Singular Value Decomposition as Simply as Possible
The singular value decomposition (SVD) is a powerful and ubiquitous tool for matrix factorization but explanations often provide little intuition. My goal is to explain the SVD as simply as possible before working towards the formal definition.
Beyond the definition
In my experience, the singular value decomposition (SVD) is typically presented in the following way: any matrix can be decomposed into three matrices,
where is an unitary matrix, is an diagonal matrix, and is an unitary matrix. is the conjugate transpose of . Depending on the source, the author may then take a few sentences to comment on how this equation can be viewed as decomposing the linear transformation into two rotation and one dilation transformations or that a motivating geometric fact is that the image of a unit sphere under any matrix is a hyperellipse. But how did we arrive at this equation and how do these geometrical intuitions relate to the equation above?
The goal of this post is simple: I want explain the SVD beyond this definition. Rather than present Equation in its final form, I want to build up to it from first principles. I will begin with an explanation of the SVD without jargon and then formalize the explanation to provide the definition in Equation . Finally, I will discuss an application of the SVD that demonstrates its utility. In future posts, I hope to prove the existence and uniqueness of the SVD and explain randomized SVD in detail.
This post will rely heavily on a geometrical understanding of matrices. If you’re unfamiliar with that concept, please read my previous post on the subject.
SVD without jargon
Jargon is useful when talking within a community of experts, but I find that, at least for myself, it is easy to use jargon to mask when I do not understand something. If I were to present the SVD to a mathematician, the power of jargon is that I could convey the key ideas rapidly and precisely. The downside is that I could also simply use the words without fully understanding the underlying idea, while my expert listener filled in the gaps. As an exercise, I want to first present the SVD without jargon, as if explaining it to an interested 14-year-old—think eighth-grade level mathematical maturity. I will then formalize this intuitive explanation to work towards the standard formulation. So here we go.
