I discuss ordinary least squares or linear regression when the optimal coefficients minimize the residual sum of squares. I discuss various properties and interpretations of this classic model.
Published
04 January 2020
Linear regression
Suppose we have a regression problem with N independent variables xn and N dependent variables yn. Each independent variable is a P-dimensional vector of predictors, while each yn is scalar response or target variable. In linear regression, we assume our response variables are a linear function of our predictor variables. Let β=[β1,…,βP]⊤ denote a P-vector of unknown parameters (or “weights” or “coefficients”) and let εn denote the nth observation’s scalar error term. Then linear regression is
yn=β1xn,1+β2xn,2+⋯+βPxn,P+εn.(1)
Written as vectors, Equation 1 is
yn=β⊤xn+εn.(2)
If we stack the independent variables into an N×P matrix X, sometimes called the design matrix, and stack the dependent variables and error terms into N vectors y=[y1,…,yN]⊤ and ε=[ε1,…,εN]⊤, then we can write the model in matrix form as
y=Xβ+ε.(3)
In classical linear regression, N>P, and therefore X is tall and skinny. We can add an intercept to this linear model by introducing a new parameter β0 and adding a constant predictor as the first column of X. I will discuss the intercept later in this post.
Errors and residuals
Before we discuss how to estimate the model parameters β, let’s explore the linear assumption and introduce some useful notation. Given estimated parameters β^, linear regression predicts
y^≜Xβ^.(4)
However, most likely, our predictions y^ will not match the response variables y exactly. The residuals are the differences in the true response variables y and what we predict or
e≜y−Xβ^.(5)
where e=[e1,…,eN]⊤. Note that the residuals are not the error terms ε. The residuals are the differences in the true response variables y and what we predict, while the errors ε are the differences between the true data Xβ and what we observe,
ε=y−Xβ.(6)
Thus, errors are related to the true data generating process Xβ, while residuals are related to the estimated model Xβ^ (Figure 1). Clearly, if y^=y, then the residuals are zero.
Figure 1. (Left) Ground-truth (un-observed) univariate data xβ, noisy observations y=xβ+ε, and estimated β^. (Middle) Errors ε between ground-truth data xβ and noisy observations y. (Right) Residuals e between noisy observations y and model predictions y^=xβ^.
Normal equation
Now that we understand the basic model, let’s discuss solving for β. Since X is a tall and skinny matrix, solving for β amounts to solving a linear system of N equations with P unknowns. Such a system is overdetermined, and it is unlikely that such a system has an exact solution. Classical linear regression is sometimes called ordinary least squares (OLS) because the best-fit coefficients [β1,…,βP]⊤ are defined as those that solve the following minimization problem:
