Can Linear Models Overfit?
We know that regularization is important for linear models, but what does overfitting mean in this context? I discuss this question.
If you’re reading this, you probably already know what overfitting means in statistics and machine learning. Overfitting occurs when a model too closely corresponds to training data and thereby fails to generalize on test data. The classic example of this is fitting a high-degree polynomial to linear data (Figure ). Most likely, the high-degree polynomial will have high error on the next data point even though it perfectly fits the training data. One way to think about overfitting is that we have a model that is too complex for the problem, and this complexity allows the model to fit to random noise.
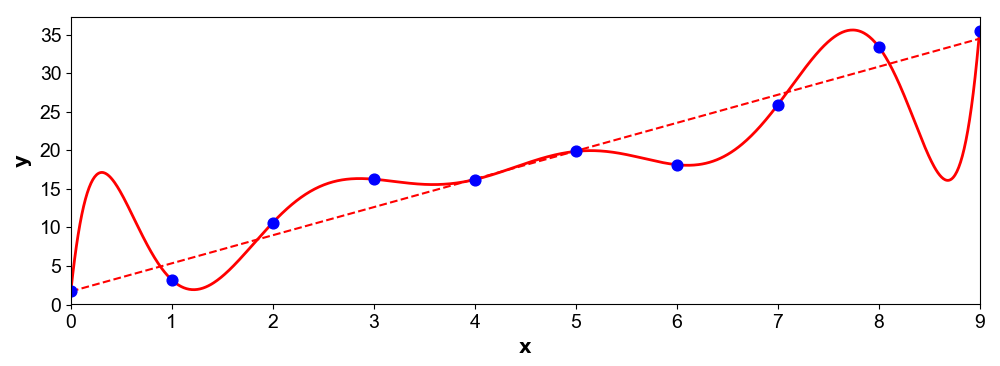
A model that overfits does not adhere to Occam’s razor in its explanation of the data. I think of conspiracy theories as a good example of humans overfitting to data. For example, consider the following conspiracy theory:
Theory: John F. Kennedy was assassinated by aliens.
Is this possible? Sure. So what’s wrong with the theory? Why don’t most people believe this? The theory could be true, but one needs more evidence than is required for simpler explanations, such as that Kennedy was assassinated by Lee Harvey Oswald. Put differently, the alien explanation is more complex than the data we have. If your mental model of the world allows for highly improbable events, you can easily overfit to random noise.
The question I want to address in this post is: can a linear model overfit to data? This will motivate future posts on techniques such as Bayesian priors, Tikhonov regularization, and Lasso.
Overfitting in linear models
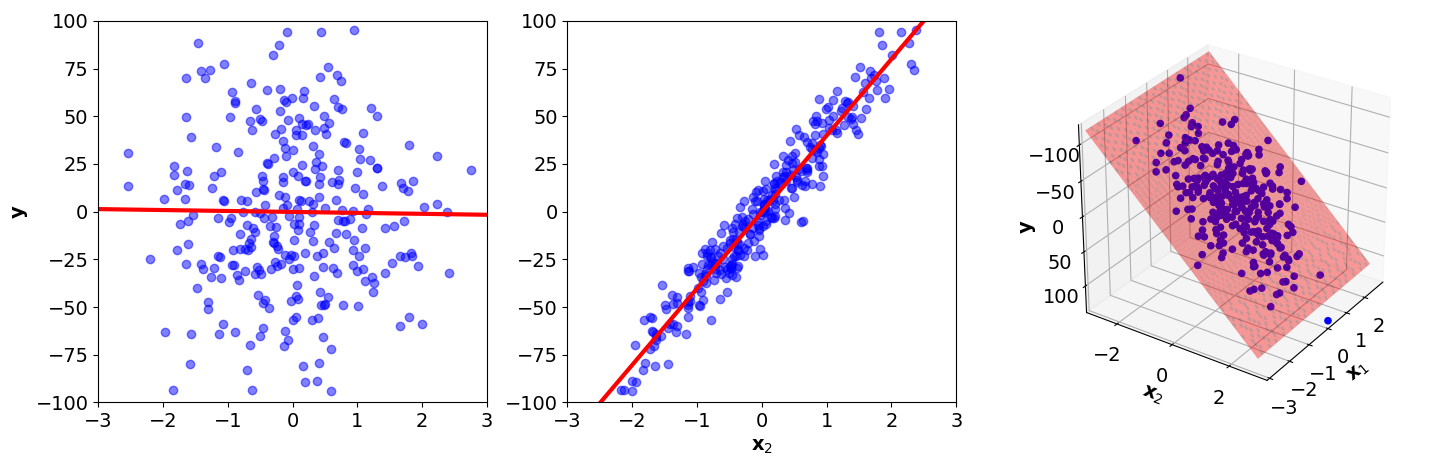
Consider fitting classical linear regression to 2D data in which is uninformative random noise; it is completely uncorrelated with the response values . Our linear model is
Importantly, we are assuming this model is too complex because the true is zero. So while the model in Figure visually looks okay—the linear hyperplane fits to the data quite well—it still exhibits the same kind of overfitting as in Figure . Why? The model is more complex than it needs to be and thereby fits to noise. If we look at the coefficients, we can see this quantitatively:
In Figure , I’ve also drawn the planes defined by just and just to demonstrate that while should be zero, it is not. The ability of this model to generalize will be worse than if were zero.
Shrinkage and priors
Understanding overfitting in linear models—understanding that certain coefficients should be smaller because they just explain noise—motivates regularizing techniques such as shrinkage and Bayesian priors. In my mind, regularization is the process of adding constraints to an under-constrained problem. For example, both convolutional filters (shared weights) in deep neural networks and an penalty on the weights of a model are regularizers. They introduce some inductive bias into the problem so that it is easier to solve.
In linear models, two common forms of regularization are shrinkage methods and Bayesian priors. In shrinkage methods such as Lasso (Tibshirani, 1996) and ridge regression (Tikhonov, 1943), large weights are penalized. We can think of this as encouraging the model to be biased towards small coefficients. A Bayesian prior such as a zero-centered normal distribution on the weights achieves a similar goal: the data must overwhelm the noise. I will discuss these techniques in future posts.
- Tibshirani, R. (1996). Regression shrinkage and selection via the lasso. Journal of the Royal Statistical Society: Series B (Methodological), 58(1), 267–288.
- Tikhonov, A. N. (1943). On the stability of inverse problems. Dokl. Akad. Nauk SSSR, 39, 195–198.