Laplace's method is used to approximate a distribution with a Gaussian. I explain the technique in general and work through an exercise by David MacKay.
Published
08 May 2019
The motivation for Laplace’s method (Laplace, 1774) is more general than our goal of density estimation, and it is worth exploring. Suppose we want to approximate an integral of the form
∫abekf(x)dx(1)
where f(x) is a twice differentiable function with a global maximum at x0, k>0 and is ideally large, and the endpoints a and b can be infinite. Consider this ratio,
ekf(x)ekf(x0)=ek(f(x0)−f(x))
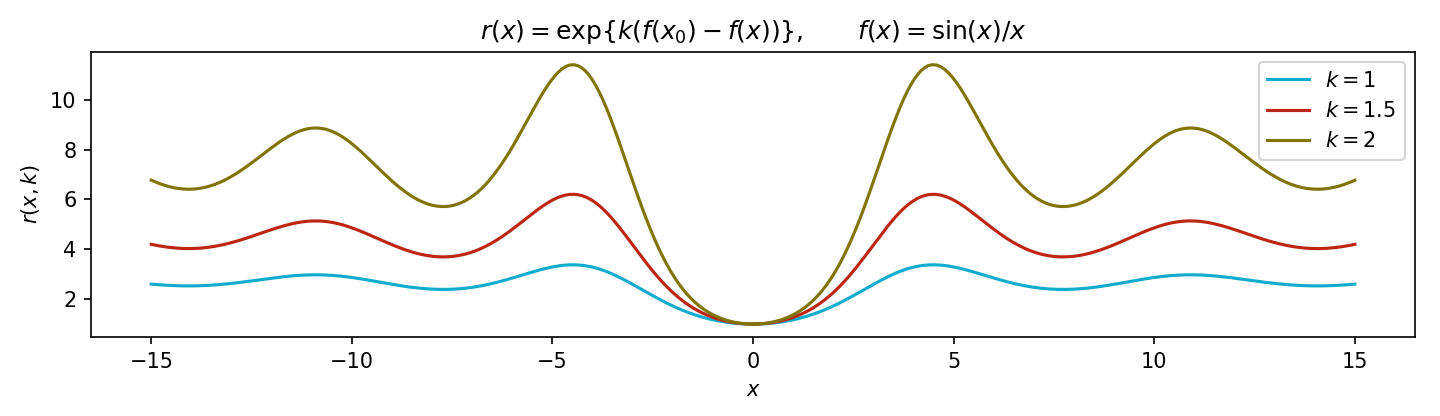
which increases exponentially as k increases linearly. So for large k, the difference between the maximum point and the rest of the function is accentuated (Figure 1).
Figure 1: Let f(x)=sin(x)/x. Then x0=0 and limx→x0f(x)=1. As k increases, the ratio r(x)=exp{k(f(x0)−f(x))} increases exponentially.
This observation about the behavior of ekf(x) is what motivates Laplace’s method, and it suggests that we can approximate f(x) using a Taylor expansion around x0,
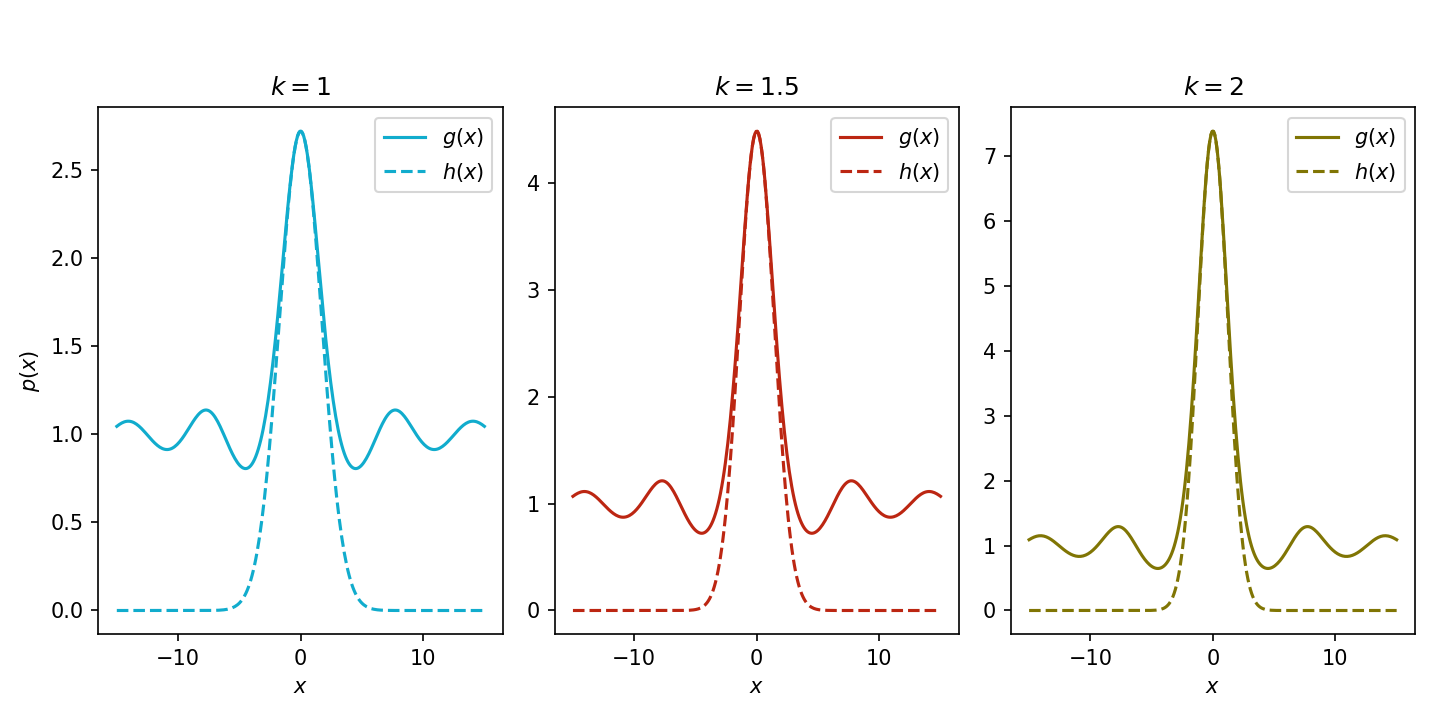
Figure 2 shows the function ekf(x) and the approximation for varying values of k. This captures our earlier point, which is that as k increases, the function ekf(x) becomes more peaked around x0, and thus our Taylor-expanded approximation improves.
Figure 2: Let f(x)=sin(x)/x, g(x)=ekf(x), and h(x)=exp(f(x0)+2f′′(x0)(x−x0)2). The panels compare g(x) to its approximation h(x) for k∈{1,1.5,2}.
At this point, you might have already noticed that our approximation (Equation 2), if appropriately normalized, is just the Gaussian PDF centered at x0. Since x0 is a maximum, f′′(x0)<0 (recall the Second Derivative Test) and thus f′′(x0)=−∥f′′(x0)∥. We can approximate Equation 1 as,
This is a Gaussian integral if a=−∞ and b=∞, and is a Gaussian density if appropriately normalized. This is precisely what motivates Laplace’s method for density approximation.
Density approximation
Now consider the goal of approximating a distribution, ideally unimodal, with a Gaussian. Now our unnormalized density is f(x), and the normalized density is p(x)=Z1f(x) where Z is unknown. The mode or peak of this distribution occurs at the maximum x0.
Let’s Taylor-expand lnf(x) around the point x0. If we write the negative of the second derivative in the second-order term as A and drop the higher-order terms, then
If we are estimating parameters, then x0 is just the maximum likelihood or maximum a posteriori (MAP) estimate, and A is just the negative log likelihood evaluated at the optimal parameter. Thus, we can approximate p(x) with an unnormalized density q∗(x) such that,
q∗(x)≜f(x0)exp{−2A(x−x0)2}
Since we assume q∗(x) is Gaussian, A=1/σ2, and the normalizing constant is
Zq≜2πf(x0)A1
Putting it together, the normalized density q(x) is
p(x)≈q(x)=Zqq∗(x)=2πAexp{−2A(x−x0)2}.
Notice that in density estimation, k is not free parameter because we want our integral to integrate to 1.
We can generalize Laplace’s method to a p-dimensional Gaussian random vector x. Let the constant A from the previous section be a Hessian matrix A such that
Aij=−∂xi∂xj∂2lnf(x)∣∣∣∣x=x0.
Then the approximation in Equation 3 is
lnf(x)≈lnf(x0)−21(x−x0)⊤A−1(x−x0).
and the normalizing constant is
Zq≜2πf(x0)det(A)1.
This is derived from the standard form a multivariate Gaussian with A in place of the covariance matrix Σ. The normalized density is
Thus, we have seen that Laplace’s method places a Gaussian at the mode of the approximated distribution and matches the curvature of the density around that point.
A photon counter is pointed at a remote star for one minute, in order to infer the rate of photons arriving at the counter per minute, λ. Assuming the number of photons collected r has a Poisson distribution with mean λ,
P(r∣λ)=exp(−λ)r!λr,
and assuming the improper prior P(λ)=1/λ, make Laplace approximations to the posterior distribution over λ.
