Conjugacy in Bayesian Inference
Conjugacy is an important property in exact Bayesian inference. I work though Bishop's example of a beta conjugate prior for the binomial distribution and explore why conjugacy is useful.
In Bayesian inference, a prior is conjugate to the likelihood function when the posterior has the same functional form as the prior. This means that the two boxed terms in Bayes’ formula below have the same functional form:
The goal of this post is to work through an example of a conjugate prior to better understand why conjugacy is a useful property.
As a running example, imagine that we have a coin with an unknown bias. Estimating the bias is statistical inference; Bayesian inference is assuming a prior on ; and conjugacy is assuming the prior is conjugate to the likelihood. We will explore these ideas in order.
Modeling a Bernoulli process
We want to estimate the bias of our coin. First, we flip the coin times. The outcome of the th coin toss is , a Bernoulli random variable that takes values or with probability or respectively. Without loss of generality, is a success (heads) and is a failure (tails). The sequence of coin flips is a Bernoulli process of i.i.d. Bernoulli random variables, . Let be these coin flips or , and let be the number of successes.
The probability of successes in trials is a binomial random variable or
In words, is the probability of successes and failures, all independent, in a single sequence of coin flips, and the binomial coefficient is the number of combinations of coin flips that can have successes and failures.
Being statisticians, we estimate by maximizing the likelihood of the data given the parameter or by computing
where the series of products is due to our modeling assumption that coin flips are independent. We then take the log of this—maximizing the log of a function is equivalent to maximize the function itself and logs allow us to leverage the linearity of differentiation—to get
Finally, to solve for the value of that maximizes this function, we compute the derivative of with respect to , set it equal to , and solve for . The derivative is
Note that the normalizer disappears because it does not depend on . Solving for when the derivative is equal to , we get
Now this works. But imagine that we flip the coin three times and each time it comes up heads. Assuming the coin is actually fair, this happens with probability , but our maximum likelihood estimate of is . In other words, we are overfitting. One way to address this is by being Bayesian, meaning we want to place a prior probability on . Rather than maximizing , we want to maximize
Intuitively, imagine that most coins are fair. Then even if we see three heads in a row, we want to incorporate this prior knowledge about what typically is into our model. This is the role of a Bayesian prior .
A beta prior
What sort of prior should we place on ? Let’s make two modeling assumptions. First, let’s assume that most coins are fair. This means that should be the mode of the distribution. And let’s assume that biased coins do not favor heads over tails or vice versa. This means we want a symmetric distribution. One distribution that may have these properties is the beta distribution, given by
where is the gamma function
and normalizes the distribution. The beta distribution is normalized so that
and has a mean and variance given by
The hyperparameters and (so-named because they are not learned like the parameter ) control the shape of the distribution (Figure ). Given our modeling assumptions, hyperparameters seem reasonable.
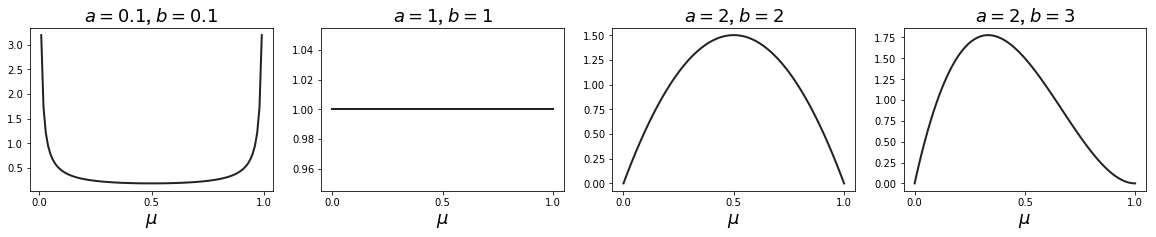
But another useful fact of the beta distribution—and the reason we picked it over the more obvious Gaussian distribution as our prior—is that it is conjugate to our likelihood function. Let’s see this. Let be the number of failures. If we multiply our likelihood (Equation ) by our prior (Equation ), we get a posterior that has the same functional form as the prior:
Note that we only care about proportionality because is a constant that is independent of the parameter we want to learn and our data. We can see that our posterior is another beta distribution, and we can easily normalize it:
Finally, we now want to maximize Equation rather than Equation . Recall that this is maximum a posteriori (MAP) estimation because, unlike maximum likelihood estimation, we account for a prior. Because this new posterior is in a tractable form, it is straightforward to compute . Let’s first compute the derivative of our new log likelihood with respect to :
where is the normalizing constant as in the previous section. Setting this equal to and doing some algebra, we get
Note that if , then . In words, if we can’t flip a coin to estimate its bias, then the best we can do is assume the bias is the mode of our prior. And recall our small pathological example from before, the scenario when both and . With our prior with hyperparameters , we have
This demonstrates why the prior is especially important for parameter estimation with small data and how it helps prevent overfitting.
