In simple linear regression, the slope parameter is a simple function of the correlation between the targets and predictors. I derive this result and discuss a few consequences.
Published
25 August 2021
Consider simple linear regression or linear regression with a single independent variable,
yn=α+βxn+εn.(1)
β is the model’s slope, and α is the model’s intercept. There is an interesting relationship between the estimated linear coefficient β^ and Pearson’s correlation coefficient between the predictors and targets, ρxy. The goal of this post is to understand this relationship better.
Univariate normal equation
Let’s rederive the normal equations for ordinary least squares (OLS), which minimizes the sum of squared residuals:
We can find the minimizers for β and α by differentiating J w.r.t. these parameters and solving for them after setting the derivative equal to zero. (We are ignoring the endpoints and second-order conditions since this is an established result.)
First, let’s solve for intercept α. We take the derivative of the objective function w.r.t. to α,
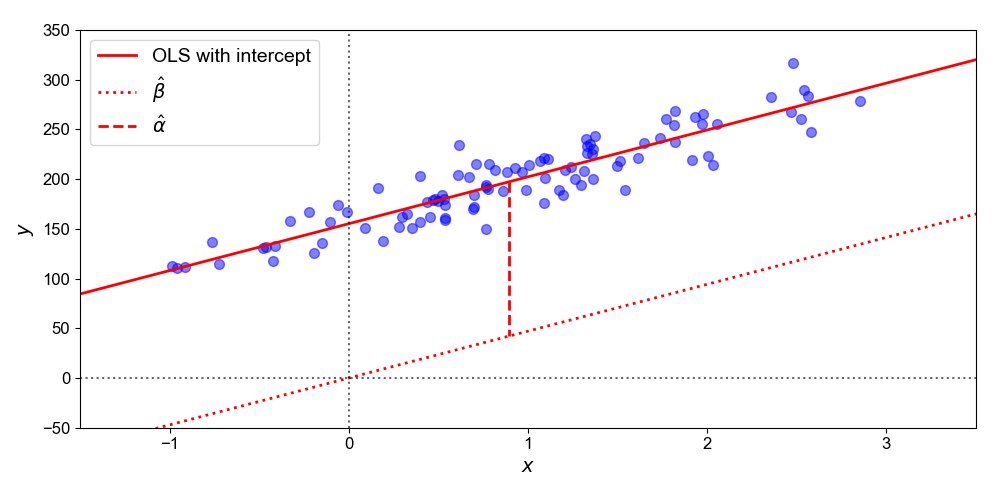
Figure 1. OLS with an intercept (solid line) can be decomposed into OLS without an intercept (dotted line) and intercept term (dashed line). Without an intercept, OLS goes through the origin. With an intercept, the hyperplane is shifted by the distance between the original hyperplane and the mean of the data.
I find it useful to visualize these two parameter estimates (Figure 1). The slope β^ passes through the origin (0,0), while the intercept α^ shifts this slope so that it passes through the data’s mean, (xˉ,yˉ).
β^ in terms of correlation
We can write β^ in terms of Pearson’s correlation between our targets y and predictors x, denoted ρxy. First, let’s denote the sample standard deviations for x and y as Sx and Sy respectively, i.e.
In other words, if we standardize our data, the estimated slope β^ is just ρxy, the correlation between x and y. Note that if we were to use OLS without an intercept, we must also mean-center our data for this claim to be true. This is because β^ without an intercept is
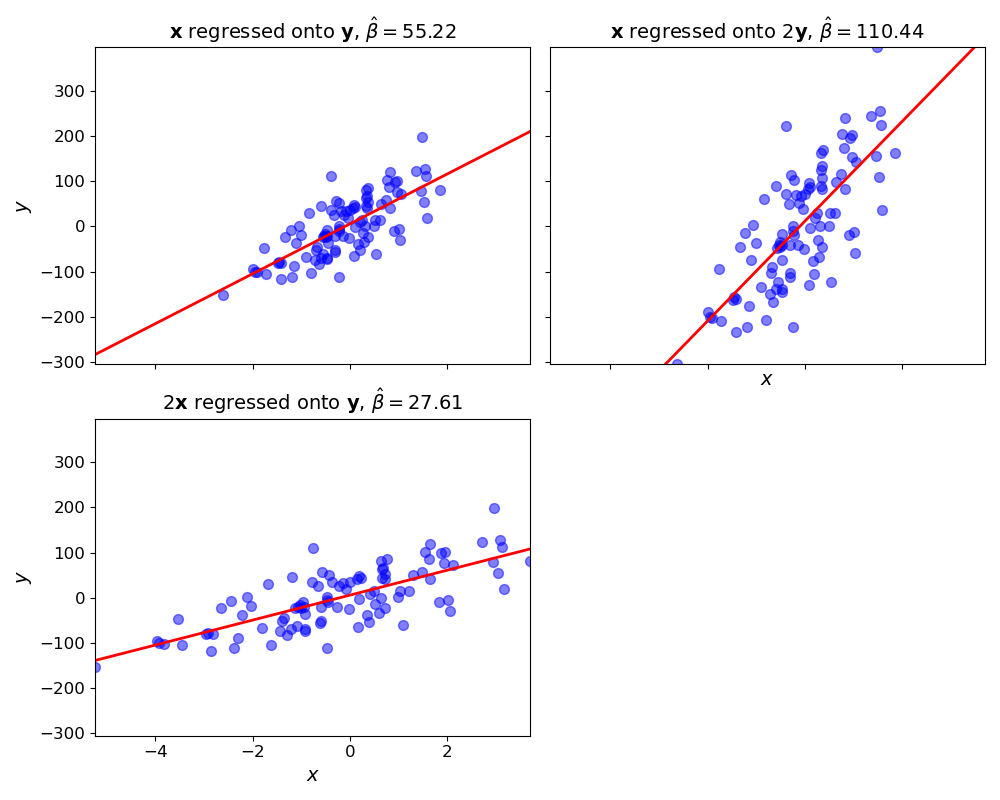
Figure 2. Slope parameter β^ for OLS fit to targets and predictors (x,y) (top left), (x,2y) (top right), and (2x,y) (bottom left). The slope halves or doubles, depending on how the standard deviation terms change.
Understanding β^ in this way makes it easier to understand implications to changes in our predictors. Example, imagine that we doubled our predictors, i.e. we fit OLS to 2x=[2x1,…,2xN]⊤ or we doubled our targets, i.e. we fit OLS to 2y=[2y1,…,2yN]⊤. How would this change our OLS estimates? We know that the correlation would not change, but both the mean and standard deviations would double, so β^ would either halve when x is doubled or double when y doubles. We can see this directly in Equation 11, and I have visualized it in Figure 2.
Acknowledgements
I thank Andrei Margeloiu for pointing out some confusing text regarding when β^ is equal to ρxy.
Appendix
A1. Rewriting Equation 7
Equation 7’s numerator can be written as the un-normalized sample covariance between x and y: