I discuss Bayesian linear regression or classical linear regression with a prior on the parameters. Using a particular prior as an example, I provide intuition and detailed derivations for the full model.
Published
04 February 2020
A Bayesian approach
In my first post on linear models, I discussed ordinary least squares (OLS) regression. OLS is simple, interpretable, and well-understood. The parameter estimate which minimizes the sum of squared residuals is also the maximum likelihood estimate (MLE) under a probabilistic interpretation of the model. MLEs are theoretically well-understood. For example, MLEs are asymptotically normal and many achieve the Cramér–Rao lower bound, meaning they have minimum possible variance in the class of unbiased estimators. However, OLS can overfit, which I discussed in my second post on linear models. We can see this by looking at the model for linear regression,
yn=β⊤xn+εn.(1)
Above, xn is the nth data point, a P-vector of predictors; yn is a scalar response; β is a P-vector of coefficients; and εn∼N(0,σ2) is unobserved noise. Notice that even if a true coefficient value (a component of β) is zero, the learned coefficient will not be because of the noise term εn.
Another way to see this is to think about the probabilistic interpretation of (1),
yn∣β,σ2∼N(yn∣β⊤xn,σ2).(2)
Here, yn is a random variable with mean β⊤xn and variance σ2. Even if the true mean is a P-vector of zeros, yn is a random quantity since σ2 is nonzero.
A Bayesian approach to tackling this problem is to use priors. A prior is a distribution on a parameter. To give some intuition for why this might be useful, consider the task of inferring the bias of a coin. If you could flip the coin an infinite number of times, inferring its bias would be easy by the law of large numbers. However, what if you could only flip the coin a handful of times? Would you guess that a coin is biased if you saw three heads in three flips, an event that happens one out of eight times with unbiased coins? The MLE would overfit these data, inferring a coin bias of p=1. A Bayesian approach avoids overfitting by quantifying our prior knowledge that most coins are unbiased, that the prior on the bias parameter is peaked around one-half. The data must overwhelm this prior belief about coins.
