Hypothesis Testing for OLS
When can we be confident in our estimated coefficients when using OLS? We typically use a -statistic to quantify whether an inferred coefficient was likely to have happened by chance. I discuss hypothesis testing and -statistics for OLS.
Imagine we fit ordinary least squares (OLS),
and find that the -th estimated coefficient is some value, say . How confident are we in this result? For example, imagine that the true parameter is actually zero, meaning that there is no relationship between our independent variables and our dependent variables . Then clearly the estimated is wrong and simply happened by chance, due to some properties of our finite sample . In hypothesis testing, we address this problem by answering the question, “What is the probability that just happened by chance?” Answering this question allows us to calibrate our confidence in our model’s inferences.
In this post, I discuss hypothesis testing for OLS in detail. The three big concepts at play in this discussion are -values, -scores, and -statistics. While these ideas are not specific to linear models, I will ground the discussion in OLS. This is because the derivations for -scores and -statistics require assuming a distribution on , resulting in many OLS-specific calculations.
Null hypothesis, -values, and test statistics
In statistical hypothesis testing, the null hypothesis is that , where is the true value for the -th coefficient. The alternative hypothesis is . These options are typically denoted as
The -value for this test is the probability that we observe a result at least as extreme as under the null hypothesis . Imagine we have some way to calculate such a -value. If it is small, then this means it is unlikely that our estimate occurred by chance.
Of course, even if this -value is small, it is still possible that our estimated did in fact occur by chance. We can specify our tolerance for this kind of error using a significance level . For example, means our result is significant if the -value is less than . This means that of the time, we will not see a value as extreme as the one we observed.
To compute -values—which are ultimately just probabilities—with respect to , we need to assume a distribution on . If we assume normally distributed error terms , then we can show that the sampling error is normally distributed:
The notation denotes the -th row and -th column of the inverted Gram matrix. See my previous post on finite sample properties of the OLS estimator for a detailed derivation of Equation .
Equation immediately implies is normally distributed, and we’ll use this fact in the next section to construct test statistics. A test statistic is the output of a function of our finite sample . This is useful because a test statistic typically has a well-defined distribution. We can then use this distribution to compute the appropriate -value to see how likely it is that our observed value happened by chance. For example, if we have some test statistic which follows some well-defined distribution, and then we observe , we can back out the -value since we can compute the value that is at least as extreme as under the null hypothesis.
In the next two sections, we’ll construct two common test statistics, and see how they apply in OLS.
Standard score (-score)
In statistics, a standard score or -score is any quantity
where is the value to be standardized, sometimes called the raw score; is its mean; and is its standard deviation. The difference in the same units as the standard deviation, e.g. if is in meters, is in meters. is positive when the raw score is above the mean and negative when it is below the mean. Since both the numerator and denominator have the same units, is dimensionless. For example, means that or a difference of two standard deviations.
In OLS, if we know the variance , we can compute a standard score for the -th coefficient by normalizing the sampling error :
Since we know that is normally distributed with variance , clearly
Thus, for a particular true value , estimated parameter , and known , we can compute . If is large relative to its mean zero, it suggests the sampling error is large. In other words, a larger is more surprising. We can see how this is related to hypothesis testing, where a surprising can be deemed significant if the probability of it taking or exceeding its value happening by chance is less than . We can easily compute this probability using the cumulative distribution function (CDF) of the normal distribution.
-statistic
What if we don’t know the variance ? We can instead use the OLS estimator of , denoted :
Here, is an -vector of residuals. See my previous post on finite sample properties of the OLS estimator for a proof that is unbiased, i.e. that . Thus, we can replace the standard deviation in Equation with the standard error,
A -statistic, often called a “-stat”, is like a standard score, but it replaces the (unknown) population standard deviation with the standard error:
Similar to the standard score, the -statistic’s numerator is in units of standard error. So means that .
When computing a -score in Equation , we divided a normally distributed random variable by non-random values and . Thus, was normally distributed. However, when computing a -statistic in Equation , we are dividing a normally distributed random variable by a function of , and therefore is not normally distributed. However, one can prove that is -distributed—hence it’s name—with degrees of freedom:
Here, denotes the -distribution with degrees of freedom. See A1 for a proof of this claim. The main point is that, again, we have a well-behaved distribution for our test statistic, and we can therefore compute -values. Note that and are both predetermined by our data, and we can compute everything we need in Equation .