β^=argβminn=1∑N(yn−xn⊤β)2.(7)
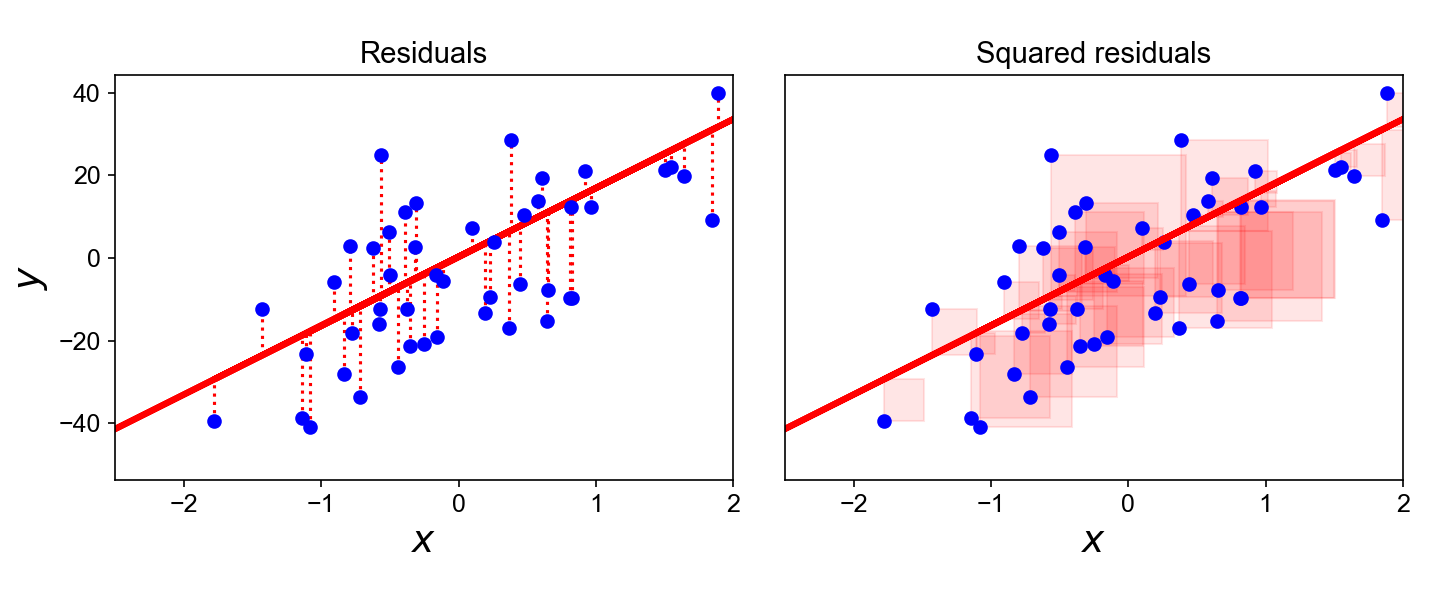
Thus, the OLS estimator β^ minimizes the sum of squared residuals (Figure 2). For a single data point, the squared error is zero if the prediction is exactly correct. Otherwise, the penalty increases quadratically, meaning classical linear regression heavily penalizes outliers. Other loss functions induce other linear models. See my previous post on interpreting these kinds of optimization problems.
Figure 2. Ordinary least squares linear regression on Scikit-learn's make_regression dataset. Data points are in blue. The predicted hyperplane is the red line. (Left) Red dashed vertical lines represent the residuals. (Right) Light red boxes represent the squared residuals.
In vector form, Equation 7 is
β^=argβmin∥y−Xβ∥22.(8)
Linear regression has an analytic or closed-form solution known as the normal equation,
We’ll see in a moment where the name “normal equation” comes from. However, we must first understand some basic properties of OLS. Let’s define a matrix H as
H≜X(X⊤X)−1X⊤.(10)
We’ll call this the hat matrix, since it “puts a hat” on y, i.e. since it regresses the response variables y onto the predicted variables y^:
Hy=X(X⊤X)−1X⊤y=⋆Xβ^=y^(11)
Step ⋆ is just the normal equation (Equation 8). Note that H is an orthogonal projection. See A2 for a proof. Furthermore, let’s call
M≜I−H(12)
the residual maker since it constructs the residuals, i.e. since it makes the residuals from the response variables y:
My=(I−H)y=y−Hy=y−y^=e.(13)
The residual maker is also an orthogonal projector. See A3 for a proof.
Finally, note that H and M are orthogonal to each other:
HM=H(I−H)=H−H=0.(14)
Geometric view of OLS
There is a nice geometric interpretation to all this. When we multiply the response variables y by H, we are projecting y into a space spanned by the columns of X. This makes sense since the model is constrained to live in the space of linear combinations of the columns of X,
and an orthogonal projection is the closest to y in Euclidean distance that we can get while staying in this constrained space. (One can find many nice visualizations of this fact online.) I’m pretty sure this is why the normal equation is so-named, since “normal” is another word for “perpendicular” in geometry.
Thus, we can summarize the predictions made by OLS (Equation 4) by saying that we project our response variables onto a linear hyperplane defined by β^ using the orthogonal projection matrix H.
OLS with an intercept
Notice that Equation 1 does not include an intercept. In other words, our linear model is constrained such that the hyperplane β^ goes through the origin. However, we often want to model a shift in the response variable, since this can dramatically improve the goodness-of-fit in the model (Figure 3). Thus, we want OLS with an intercept.