In Bayesian linear regression, we place a prior on β that is a zero-centered and symmetric distribution. In my mind, this prior on β is almost like a null hypothesis; it is the modeling assumption equivalent that there is no relationship between xn and yn. Recall that a small coefficient βp indicates that the marginal effect of the pth predictor is negligible. It is up to the data to prove this belief wrong.
Example
Bayesian inference amounts to inferring a posterior distribution p(β∣X,y) where I use X to denote an N×P matrix of predictors and y to denote an N-vector of scalar responses. The idea is to use Bayes’ formula to compute this,
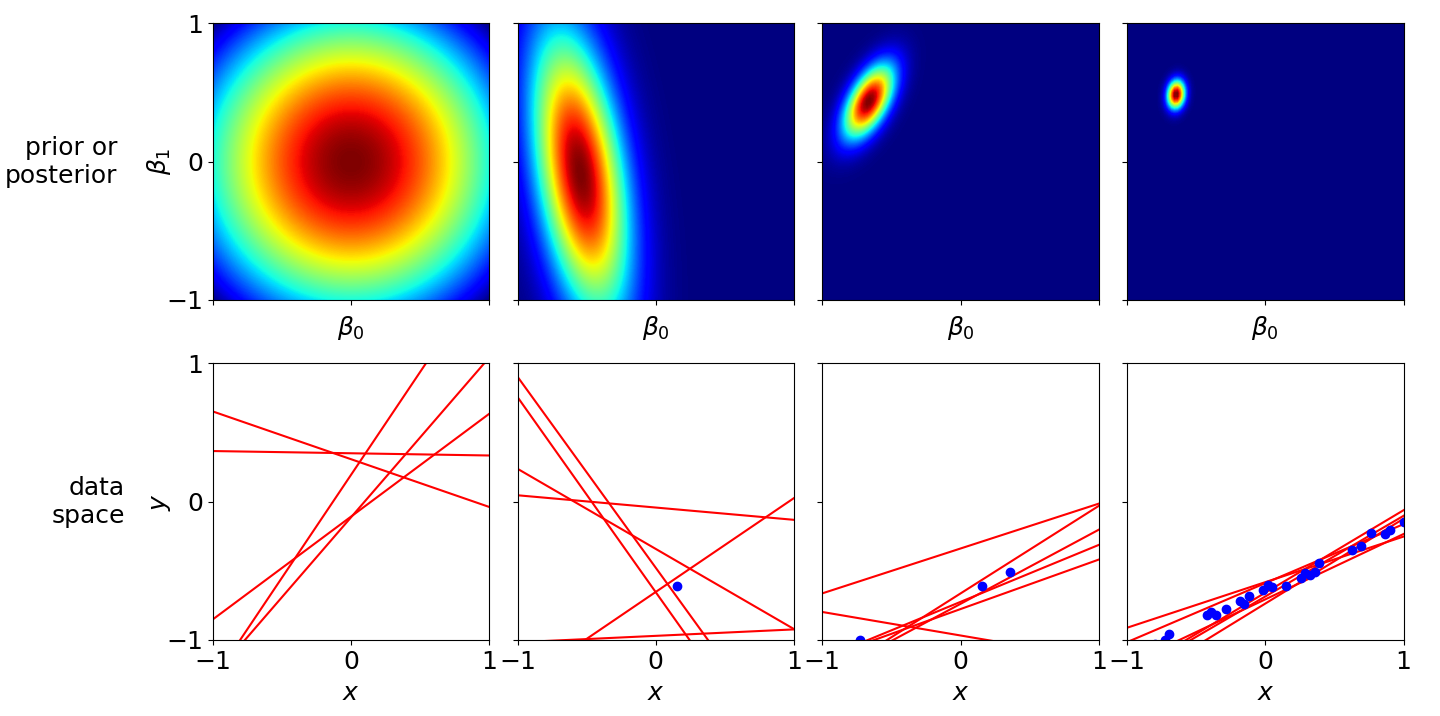
Performing exact Bayesian inference can be extremely tedious because it involves lots of calculations to ensure the inferred distributions are tractable. However, before getting into the weeds, let’s look at a motivating example. (Bishop, 2006) has a famous figure (his Figure 3.7) explaining Bayesian linear regression, and I’ve reproduced a version of that figure with my own implementation of Bayesian linear regression (my Figure 1). It is really worth spending time on this figure because it captures some key ideas in Bayesian inference.
Figure 1. Bayesian linear regression using the hierarchical prior in (5). The top row visualizes the prior (top left frame) and posterior (top right three frames) distributions on the parameter β with an increasing (left-to-right) number of observations. The bottom row visualizes six draws of β from each frame's respective distribution (the frame above). The data is generated using true bias and slope parameters βtrue=[0.5,−0.7]⊤. See this GitHub repo for code to reproduce the figures in this post.
The true generative model is scalar data with a bias term,
yn=0.5xn−0.7(4)
where β1=0.5 and the bias is β0=−0.7. This allows us to plot the coefficients in two-dimensions (top row) while visualizing the inferred hyperplanes in two-dimensions as well (bottom row). In the first column, the model has seen no data. The prior places high and equal probability on both β0 and β1 being zero. Six random samples of the vector β=[β0,β1]⊤ are shown in the bottom row; these are draws from our prior distribution on β. In subsequent columns, the model is fit to more data. As we can see, with more data the model’s inferred posterior variance decreases, and the realizations of β from the posterior become more constrained.
