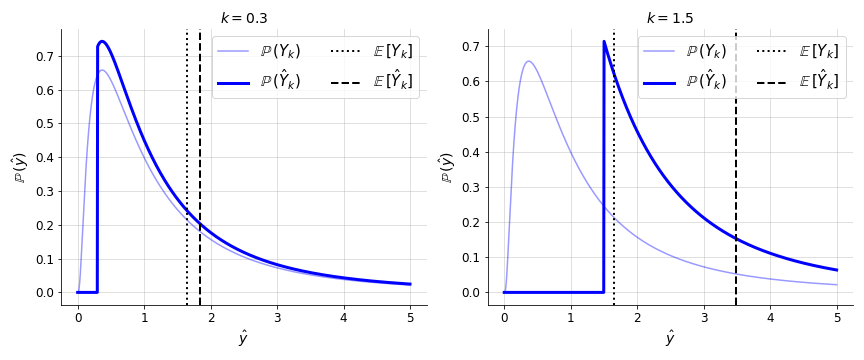
Now consider the left-truncated variable Y^, defined as
Y^={Y0if Y≥k>0,else.(2)
The goal of this post is to derive the expected value of
Y^. Intuitively, we might expect this value to be greater than the expected
value of Y, since left-truncation eliminates probability mass in the left tail of
the distribution (Figure 1).
Figure 1. The probability density function of a random
variable which is lognormally distributed with parameters μ=0 and
σ=1 and then truncated at k=0.3 (left) and k=1.5 (right).
In general, if Z is a random variable left-truncated at a and if f(z)
denotes its probability density function (PDF) and F(z) denotes its
cumulative distribution function (CDF), then its expected value is
E[Z∣Z>a]=1−F(a)∫a∞zg(z)dz,(3)
where
g(z)={f(z)0z>k,else.(4)
I think this makes intuitive sense if we re-arrange the
terms. Consider this equation:
∫a∞zg(z)dz=E[Z∣Z>a]P(Z>a).(5)
Here, the left-hand side is not the desired expectation, as it would be
strictly lower than the expected value of Z. This would not make sense, since
the lower bound on the admissible values of Z is actually increasing as a increases. So we
need to adjust this integral by the probability that Z is greater than
a.
To compute the expectation in our case, we want to simplify the integral I,
I=∫logk∞exp{x}2πσ21exp{−21[σx−μ]2}dx.(6)
The lower bound is logk, not k, because we have used a change of
variables, x=logy, in order to express the expectation in terms of the
density function of the normal distribution.
We can combine the two exponent terms and then simplify the expression to be again
quadratic in x. We can then separate the terms that are quadratic in x from
the terms that do not depend on x:
The last step holds because of the symmetry of the normal distribution. This
gives us:
I=exp{μ+21σ2}Φ(σ−σlogk−μ).(12)
Finally, we need the normalizing factor in Equation 3. Here, that is one minus
the CDF of Y, which is lognormally distributed. This CDF can be expressed in terms of the CDF of the normal distribution:
And we’re done! We can simplify this a bit if we see that the exponent is the mean
of Y—see this appendix for a
derivation—and if we let u denote the z-score
(logk−μ)/σ. This gives us
E[Y∣Y>k]=1−Φ(u)E[Y]Φ(σ−u).(15)
This result is not obvious to me, and I haven’t seen the equation before—hence
why I’m deriving it. So to
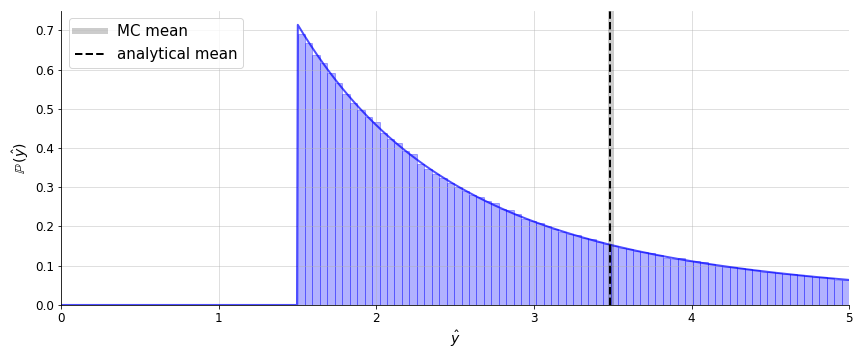
sanity check it, I used Monte Carlo sampling. In Figure 2, I generated a normalized histogram from one
million samples from the truncated lognormal distribution and compared this to
its PDF. I then compared the empirical mean to the mean using Equation
15. This suggests that we’ve derived the mean of the truncated lognormal
distribution correctly.
Figure 2. Monte Carlo estimation of the lognormal distribution and its mean, compared with the mean derived in
Equation 15. The parameters used were μ=0, σ=1, and k=1.5.
Here is the Python code used to generate this figure.