Note that -stats can be negative; it simply means that .
Testing the null hypothesis
Now that we know the distribution of -statistics, we have a method for deciding if an estimated coefficient is statistically significant. First, given a hypothesized true value , compute the -statistic . Then for a given significance level , for example , we can compute the critical values, which are the boundaries of the region in which we would accept the null hypothesis. Accept the null hypothesis if is less extreme than the critical values, if it is in the acceptance region. Reject the null hypothesis if is more extreme than the critical values (Figure ).
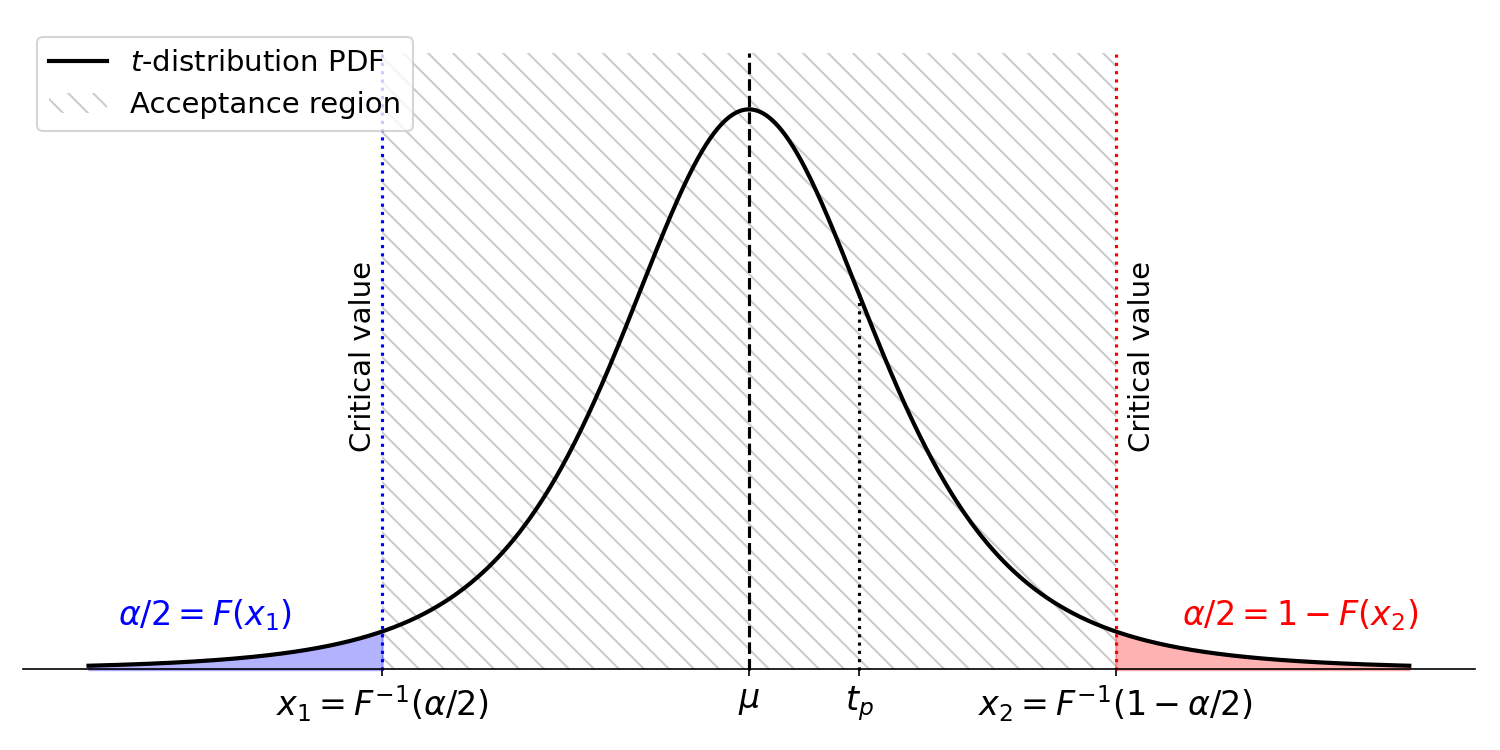
For example, imagine that , , , and . We want to compute the critical values, and . We can do this using the CDF and the inverse CDF :
We can then compute and to see if is outside of the acceptance region. Historically, before easy access to statistical software, one would look up the critical values in a -table. However, today, it is easy to quickly compute the critical values, e.g. in Python:
>>> from scipy.stats import t
>>> tdist = t(df=30)
>>> alpha = 0.05
>>> x1 = tdist.ppf(alpha/2)
>>> x2 = tdist.ppf(1 - alpha/2)
>>> (x1, x2)
(-2.042272456301238, 2.0422724563012373)
We can see that is not significant at level with .