Imagine we have a square. The square, like your hand forming an “L”, has a particular orientation which we graphically represent with arrows (Figure ).
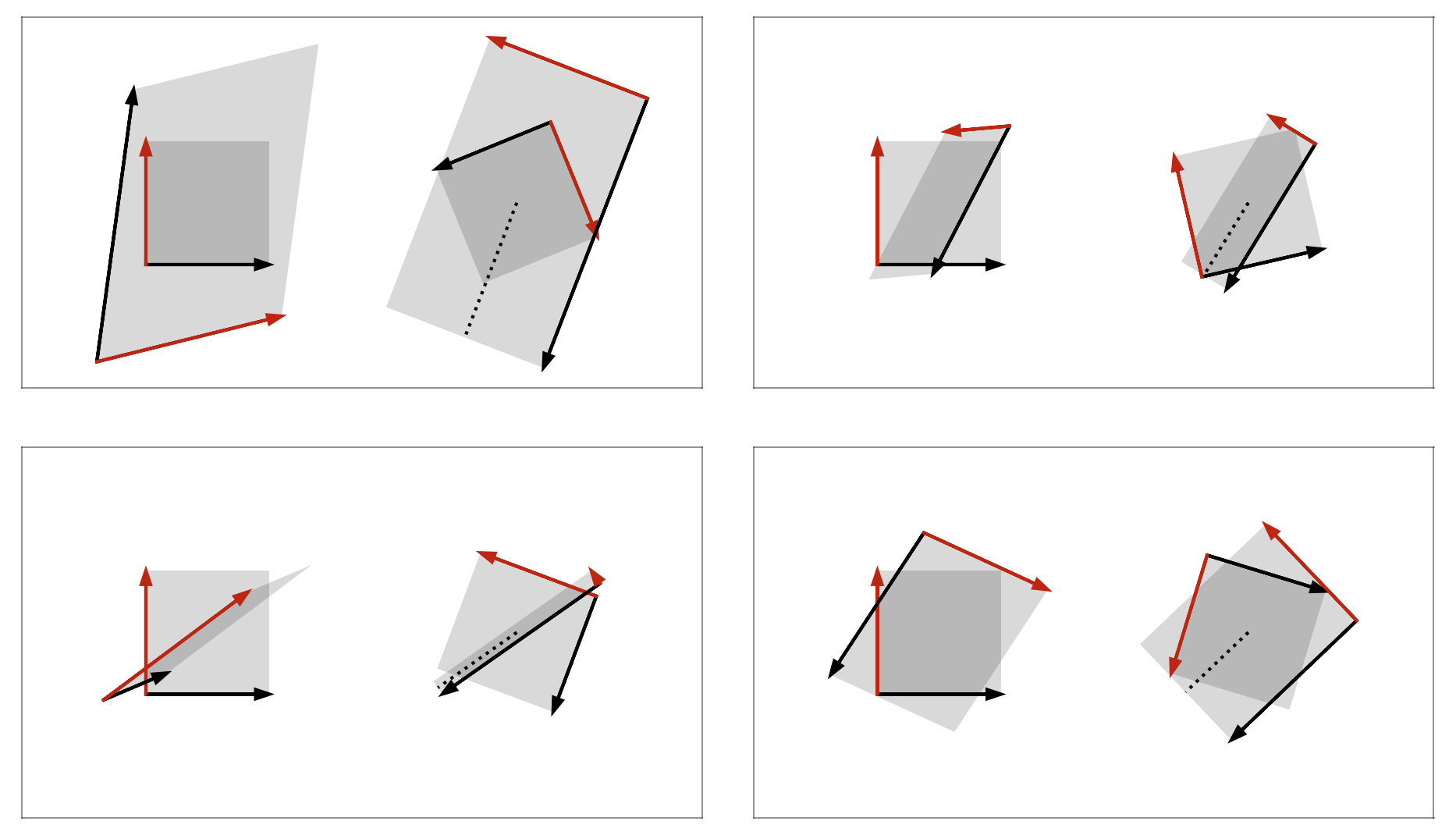
We can manipulate this square in certain ways. For example, we can pull or push on an edge to stretch or compress the square (Figure 2A and 2B). We can rotate the square (Figure 2C) or flip it to change its orientation—imagine turning your hand over so that the “L” becomes an “⅃” (Figure 2D). We can even shear the square, which means to deform it by applying a force either up, down, left, or right at one of the square’s corners (Figure 2E).
The only constraint is that our transformation must be linear. Intuitively, a linear transformation is one in which a straight line before the transformation results in a straight line after the transformation. To visualize what this means, imagine a grid of evenly spaced vertical and horizontal lines on our square. Now let’s draw a diagonal line on the square and perform some transformation. A linear transformation will be one such that after the transformation, this diagonal line is still straight (Figure 3B). To imagine the nonlinear transformation in Figure 3C, imagine bending a piece of engineering paper by pushing two sides together so that it bows in the middle.
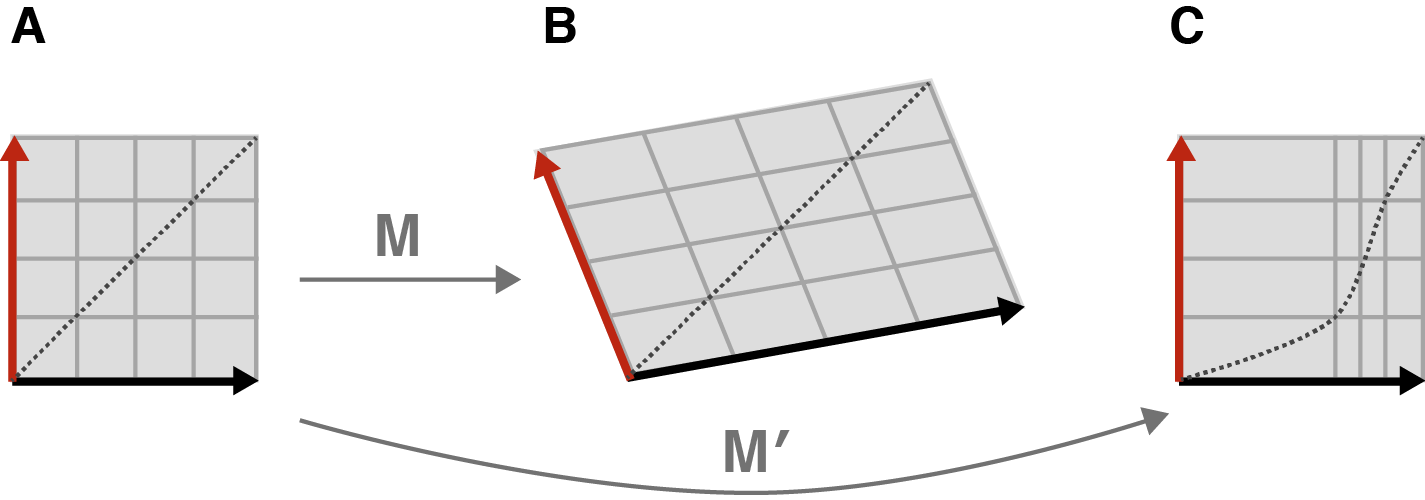
Now that we’ve defined our square and what we can do to it, we can state a cool mathematical fact. Consider any linear transformation , which we will apply to our square. If we are allowed to rotate our square before applying , then we can find a rotation such that, by first applying the rotation and then applying , we transform our square into a rectangle. In other words, if we rotate the square before applying , then just stretches, compresses, or flips our square. We can avoid our square being sheared.