Figure 3. OLS without (red solid line) and with (red dashed line) an intercept. The model's goodness-of-fit changes dramatically depending on this modeling assumption.
In this section, I’ll discuss both partitioned regression or OLS when the predictors and corresponding coefficients can be logically separated into groups via block matrices and then use that result for the specific case when one of the block matrices in the design matrix X is a constant, i.e. a constant term for an intercept.
Partitioned regression
Let’s rewrite Equation 3 by splitting X and β into block matrices. Let X=[X1,X2] (we’re stacking the columns horizontally) and β=[β1,β2]⊤ (we’re stacking the rows vertically). Then partitioned regression is,
y=[X1X2][β1β2]+ε.(16)
The normal equation (Equation 9) can then be written as
And we have solved for β^2 in terms of the residual maker for X1, denoted M1:
β^2=(X2⊤M1X2)−1X2⊤M1y.(23)
As we’ll see in the next section, solving for β^2 in terms of M1 will be make it easier to understand and compute the optimal parameters of OLS with an intercept.
The results in Equations 19 and 23 are part of the Frisch–Waugh–Lovell (FWL) theorem. The basic idea of the FWL theorem is that we can obtain β^2 by regressing M1y onto M1X2, where these variables are just the residuals associated with X1. See (Greene, 2003) for further discussion.
Partitioned regression with a constant predictor
OLS with an intercept is just a special case of partitioned regression. Suppose that we add an intercept to our OLS model. This means we want to estimate a new parameter β0 such that
yn=β0+xn⊤β+εn.(24)
Notice that if we simply add a constant to our predictor xn, we can “push” β0 into the dot product. In matrix notation, we have
which is the same equation as Equation 3 but with a column of ones prepended to X. This means we can write our model as
y=1β1+X2β2+ε.(26)
We can use the results of the previous subsection to straightforwardly solve for the scalar β1 and the P-vector β2. First, note that the hat matrix H1 is just an N×N matrix filled with the value 1/N:
or the mean of a column of X. Thus, we are just mean centering X2 in the calculation X2−Xˉ2. This gives us
β^2={X2⊤(X2−Xˉ2)}−1X2⊤(y−y^).(31)
In other words, when OLS has an intercept, the optimal coefficients β2^—which are the parameters associated with the predictors in our design matrix—are just the result of the normal equation after mean-centering our targets and predictors. Intuitively, this means that the hyperplane defined by just β2^ goes through the origin (Figure 4).
Figure 4. OLS with an intercept (solid line) can be decomposed into OLS without an intercept (dashed-and-dotted line) and a bias term (dashed line). Without an intercept, OLS goes through the origin. With an intercept, the hyperplane is shifted by the distance between the original hyperplane and the mean of the data.
Finally, we can solve for the scalar β^1—which is really the intercept parameter β0 in Equation 24—as
where xˉ2 is a row of Xˉ2, i.e. a vector of means for each predictor. The interpretation of this bias parameter (Equation 32) becomes more clear if we diagram these quantities (Figure 4). As we can see, OLS with an intercept can be decomposed into OLS without an intercept, where the hyperplane defined by β^2 passes through the origin, and the bias parameter β1 (again elsewhere denoted β0), which shifts the hyperplane from the origin to the mean of the response variables.
A probabilistic perspective
OLS can be viewed from a probabilistic perspective. Recall the linear model
yn=xn⊤β+εn.(33)
If we assume our error εn is additive Gaussian noise, εn∼N(0,σ2), then this induces a conditionally Gaussian assumption on our response variables,
p(yn∣xn,β,σ2)=N(yn∣xn⊤β,σ2).(34)
If our data is i.i.d., we can write
p(y∣x,β,σ2)=n=1∏NN(yn∣xn⊤β,σ2).(35)
In this statistical framework, maximum likelihood (ML) estimation gives us the same optimal parameters as the normal equation. To compute the ML estimate, we first take derivative with respect to the parameter of the log likelihood function and then solve for β. We can represent the log likelihood compactly using a multivariate normal distribution,
See A4 for a complete derivation of Equation 36. If we take the derivative of this log likelihood function with respect to the parameters, the first term is zero and the constant 1/2σ2 does not effect our optimization. Thus, we are looking for
β^MLE=argβmax{−(y−Xβ)⊤(y−Xβ)}.(37)
Of course, maximizing the negation of a function is the same as minimizing the function directly. Thus, this is the same optimization problem as Equations 7 and 8.