-scores vs -statistics
At this point, we have enough of an understanding of -scores and -statistics to say why we typically use -statistics in hypothesis testing for OLS. First, we typically don’t know the population standard deviation . Second, if is sufficiently large, then the -distribution is approximately normal (Figure ). Given that both these conditions are often true, it makes sense to just use -statistics by default.
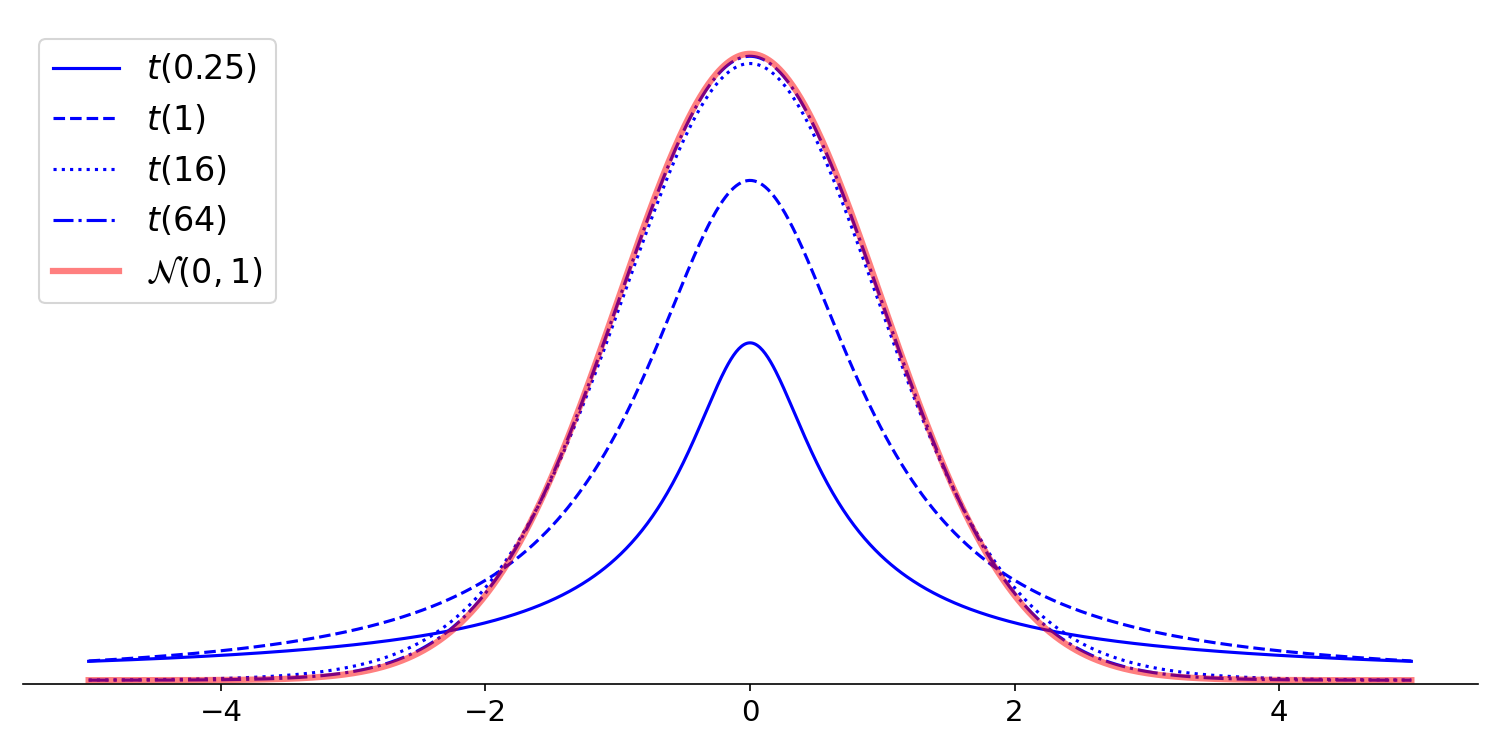