Tractability through conjugacy
In principle, we can use any prior on our parameters that we would like. However, the functional form of most priors, when multiplied by the functional form of the likelihood in (3), results in an posterior with no closed-form solution. It might also be tricky to draw samples or compute moments. In these cases, we would resort to approximate Bayesian inference techniques such as Monte Carlo methods or variational inference. Thus, certain priors are mathematically convenient because they result in posteriors with tractable, well-known densities. This typically occurs when the prior is conjugate, meaning that the prior and posterior share the same functional form. In Bayesian linear regression, a common conjugate prior on the two parameters β and σ2 is a normal–inverse–gamma distribution,
Since this model is conjugate, we know that the derived posterior must be a normal–inverse–gamma distribution, which we will show. Note that in this model, we learn both β and variance of the noise σ2 by placing a conditional prior on β. These kinds of priors are sometimes called hierarchical. Other conjugate priors might assume either β or σ2 are known.
Conjugate priors often lend themselves to other tractable distributions of interest. For example, the model evidence or marginal likelihood is defined as the probability of an observation after integrating out the model’s parameters,
p(y∣α)=∫∫p(y∣X,β,σ2)p(β,σ2∣α)dPβdσ2.(6)
In the case of (5), α={a0,b0}. As we will see, we can easily compute (6) because we know the normalizing quantities of the normal and inverse–gamma distributions and can therefore compute the integrals in closed-form.
Following the same logic as above, we can also compute the predictive or posterior predictive distribution or the probability of an unseen observation given observed data,
Note that in the term labeled “model”, we condition on the new observations’ predictors. We will see that p(y^∣y) is a multivariate t-distribution under (5). To perform prediction, we take the mean of this distribution. Its variance can be interpreted as how certain the model is of that prediction. Again, this is relatively straightforward to compute because we know the normalizing quantities of the distributions with which we are working.
Now that we have some intuition for the benefits of Bayesian linear regression and tractable conjugate priors, let’s fully derive the posterior, marginal likelihood, and predictive distributions of the model under (5). We’ll look at examples along the way to provide some intuition.
Posterior
We want to show that the normally distributed likelihood can be decomposed into a functional form that looks a lot like a normal–inverse–gamma density. Since we have a normal–inverse–gamma prior, this allows us to consolidate “like terms” to generate a normal–inverse–gamma posterior.
Let’s get into the weeds. Respectively, our likelihood, conditional prior on β, and prior on σ2 are
See (A1) and (A2) for detailed steps arriving at these particular formulations and (A3) for my formulation of the inverse–gamma distribution (it has multiple parameterizations). Now notice that we can decompose the likelihood’s Gaussian kernel and combine it with the prior’s kernel in the following way:
(Note: I use “kernel” to refer to a density in which any constants or terms that are not variables of interest are omitted.) Currently, I don’t think there’s no easy way to intuit (9) and (10). It requires a lot of algebra which I’ve included in (A4) and (A5). I don’t want to clutter the main line of thinking with those derivations, but I do encourage you to read those appendices carefully. That said, the main idea is that we consolidated terms to make a Gaussian kernel that is quadratic in β and moved the remaining terms into an inverse–gamma density, thus generating a posterior that is proportional to a normal–inverse–gamma density.
We can see that we have a P-variate normal distribution on the first line. If we ignore (2π)−N/2 and inverse–gamma prior normalizer, we can combine the bottom two lines to be proportional to an inverse–gamma distribution,
Of course, we have ignored constants and the normalizing evidence because we only care about the shape of the posterior with respect to the model parameters.