Furthermore, let β0 and σ02 be the true generative parameters. Then
E[y∣X]V[y∣X]=Xβ0=σ02I.(38)
See A5 for a derivation of Equation 38. Since we know that the conditional expectation is the minimizer of the mean squared loss—see my previous post if needed—, we know that Xβ0 would be the best we can do given our model. An interpretation of the conditional variance in this context is that it is the smallest expected squared prediction error.
Conclusion
Classical linear regression or ordinary least squares is a linear model in which the estimated parameters minimize the sum of squared residuals. Geometrically, we can interpret OLS as orthogonally projecting our response variables onto a hyperplane defined by these linear coefficients. OLS typically includes an intercept, which shifts the hyperplane so that it goes through the targets’ mean, rather than through the origin. In a probabilistic view of OLS, the maximum likelihood estimator is equivalent to the solution to the normal equation.
Acknowledgements
I thank Andrei Margeloiu for correcting an error in an earlier version of this post. When y^=y, the residuals are zero, but the true errors are still unknown.
Appendix
A1. Normal equation
We want to find the parameters or coefficients β that minimize the sum of squared residuals,
β^=argβmin∥y−Xβ∥22.(A1.1)
Note that we can write
∥y−Xβ∥22=(y−Xβ)⊤(y−Xβ).(A1.2)
This can be easily seen by writing out the vectorization explicitly. Let v be a vector such that
The squared L2-norm ∥v∥22 is the sums the squared components of v. This is equivalent to taking the dot product v⊤v. Now define the function J(⋅) such that
J(β)=∥y−Xβ∥22.(A1.4)
To minimize J(⋅), we take its derivative with respect to β, set it equal to zero, and solve for β,
In step 4, we use the fact that the trace of a scalar is the scalar. In step 5, we use the linearity of differentiation and the trace operator. In step 6, we use the fact that tr(A)=tr(A⊤). In step 7, we take the derivatives of the left and right terms using identities 108 and 103 from (Petersen et al., 2008), respectively.
If we set line 7 equal to zero and divide both sides of the equation by two, we get the normal equation:
X⊤Xβ=X⊤y.(A1.6)
A2. Hat matrix is an orthogonal projection
A square matrix is a projection if A=A2. Thus, the hat matrix H is a projection since
A real-valued projection is orthogonal if A=A⊤. Thus, the hat matrix H is an orthogonal projection since
H⊤=(X(X⊤X)−1X⊤)⊤=(X⊤)⊤[(X⊤X)−1]⊤X⊤=H.(A2.2)
A3. Residual maker is an orthogonal projector
A square matrix A is a projection if A=A2. For the residual maker M, we have:
M2=(I−H)(I−H)=I−H−H+H2=⋆I−H=M.(A3.1)
Step ⋆ holds because we know that the hat matrix H is an orthogonal projector. A real-valued projection A is orthogonal if A=A⊤. For the residual maker M, we have:
M⊤=(I−H)⊤=I⊤−H⊤=†I−H.(A3.2)
Again, step † holds because H is an orthogonal projector. Therefore, M is an orthogonal projector.
A4. Multivariate normal representation of the log likelihood
The probability density function for a D-dimensional multivariate normal distribution is
The mean parameter μ is a D-vector, and the covariance matrix Σ is a D×D positive definite matrix. In the probabilistic view of classical linear regression, the data are i.i.d. Therefore, we can represent the likelihood function as
The above formulation leverages two properties from linear alegbra. First, if the dimensions of the covariance matrix are independent (in our case, each dimension is a sample), then Σ is diagonal, and its matrix inverse is just a diagonal matrix with each value replaced by its reciprocal. Second, the determinant of a diagonal matrix is just the product of the diagonal elements.