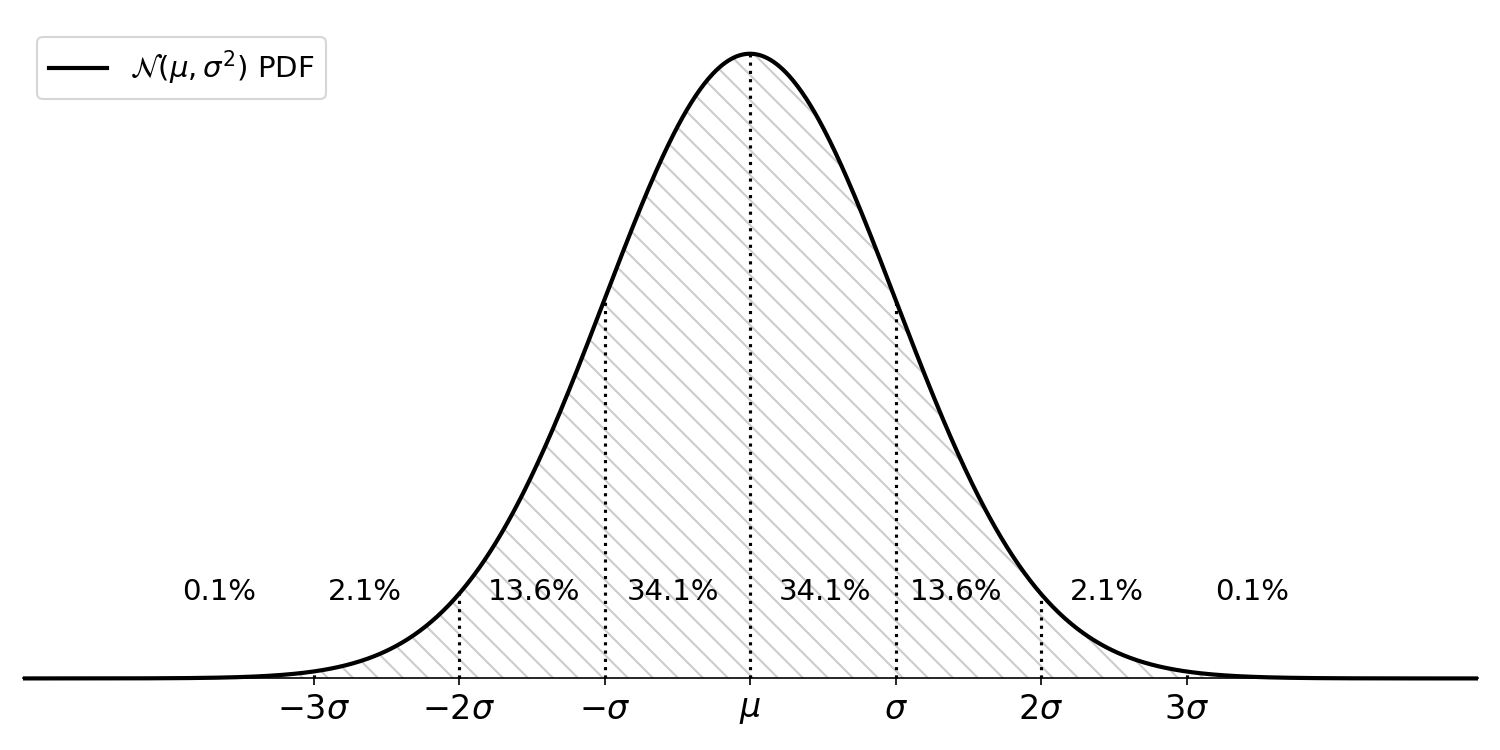
Note that when is reasonably large, where “reasonably large” is traditionally defined as , the -distribution is well-approximated by the standard normal distribution, . Here, we know that roughly of the mass is within two standard deviations of the mean (Figure ). Thus, as a first approximation without using -tables or statistical software, we can say that a -statistic greater than is significant when .