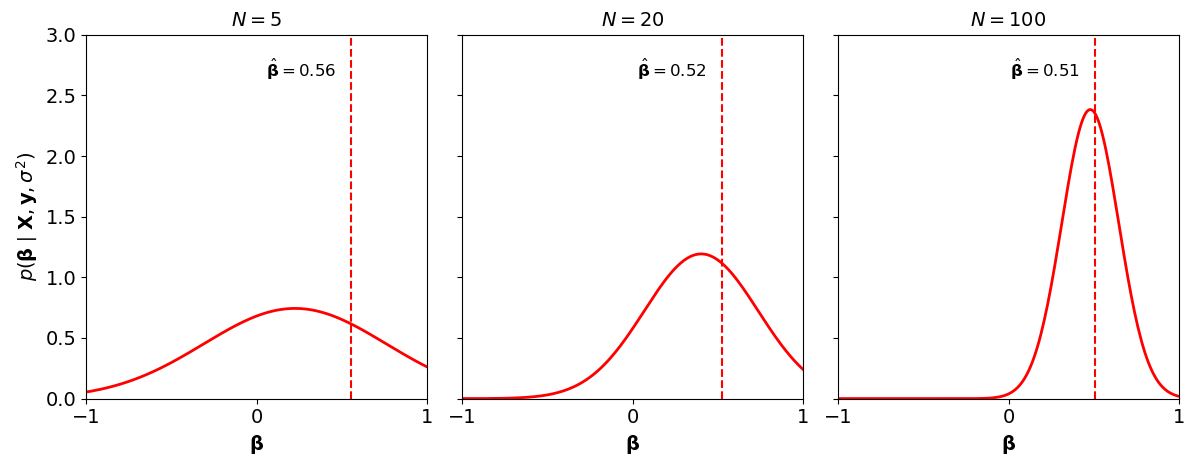
Figure 2. The OLS point estimate of β (dashed red line) and Bayesian linear regression's posterior distribution (solid red line) fit to an increasing number of observations.
To get some intuition for what the posterior represents, consider Figure 2, which compares OLS with Baysesian linear regression on an increasing number of data points. OLS has no notion of uncertainty about its point estimate of β. Bayesian linear regression does; and being regularized by its prior, it requires more data to become more certain about the inferred β. In many models, the MLE and posterior mode are equivalent in the limit of infinite data.
Marginal likelihood
To compute the model evidence or marginal likelihood, we need to compute the following integral,
p(y∣α)=∫∫p(y∣X,β,σ2)p(β,σ2∣α)dPβdσ2(15)
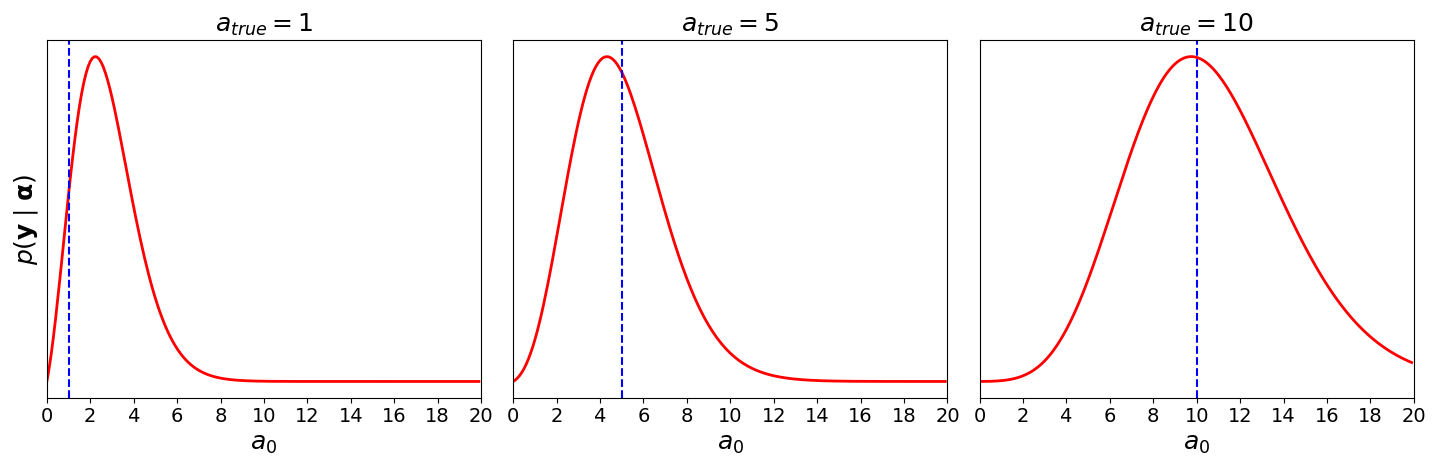
where α={a0,b0}. Note that the integral is high-dimensional since we’re integrating over two variables, one of which is itself high-dimensional. To give some intuition for what this means, consider Figure 3. Each subplot represents the Bayesian linear regression model in (5) fit with different initial values a0. The model was fit to synthetic data that was generated using atrue as the true hyperprior for the inverse–gamma prior on σ2. The other parameter, b0, was fixed. We can see that the model evidence is useful for model comparisons; it tells us how well a particular model—a point on the curve in Figure 3—does relative to other models.
