data, let’s use a Gaussian model with unknown and fixed precision . The posterior predictive (the UPM predictive) for this model is
where is a new observation and and are defined as
See my post on Bayesian Inference for the Gaussian or (Murphy, 2007) for a complete derivation. To make the algebra easier, assume that ; then we have
In changepoint detection, the number of samples is just the current time point . So the parameter updates for and as increases are
In both instances, the parameter update is a simple function of the previous parameters and the next data point.
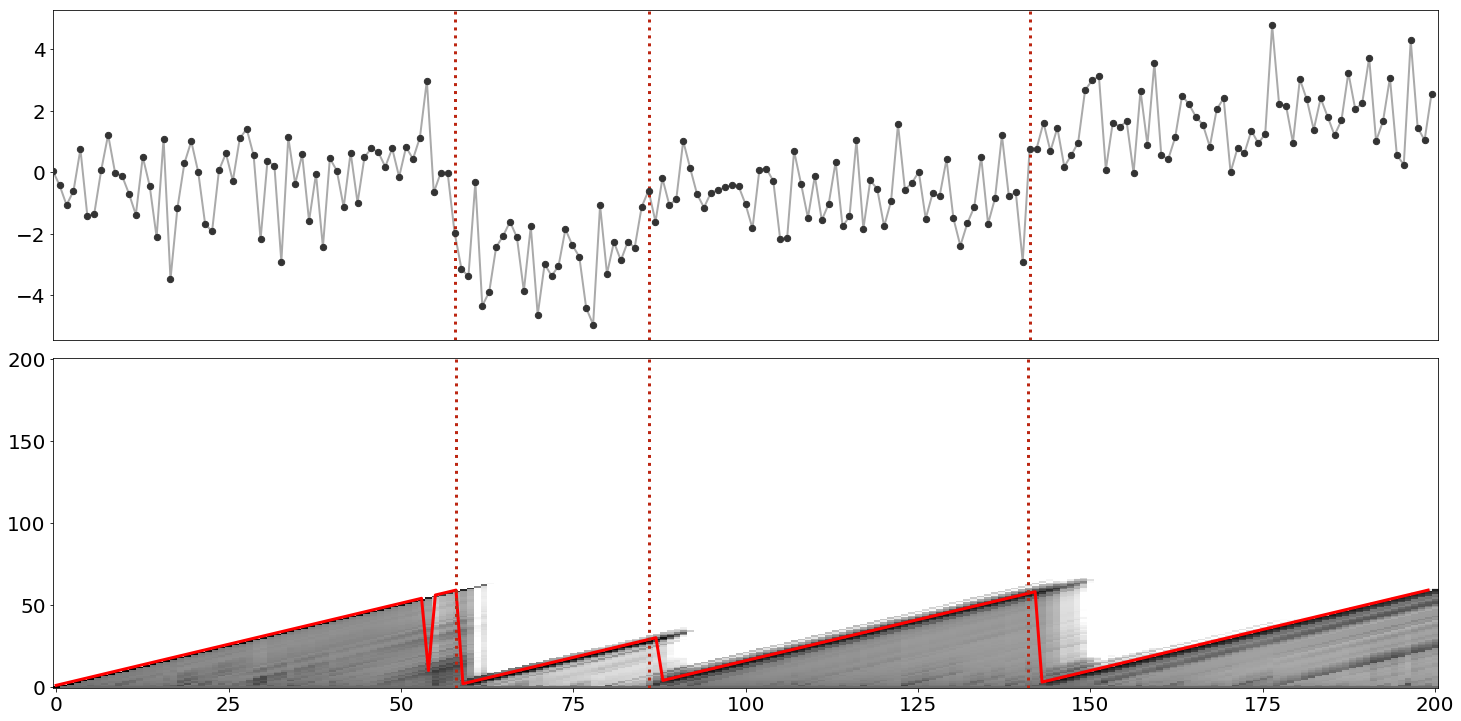
To make things easy, let’s assume a memoryless hazard function, because we see three changepoints in data points. The actual changepoint probability I used to generate the data was . It is beyond the scope of this post, but clearly this hazard function is an important hyperparameter.
Now we are ready for code. While we have leveraged a lot of conceptual machinery, the code is strikingly simple:
import numpy as np
from scipy.stats import norm
R = np.zeros((T+1, T+1))
R[0, 0] = 1
max_R = np.empty(T+1)
max_R[0] = 1
H = 1/60
mu_params = np.array([mu0])
lamb_params = np.array([lamb0])
rl_pred = lambda x, mu, lamb: norm.pdf(x, mu, 1/lamb + 1)
for t in range(1, T+1):
x = data[t-1]
pis = np.array([rl_pred(x, mu_params[i], lamb_params[i]) for i in range(t)])
R[t, 1:t+1] = R[t-1, :t] * pis * (1-H)
R[t, 0] = sum(R[t-1, :t] * pis * H)
R[t, :] /= sum(R[t, :])
max_R[t] = np.argmax(R[t, :])
offsets = np.arange(1, t+1)
mu_params = np.append([mu0], (mu_params * offsets + x) / (offsets + 1))
lamb_params = np.append([lamb0], lamb_params + 1)
Note that the above code is a didactic snippet, i.e. you cannot paste this into a file and run it. For a complete example, see my GitHub. We can visualize the results of this algorithm by plotting both the RL posterior and the max posterior value (Figure ).
Finally, note that Bayesian online changepoint detection is a modular algorithm because both computing the UPM predictive and updating the parameters could be methods on a distribution class that keeps track of the state of its own parameters. Adams notes this in the paper by saying that the framework delineates “between the implementation of the changepoint algorithm and the implementation of the model.”
Conclusions
Bayesian online changepoint detection is a modular Bayesian framework for online estimation of changepoints. It models changes in the generative parameters of data by estimating the posterior over the run length, and it leverages conjugate-exponential models to achieve modularity and efficient parameter estimation. The method is Bayesian in that the changepoint prior allows us to encode knowledge about the world and it models uncertainty about , and it is online because it computes the RL posterior at each time step using only previously seen data.
This paper is from 2007, and I am not up-to-date on the literature on extending this work. However, I would guess that key areas for future work would be addressing the memory usage, which grows quadratically with ; robustly handling a misspecified model or prior; and developing approximate inference routines for non-conjugate models.
Acknowledgements
I thank Diana Cai for giving me an introductory overview of this model and providing working code and Ryan Adams for answering questions about the paper.
- Adams, R. P., & MacKay, D. J. C. (2007). Bayesian online changepoint detection. ArXiv Preprint ArXiv:0710.3742.
- Fearnhead, P., & Liu, Z. (2007). On-line inference for multiple changepoint problems. Journal of the Royal Statistical Society: Series B (Statistical Methodology), 69(4), 589–605.
- Barry, D., & Hartigan, J. A. (1992). Product partition models for change point problems. The Annals of Statistics, 260–279.
- Bishop, C. M. (2006). Pattern Recognition and Machine Learning.
- Murphy, K. P. (2012). Machine learning: a probabilistic perspective. MIT press.
- Forbes, C., Evans, M., Hastings, N., & Peacock, B. (2011). Statistical distributions. John Wiley & Sons.
- Murphy, K. P. (2007). Conjugate Bayesian analysis of the Gaussian distribution. Def, 1(2\sigma2), 16.