Let’s visualize this with an example. Imagine we sheared our square by pushing horizontally on its top left corner (Figure 4A). The result is a sheared square, kind of like an old barn tipping over. But if we rotated our square before pushing it sideways, the shear would result in only stretching and compressing the square, albeit in a new orientation (Figure 4B).
This is the geometric essence of the SVD. Any linear transformation can be thought of as simply stretching or compressing or flipping a square, provided we are allowed to rotate it first. The transformed square or rectangle may have a new orientation after the transformation.
Why is this a useful thing to do? The singular values referred to in the name “singular value decomposition” are simply the length and width of the transformed square, and those values can tell you a lot of things. For example, if one of the singular values is , this means that our transformation flattens our square. And the larger of the two singular values tells you about the maximum “action” of the transformation.
If that second statement doesn’t make sense, consider visualizing our transformation without the second rotation, which does not effect the size of the rectangle in any way. (Imagine that rectangle in the bottom-right subplot of Figure 4 has the same orientation as the rotated square in the bottom-left subplot.) Also, instead of stretching (or flattening) a square into a rectangle, imagine stretching a circle into an ellipse (We’ll see why in a second.) (Figure 5).
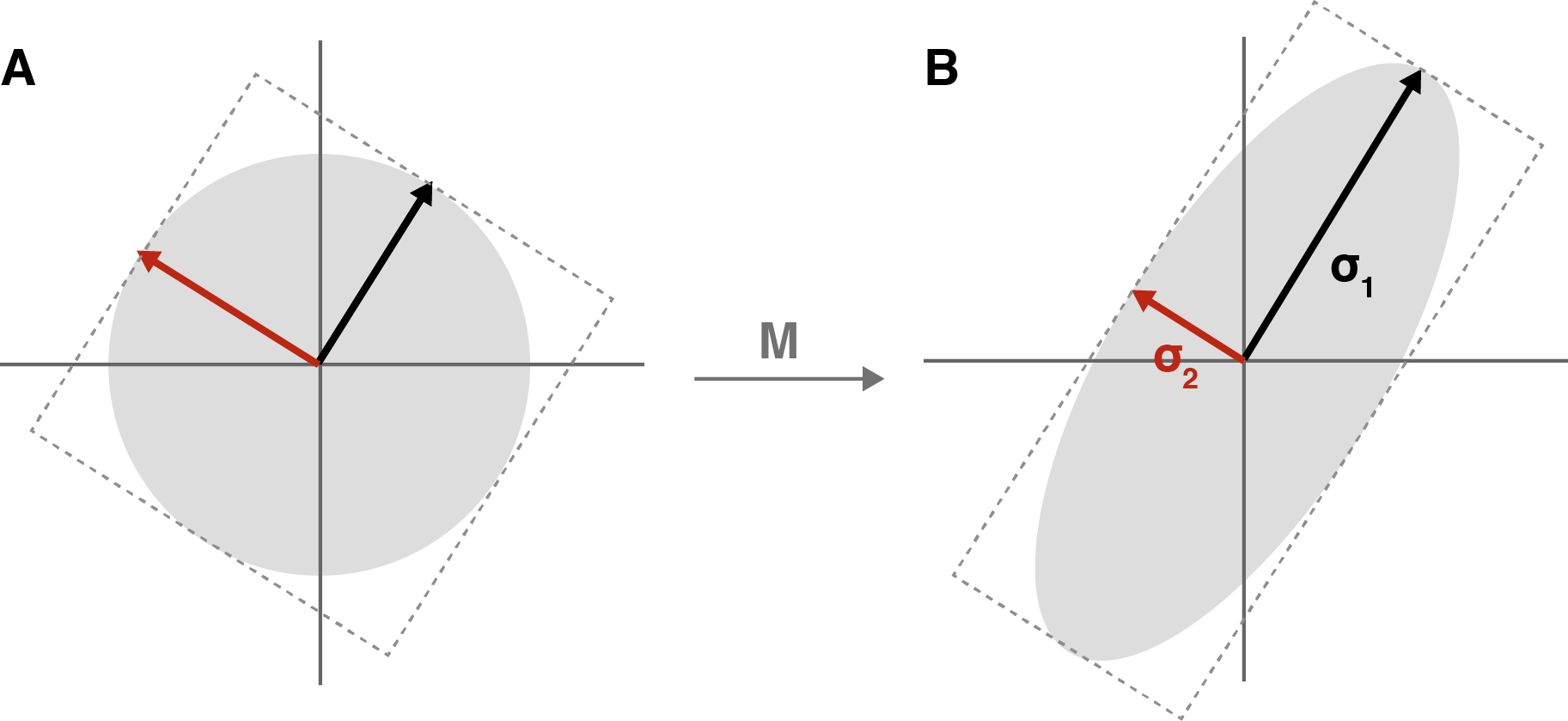
What does Figure 5 represent geometrically? The larger of the two singular values is the length of major axis of the ellipse. And since we transformed a perfect circle, every possible radii (the edge of the circle) has been stretched to the edge of the new ellipse. Which of these evenly-sized radii was stretched the most? The one pulled along the major axis. So the radius that was stretched the most was stretched an amount that is exactly equal to the largest singular value.
From intuition to definition
Now that we have a geometrical intuition for the SVD, let’s formalize these ideas. At this point, I am going to assume the reader is familiar with basic linear algebra. We want re-embrace jargon to speak precisely and efficiently.