Figure 3. Bayesian linear regression fit with different initial values of a0. In each frame, the data was generated using atrue (dashed blue line) as the true hyperprior for the inverse–gamma prior.
Computing (15) is easier than it looks. First, we can write the integrated terms (the joint) in (15) using the definitions in (10) and (13),
Now notice that since the integral over β is only over the Gaussian kernel. Since we know the normalizer for the multivariate normal, we can compute this immediately:
While this was a bit tedious to write out, it demonstrates the utility of conjugacy and staying within families of well-understood distributions. In general, integrating (15) exactly is intractable, but we handled it easily and without any calculus.
Posterior predictive
In the last two sections, we saw two benefits to a Bayesian approach to linear regression. First, rather than inferring a point estimate for β, we inferred a distribution that quantifies the model’s uncertainty about its estimate. Second, we saw that we can perform model criticism using the marginal likelihood or model evidence. This gives us a principled way to compare models. However, much of the time we are most interested in prediction. Given the data we have seen so far and our parameter estimates, what is our predicted value for a new data point?
We might be tempted to just use the mean of the posterior over β, μN, as our predicted hyperplane. However, we can do something more principled than this using the predictive distribution, sometimes called the posterior predictive distribution. This is the distribution over unobserved data y^, which we can represent by integrating out the model parameters. Let’s rewrite (7) as
I think of (21) as answering the question, “What is the distribution over unseen data given all possible parameter estimates that we could have inferred from seen data?” The integration weights the model’s prediction of new data by the posterior’s parameter estimates from observed data. I believe this really captures what most researchers mean when they say that Bayesian methods “quantify uncertainty”. Our model explicitly encodes how uncertain it is about its parameter estimates using the posterior distribution, and the posterior predictive distribution uses that uncertainty to weight the probability of new observations.
Once again, we can calculate this high-dimensional integral without calculus because of conjugacy. First, the two terms in the integral over β are normally distributed,
Just to be clear, this is an M-variate distribution where M is the number of testing samples in X^. Thus, the posterior predictive can be written as
p(y^∣y)=∫p(y^∣X^,y,σ2)p(σ2∣X,y)dσ2.(24)
Computing the integral over σ2 and simplifying is straightforward—we use the same tricks as above—, but it is rather tedious. Rather than disrupt the main line of thinking, I have included that derivation in (A7). The upshot is that the posterior predictive is an M-variate t-distribution,
Now let’s look at why the posterior predictive is useful. As we just saw, under the model in (5), the predictive p(y^∣y) is a multivariate t-distribution. This means we have closed-form estimates of our predictive distribution’s moments. To understand what this means, consider Figure 4.