Benefits of conjugacy
I want to discuss two main benefits of conjugacy. The first is analytic tractability. Computing was easy because of conjugacy. Imagine if our prior on was the normal distribution. We would have had to optimize
where and are hyperparameters for the normal distribution. In the absence of techniques such as variational inference, conjugacy makes our lives easier.
The second benefit of conjugacy is that it lends itself nicely to sequential learning. In other words, as the model sees more data, the posterior at step can become the prior at step . We simply need to update our prior and re-normalize. For example, imagine we process individual coin flips one at a time. Every time we see a heads (), we increment and . Otherwise, we increment and . Alternatively, we could fix and just increment and respectively (Equation ).
Using this technique, we can visualize the posterior over sequential observations (Figure ).
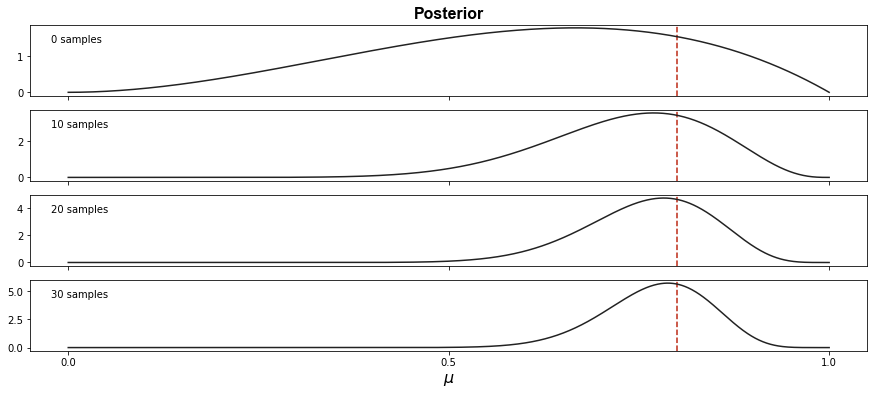
The upshot is that the posterior distribution becomes more and more peaked around the true bias as our model sees more data. Note that the -axes are at different scales and therefore the last frame is even more peaked than the second-to-last frame. Also note that the posterior is slightly underestimating the true parameter , possibly because of the influence of the prior.
Conclusion
Conjugate priors are an important concept in Bayesian inference. Especially when one wants to perform exact Bayesian inference, conjugacy ensures that the posterior is tractable even after multiplying the likelihood times the prior. And they allow for efficient inference algorithms because the posterior and prior share the same functional form.
As a final comment, note that conjugacy is with respect to a particular parameter. For example, the conjugate prior of a Gaussian with respect to its mean parameter is another Gaussian, but the conjugate prior with respect to its variance is the inverse gamma. The conjugate prior with respect to the multivariate Gaussian’s covariance matrix is the inverse-Wishart, while the Wishart is the conjugate prior for its precision matrix (Wikipedia, 2019). In other words, the conjugate prior depends on the parameter of interest and what form that parameter takes.
Acknowledgements
I borrowed some of this post’s outline and notation from Bishop’s excellent introduction to conjugacy (Bishop, 2006). See pages specifically.
- Wikipedia. (2019). Conjugate prior. URL: Https://En.wikipedia.org/Wiki/Conjugate_prior/.
- Bishop, C. M. (2006). Pattern Recognition and Machine Learning.