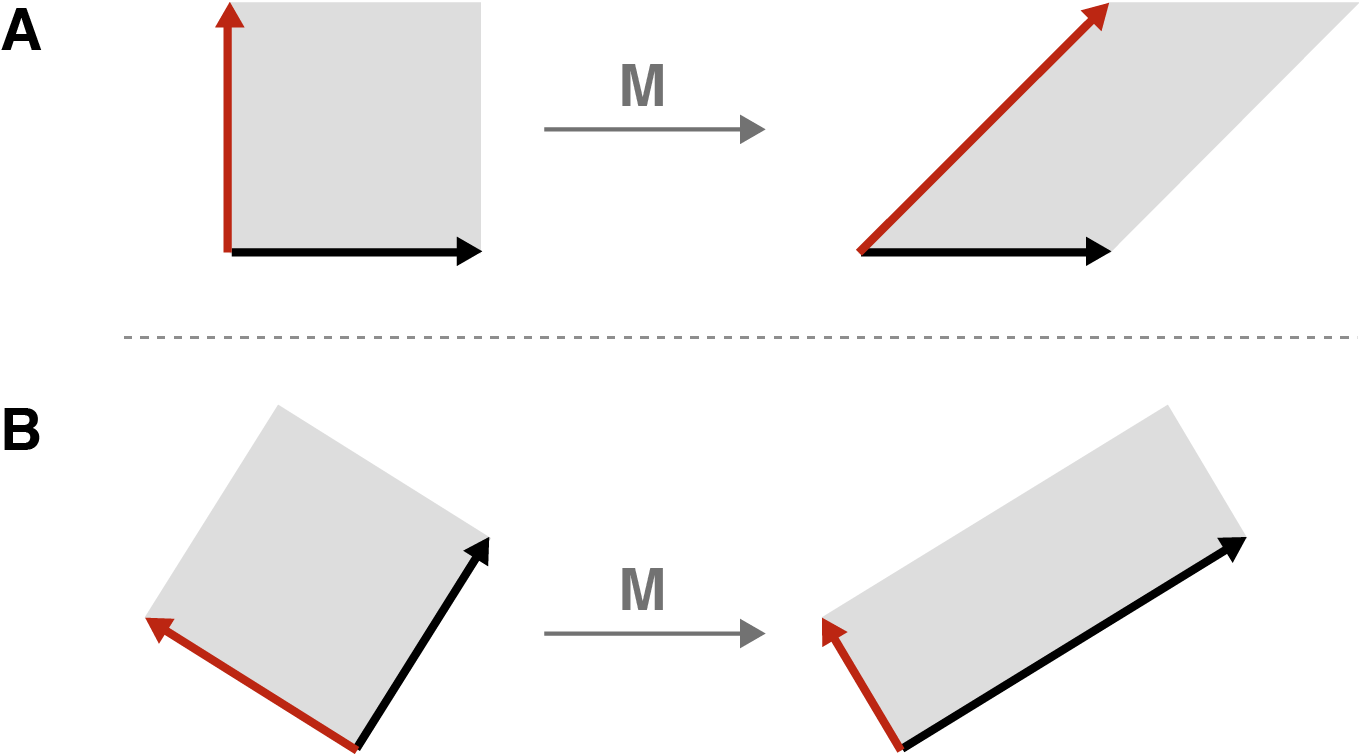
First, let’s name things. Recall that any pair of orthogonal unit vectors in two-dimensional space forms a basis for that space. In our case, let’s call the orthonormal vectors in the input space and (Figure 6A). After applying a matrix transformation to these two vectors, we get and (Figure 6B). Furthermore, let’s decompose these two transformed vectors into unit vectors, and , times their respective magnitudes, and . In other words
So far, we have said nothing new. We are just naming things.
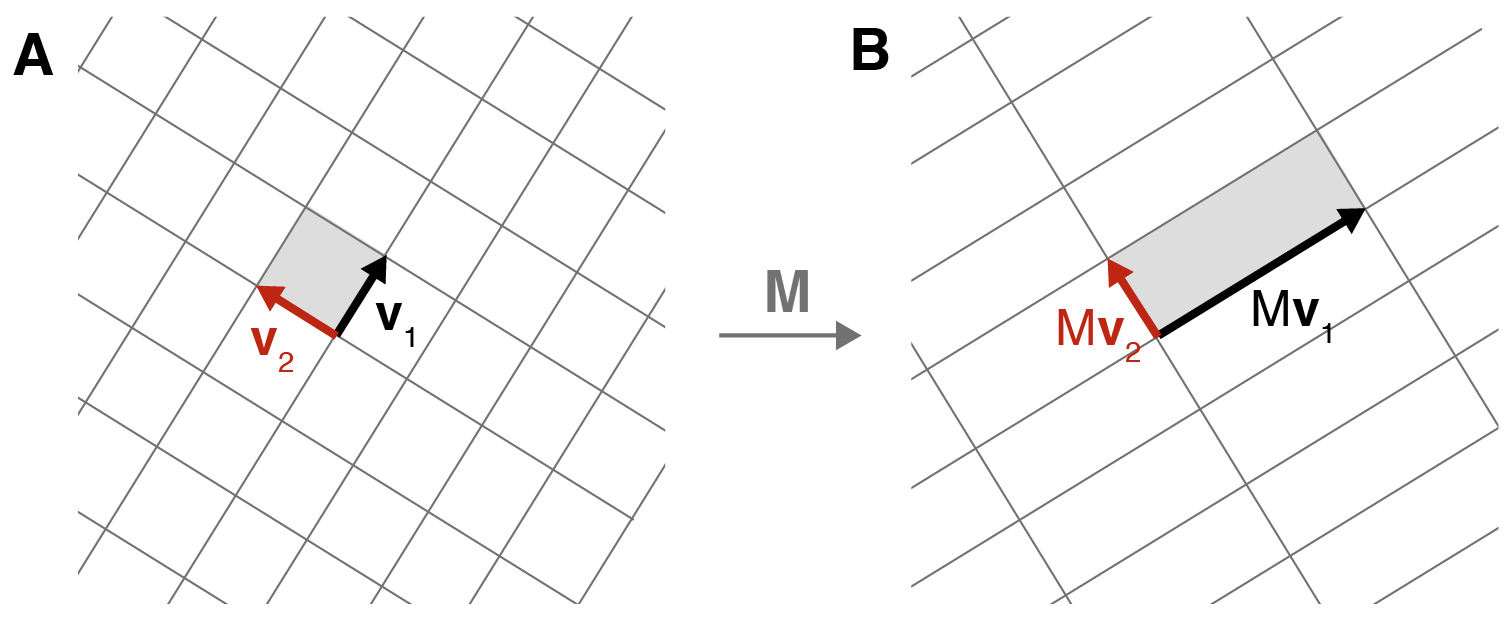
But now that we have things named, we can do a little algebraic manipulation. First, note that any vector can be described using the basis vectors and in the following way,
where denotes the dot product between vectors and . If you’re unsure about the above formulation, consider a similar formulation with the standard basis vectors:
where denotes the -th component of . In Equation , we are projecting, via the dot product, onto and , before decomposing the terms using the basis vectors and .