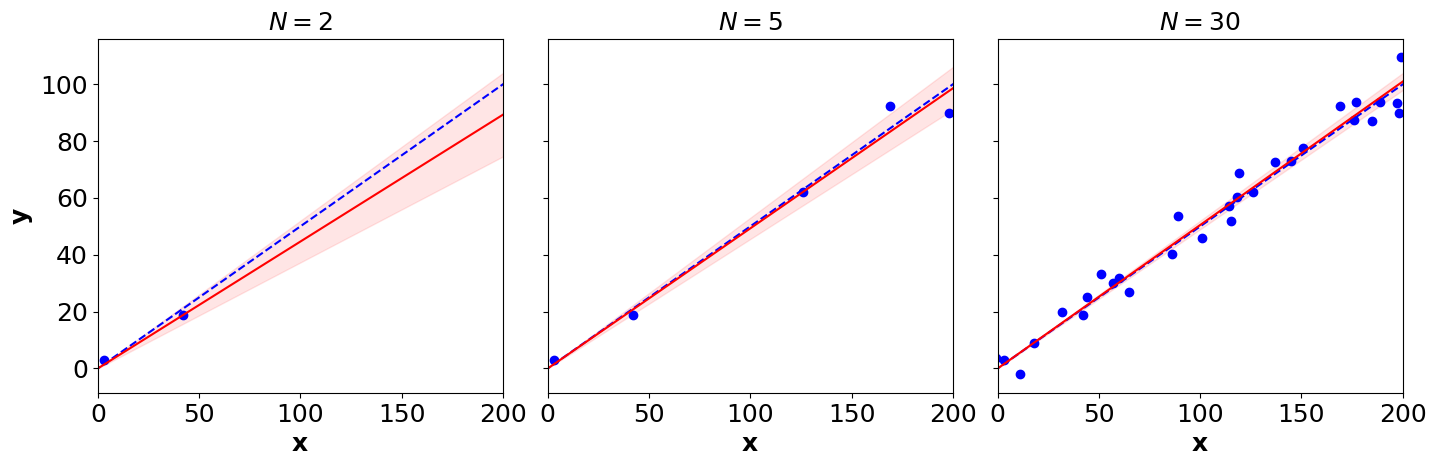
Figure 4. The posterior predictive distribution's mean (solid red line) and two standard deviations from the mean (pink region) after fitting the model in (5) to N data points. The true data generating function is denoted with dashed blue lines.
In each frame, Bayesian linear regression is fit to N data points, and then the mean and two standard deviations around the mean of the posterior predictive distribution are plotted. We can see that the model is less certain in its predictions in regions where it has seen less data or less consistent data. This is a simplified version of Bishop’s Figure 3.8 using the model in (5) rather than Gaussian basis functions. In other words, uncertainty about β is combined with the underlying probabilistic model of the data to generating principled predictions about what new data is plausible.
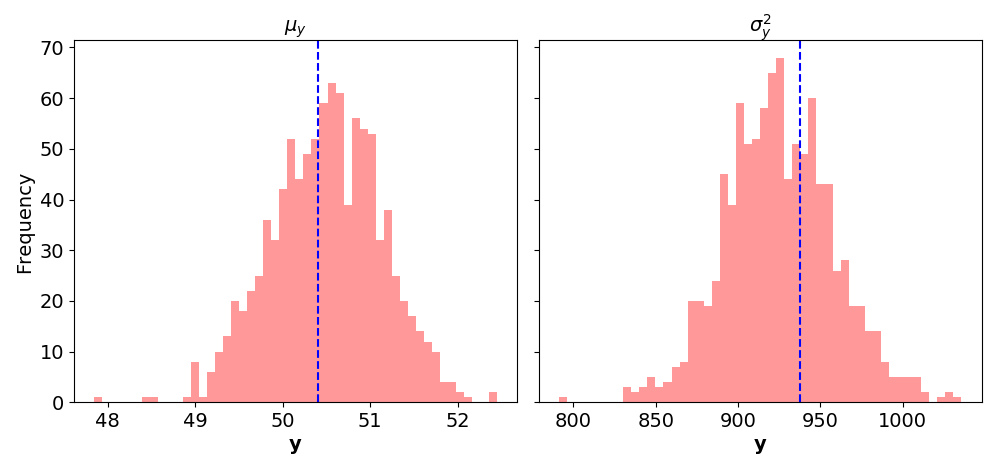
Figure 5. Posterior predictive checks of the mean (left) and variance (right) of the model in (5). The finite sample mean and variance are plotted in blue dashed lines. The histograms are binned over one thousand statistics computed from finite samples from the posterior predictive distribution.
