The ELBO in Variational Inference
I derive the evidence lower bound (ELBO) in variational inference and explore its relationship to the objective in expectation–maximization and the variational autoencoder.
Variational inference
In Bayesian inference, we are often interested in the posterior distribution where are our observations, and are latent variables, . However, in many practical models of interest, this posterior is intractable because we cannot compute the evidence or denominator of Bayes’ theorem, . This evidence is hard to compute because we have introduced latent variables that must now be marginalized out. Such integrals are often intractable in the sense that (1) we do not have an analytic expression for them or (2) they are computationally intractable. See my previous post on HMMs or (Blei et al., 2017) for examples.
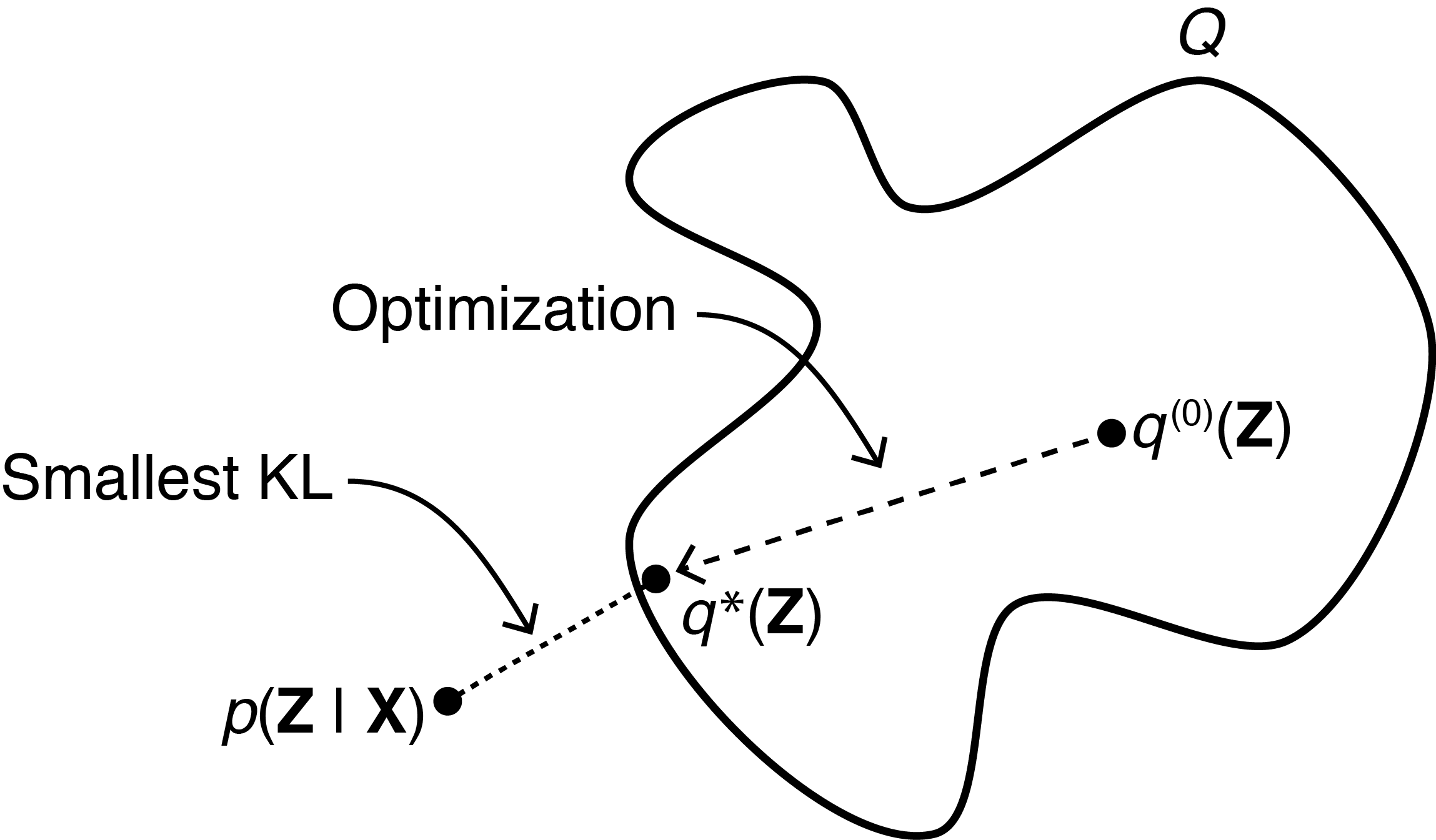
The main idea of variational inference (VI) is to use optimization to find a simpler or more tractable distribution from a family of distributions such that it is close to the desired posterior distribution (Figure ). In VI, we define “close to” using the Kullback-Leibler (KL) divergence. Thus, the desired VI objective is
Minimizing the KL divergence can be interpreted as minimizing the relative entropy between the two distributions. See my previous post on the KL divergence for a discussion.
Evidence-lower bound
The main challenge with the variational inference objective in Eq. is that it implicitly depends on the evidence, . Thus, we have not yet gotten around the intractability discussed above. To see this dependence, let’s write out the definition of the KL divergence:
Because we cannot compute the desired KL divergence, we optimize a different objective that is equivalent to this KL divergence up to constant. This new objective is called the evidence lower bound or ELBO:
This is a negation of the left two terms in Eq. . We can rewrite Eq. as
Why is the ELBO so-named? Since the KL divergence is non-negative, we know
In other words, the log evidence , a fixed quantity for any set of observations , cannot be less than the ELBO. So if we maximize the ELBO, we minimize the desired KL divergence. This is VI in a nutshell.
Relationship to EM
It’s fun to observe the relationship between VI and expectation–maximization (EM). EM maximizes the expected log likelihood when , i.e.
To be a bit more pedantic, at iteration with current parameters estimates , EM optimizes this expected complete log likelihood inside the ELBO:
See my previous post on EM for why EM ignores the right term in Eq. .
Gradient-based VI
VI is a framework, and there are a variety of different ways to optimize this ELBO. (See (Blei et al., 2017) for a much deeper discussion.) A popular approach in deep generative modeling is to use gradient-based optimization of the ELBO. Describing a low-variance, gradient-based estimator of the ELBO is a main contribution of (Kingma & Welling, 2013). This allows for us to approximate the posterior with more flexible density estimators, such as neural networks. The most famous example of gradient-based VI is probably the variational autoencoder. See (Kingma & Welling, 2013) or my previous post on the reparameterization trick for details.
- Blei, D. M., Kucukelbir, A., & McAuliffe, J. D. (2017). Variational inference: A review for statisticians. Journal of the American Statistical Association, 112(518), 859–877.
- Kingma, D. P., & Welling, M. (2013). Auto-encoding variational bayes. ArXiv Preprint ArXiv:1312.6114.