Next, let’s left-multiply both sides of Equation by our matrix transformation . Since the dot product is a scalar, we can distribute and commute as follows:
Next, we can rewrite as :
We’re almost there. Now since the dot product is commutative, we can switch the ordering, e.g. . And since each dot product term is a scalar, we move each one to the end of their respective expressions:
Now we can remove from both sides of the equation because, in general,
For details, see the discussion here. It might be easier to intuit if we rewrite the claim as
Removing , we get:
Given appropriately defined matrices, Equation becomes the SVD in its canonical form (Equation ) for matrices:
Furthermore, you should have an intuition for what this means. Any matrix transformation can be represented as a diagonal transformation (dilating, reflecting) defined by provided the domain and range are properly rotated first.
The vectors are called the left singular vectors, while the vectors are called the right singular vectors. This orientating terminology is a bit confusing because “left” and “right” come from the equation above, while in our diagrams of rectangles and ellipses, the vectors are on the left.
The standard formulation
Now that we have a simple geometrical intuition for the SVD and have formalized it for all matrices, let’s re-formulate the problem in general and in the standard way. If jumping from -dimensions to -dimensions is challenging, recall the advice of Geoff Hinton:
To deal with hyper-planes in a 14-dimensional space, visualize a 3-D space and say “fourteen” to yourself very loudly. Everyone does it.
Consider that given our definitions of , , and , we can rewrite Equation for an arbitrary matrix as:
which immediately gives us Equation again, but for matrices:
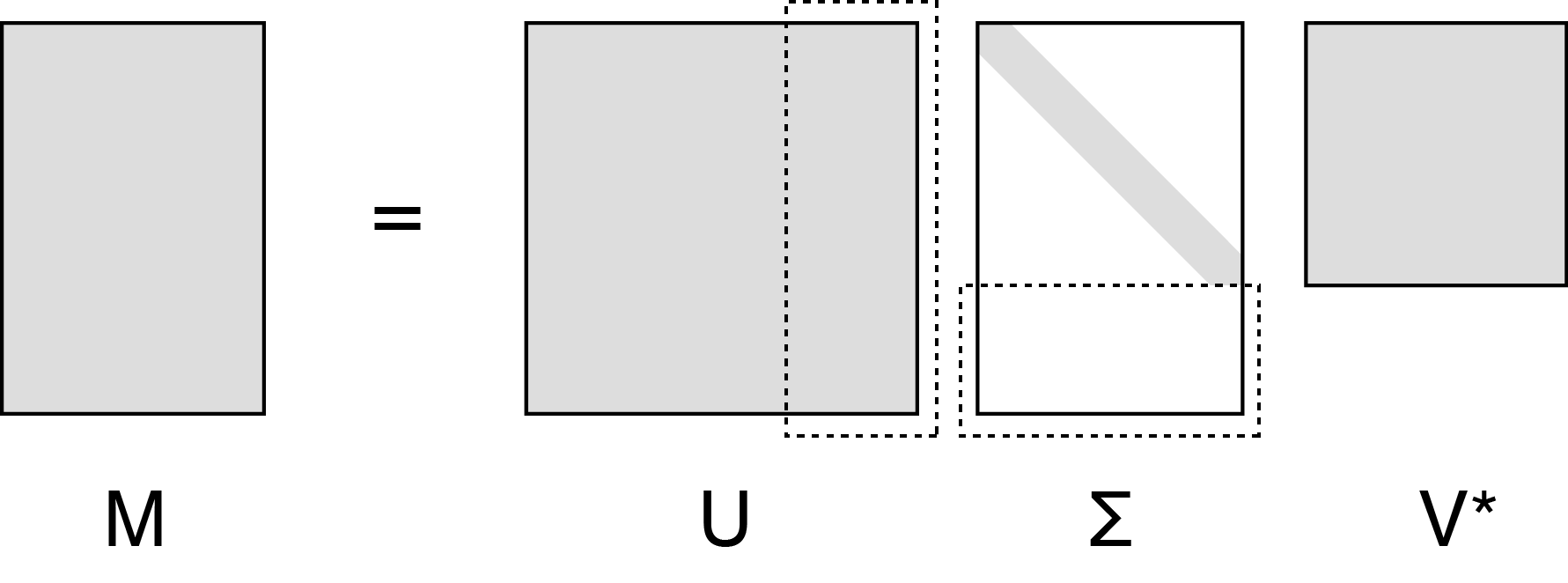
Here, is unitary and ; is unitary and ; and is diagonal and . since is orthonormal. This is schematically drawn in Figure 7.
The diagonal elements of are the singular values. Without loss of generality, we can assume the singular values are ordered—ordering them might require reordering the columns of and . And the geometric interpretation of them holds in higher dimensions. For example, if we performed the SVD on an matrix and noticed that the bottom singular values were smaller than some epsilon, you could visualize this matrix transformation as flattening a hyperellipse along those dimensions. Or if you have an exponential decay in the value of the singular values, it suggests that all the “action” of the matrix happens along only a few dimensions.
And that’s it! That’s the SVD. You can read about the distinction between the full and truncated SVD, about handling low-rank matrices, and so forth in better resources than this. My goal was to arrive at Equation through as simple reasoning as possible. At least in my opinion, going slowly through the geometrical intuition makes explanations of the SVD make more sense.
Re-visualizing the SVD
Now that we understand the SVD, we can convince ourselves that we have been visualizing it correctly. Consider Figure 8, which was generated using Matplotlib and NumPy’s implementation of the SVD, numpy.linalg.svd. We can see that these figures exactly match our intuition for what is happening for the SVD in -dimensions.
Applications
The SVD is related to many other matrix properties. The number of nonzero singular values is equal to the rank of the matrix. This is why the spectral norm is a convex surrogate for low-rank approximations. The range of a matrix is the space spanned by the vectors where is the number of nonzero singular values and all the singular values and vectors are ordered. A matrix is uninvertible if it has a singular value that is zero because the transformation is “collapsing” an -cube along at least one dimension. And so on. Once the SVD is understood, I think it’s fairly straightforward to intuit why the aforementioned properties must hold. See Chapter 5 of (Trefethen & Bau III, 1997) for details.
One algorithm I find much easier to understand after understanding SVD is principal component analysis (PCA). Rather than assume you know how PCA works, let’s look at what PCA computes and then let’s reason about what PCA is doing with our knowledge of the SVD. Consider a real-valued data matrix that is where is the number of samples and is the number of features. Its SVD is
Now consider the covariance matrix of , namely , in the context of the SVD decomposition:
We already know that and are just rotation matrices, while disappears because . And even without knowing about eigenvectors or eigenvalues, we can see what PCA is doing by understanding SVD: it is diagonalizing the covariance matrix of . So PCA is finding the major axes along which our data varies.
If it’s not clear what SVD or eigendecomposition on data means, Jeremy Kun has a good blog post about that.
Conclusion
The singular value decomposition or SVD is a powerful tool in linear algebra. Understanding what the decomposition represents geometrically is useful for having an intuition for other matrix properties and also helps us better understand algorithms that build on the SVD.
Acknowledgments
Writing this post required that I synthesize from a number of excellent resources. Most notably, for the derivation in the section formalizing the SVD, I used this tutorial from the American Mathematical Society. I thank Mahmoud Abdelkhalek and Alfredo Canziani for bringing errata to my attention.
- Trefethen, L. N., & Bau III, D. (1997). Numerical linear algebra (Vol. 50). Siam.