First, since we have a prior, note that λ0=λMAP. The posterior is
This is a Gaussian with a mean and variance of r−1,
p(λ∣r)≈N(λ;r−1,r−1)
and we’re done.
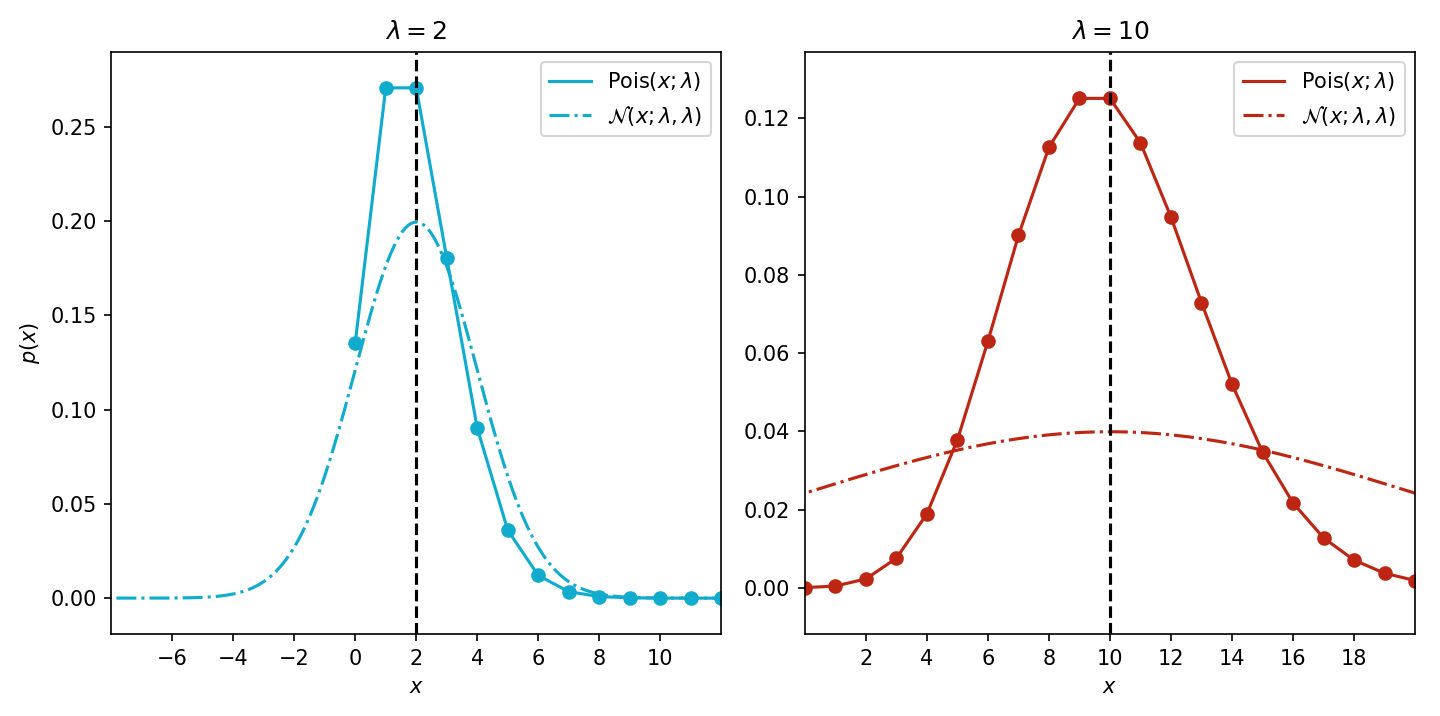
As a final warning, observe that a Gaussian approximation is often suboptimal. For example, we just derived a Gaussian distribution that has an identical mean and variance. For ease of visualization, let’s recalculate our Laplace approximation of just the Poisson distribution without the improper prior from MacKay. We can see that the approximation gets worse as λ gets bigger (Figure 3).
Figure 3: Laplace approximations of Pois(x∣λ) for λ∈{2,10}. Since each Gaussian approximation has both a mean and a variance that are functions of λ, the variance of the Gaussian approximation quickly blows up when λ is large.
This is due to the fact that the Gaussian approximation has both a mean and a variance of λ, and its spread increases faster than the Poisson distribution’s.
Laplace, P. S. (1774). Mémoire sur la probabilité des causes par les événements. Mém. De Math. Et Phys. Présentés à l’Acad. Roy. Des Sci, 6, 621–656.