Statistical significance without knowing
What if we know that the correlation between our regression targets and a single predictor was . Without knowing , can we compute the minimum number of samples we need to have a statistically significant inference? In fact, we can. This is a fun result that’s worth knowing about.
In a previous post, I re-derived a standard result that shows that the residual sum of squares (RSS) can be written in terms of the un-normalized sample variance and Pearson’s correlation:
And the OLS estimator of the variance, , can be written in terms of RSS,
Furthermore, we know that can be written in terms of the correlation and un-normalized sample standard deviations,
See my previous post on simple linear regression and correlation for a derivation of this fact. Putting this together with Equation and assuming , we can re-write the -statistic as
In simple linear regression, . And we know , so we have
So for a confidence level , we need samples to have a statistically significant result. This section is a bit tangential to the main ideas of this post, but this is a fun result.
Conclusion
In OLS, assuming normal error terms implies our estimated coefficients are normally distributed. This allows us to construct standard scores and -statistics with well-defined distributions. We can use these test statistics to back out -values, which quantify the probability that we observe a result at least as extreme as under the null hypothesis.
Acknowledgements
I thank Mattia Mariantoni for pointing out a typo in Equation .
Appendix
A1. Proof that -statistics are -distributed with degrees of freedom
This proof is from (Hayashi, 2000). We can write the -statistic for the -th predictor in Equation in terms of its -score:
Step uses the definition of (Equation ). Step introduces a new variable, .
Now the logic of the proof is as follows. First, we know that has distribution . We will then show that , or conditioned on the predictors is chi-squared distributed with degrees of freedom. Next, we will prove that, conditional on , and are independent. This immediately implies that is -distributed, since the -distribution is a ratio distribution arising from a normal random variable divided by an independent chi-distributed (or square root of a chid-squared-distributed) random variable.
Step 1.
The proof that the quadratic form in Equation below is chi-squared is from here. A chi-squared distributed random variable with degrees of freedom is the distribution of the sum of independent standard normal random variables, each squared. Formally, if are i.i.d. from , then where
is chi-squared distributed. We want to show that
is chi-squared distributed. We saw in a previous post (see Equation here) that
where is the residual maker matrix (see Equation here for a definition). Since and since is symmetric (see Equation here), then clearly is symmetric. Thus, is diagonalizable with an orthogonal matrix ,
Since is idempotent, it’s eigenvalues are either zero or one, and the number of non-zero eigenvalues is equal to the rank of . Now consider the distribution of
Since is normally distributed, and since is a linear map, we know that is normally distributed. The normal distribution is fully specified by its mean and variance, which for are
So we have shown that
Now we can write in Equation in terms of ,
As we said above, since is idempotent, it’s eigenvalues are either zero or one, and it has non-zero eigenvalues. So the last line of Equation can be written as
Since each , then is chi-squared distributed with degrees of freedom. We saw in a previous post that (see Equation here).
Step 2. and are independent given
We want to prove that and are independent. We’ll do this indirectly, by proving that and are jointly Gaussian and therefore independent. Since is a function of and is a function of , this would imply that and are independent.
The noise terms are multivariate normal,
Furthermore, both the OLS estimator and the residuals are linear functions of . To see this, recall that we proved the following relationship about the sampling error :
(See Equation here.) Then we can write both and as
So both and are normal. Now a necessary and sufficient condition for and to be jointly Gaussian is that for every pair of scalars , the linear combination is normal. We have:
This is clearly Gaussian, since is the only random quantity, and the rest of the terms are linear functions or scalars. Thus, conditional on , and and are jointly normal and therefore independent. Thus, and are independent.
Taken together, steps and prove that the -statistic is -distributed with degrees of freedom.
- Hayashi, F. (2000). Econometrics. Princeton University Press. Section, 1, 60–69.