Another use of the posterior predictive is performing posterior predictive checks(Box, 1980). George Box is famous for saying, “All models are wrong, but some are useful.” I think of posterior predictive checks as measuring how good of an approximation of reality our model really is. The basic idea is to draw samples from the posterior predictive distribution and then compare them to our observations. For example, consider Figure 5. Given one hundred observations y=[y1,…y100]⊤, we fit a model. Then we draw a thousand random variables, y^1,…,y^1000, from the posterior predictive distribution. To be clear, this posterior predictive check uses the training data twice. Thus, each y^i is a draw from a 100-variate t-distribution and is therefore itself a 100-dimensional vector. (My understanding is that there is some debate about this (see here for more), but I don’t think it is critical for the main line of thinking. One could easily hold out M observations and sample M-dimensional y^i instead.) Next, for each y^i, we compute the sample mean and sample variance. Finally, we compare a histogram of these means and variances to the observed mean and variance. If our model is a good approximation of reality, these histograms will be tightly centered around the observations.
Conclusion
As this post has probably made clear, exact Bayesian inference is rather tedious. Even when working with simple and well-understood distributions, we had to churn through a lot of derivations using linear algebra and probability to arrive at tractable distributions. However, the Bayesian approach to linear regression is well-motivated. Rather than inferring a point estimate of our parameter β, we infer a distribution over it. The prior acts as a regularizer against overfitting, and the posterior quantifies how certain the model is in its parameter estimates. Furthermore, this approach gives us principled methods for performing model criticism and prediction using the marginal likelihood and posterior predictive distributions.
Acknowledgements
I thank Mathijs de Jong for correcting a mistake in derivation A4.
Appendix
See this GitHub repo for code to reproduce the figures in this post.
The determinant of a diagonal matrix is the product of its diagonal elements, and therefore
∣σ2I∣=(σ2)N.(A1.2)
Furthermore, the inverse of a diagonal matrix is just the inverse of each diagonal element or
[σ2I]−1=⎣⎢⎡1/σ2⋱1/σ2⎦⎥⎤.(A1.3)
Finally, a vector times a diagonal matrix is equivalent to element-wise multiplication of the vector with the diagonal elements. Therefore, we can write
If X is a gamma distributed random variable, denoted X∼Gamma(α,β), its probability density function is
fX(x)=Γ(α)βαxα−1exp(−βx)(A3.1)
where Γ(⋅) is the gamma function. Note that there are alternative parameterizations with different densities. Let Y=g(X)=1/X be another random variable. What is its distribution? We can use a standard technique for transforming a random variable,
Now we want to combine the quadratic-in-β term (labeled A) with the prior’s quadratic-in-β term. The term labeled R1 will be moved to the inverse–gamma’s exponent. We will deal with it later. To be clear, we want to combine,
(β−μ0)⊤Λ0(β−μ0)+(β−β^)⊤X⊤X(β−β^)(A5.2)
into a single term that is quadratic in β. First, expand each square:
What do we do this with the “remainder” terms R2, R3, and R4 that do not fit into our normal distribution’s kernel? Like R1, we will move them to the inverse–gamma prior. Finally, define the mean as
μN=ΛN−1m=ΛN−1(Λ0μ0+X⊤y).(A5.7)
To summarize what we have done so far, we have just shown that
This step requires the properties of matrix inverses and determinants that we used in (A2). The final step is to introduce some aN terms by multiplying the normalizer and quadratic terms by
1=aNM/21aNM/21,1=aNaN(A7.9)
respectively. To make it clear that this is a multivariate t-distribution, we can write it as
Bishop, C. M. (2006). Pattern Recognition and Machine Learning.
Box, G. E. P. (1980). Sampling and Bayes’ inference in scientific modelling and robustness. Journal of the Royal Statistical Society: Series A (General), 143(4), 383–404.