Random Noise and the Central Limit Theorem
Many probabilistic models assume random noise is Gaussian distributed. I explain at least part of the motivation for this, which is grounded in the Central Limit Theorem.
Gaussian noise is ubiquitous in modeling. For example, Bayesian linear regression, probabilistic PCA, Bayesian matrix factorization, and many signal processing models all assume some additive noise term for some model-specific and . But why do we assume that random noise is Gaussian? There are two answers to this question. First, the Gaussian distribution has some very nice analytic properties. For example, the sum of two independent Gaussian random variables is also Gaussian and a linear map on a Gaussian distribution produces another Gaussian distribution. But second, the Central Limit Theorem motivates the idea that random noise will most likely be Gaussian. When I first heard this second justification, it was not immediately clear why. The goal of this post is to describe the Central Limit Theorem in detail and then explain how it relates to assuming random noise is Gaussian distributed.
The Central Limit Theorem
The Central Limit Theorem (CLT) is arguably one of the most important ideas in probability and statistics because its implications are widespread. The CLT states that, under certain conditions, the sampling distribution of a normalized sum of independent random variables, themselves not necessarily normally distributed, tends towards a normal distribution. There is a lot in that sentence, and it is worth unpacking slowly. In various research conversations, I have heard people casually evoke the CLT as meaning that “everything is Gaussian”, but this is a little sloppy. The statement is more precise, with important implications in that precision.
First, let us formalize things. Let denote the th draw of a random variable. Note that is the random variable before sampling, meaning it is still a random variable and not fixed. And let be a random variable representing the average of such draws:
The CLT’s claim is not about an but rather after normalization.
There are many different variants of the CLT. For example, the De Moivre–Laplace theorem is a special case of the CLT. For simplicity, I begin with the first one presented on Wikipedia, the self-contained Lindeberg–Lévy CLT (Lindeberg, 1922), which states
Lindeberg–Lévy CLT: Suppose is a sequence of i.i.d. random variables with and . Then as approaches infinity, the random variables converge in distribution to a normal .
But what is this random variable ? Didn’t we just say that the CLT is about ? To see the connection, let’s do a little manipulation. First, since , then
So the term is simply mean-centering the random variable .
And what is the variance of ? Note that for independent random variables and , . This makes sense. Since the random variables are uncorrelated, the total variance—our total uncertainty about what values they might each take—is the sum of variances. And if is a scalar, then . So
Now if you want to normalize a Gaussian random variable to be distributed, you need to mean center the random variable and divide by the standard deviation:
And this random variable is distributed as
which is equivalent to the Lindeberg–Lévy CLT.
I think it’s worth mentioning why the Lindeberg–Lévy CLT takes the form it does, namely that the random variable approaches . First, while and are both approximately Gaussian distributed, their means and variances are functions of , and therefore these two random variables do not converge to a particular distribution. Furthermore, my guess is that the Lindeberg–Lévy CLT mentions converging to rather than because it makes clear that this normalized random variable converges to a Gaussian distribution with the same variance as the original random variable.
Intuition for the CLT
Now that we know what the CLT claims, we can play with it a little bit. (I typically start with intuition, but in this case, I found that defining things really helped me understand which random variable was Gaussian distributed.) The CLT claims that if we draw i.i.d. random variables from a wide class of distributions with a first moment and second moment , the random variable is distributed. Let’s empirically test this.
For this experiment, let’s use the uniform distribution, . First, let’s look at the distribution of where each . The reason we want to look at rather than is that it is easier to see the Gaussian distribution “peaking” if it is un-normalized (Figure ).
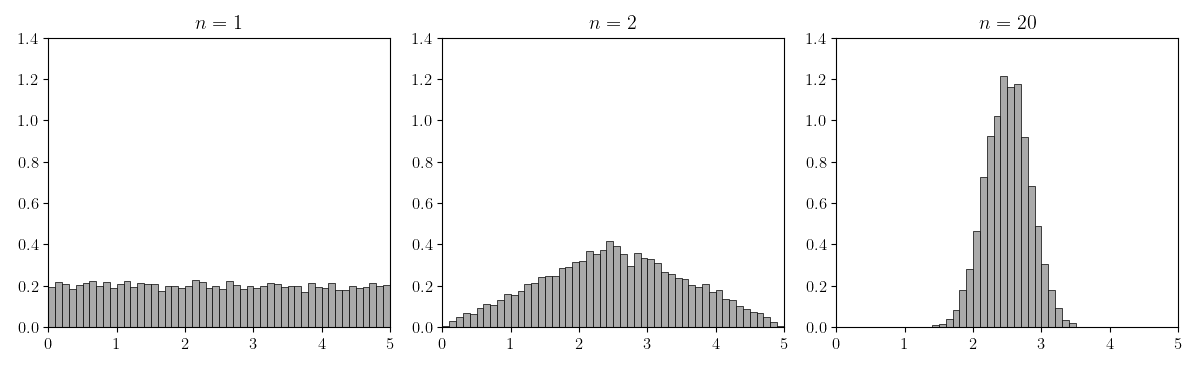
In Figure , we can see that when , the histogram looks like the uniform distribution. But as increases, the histogram of the random variable looks more and more Gaussian distributed. The minimal example in Python to generate this figure is in the Appendix.
Of course, Figure does not precisely demonstrate what is stated in the Lindeberg–Lévy CLT. We really should normalize and verify that converges to for the normal distribution with second moment (Figure ).
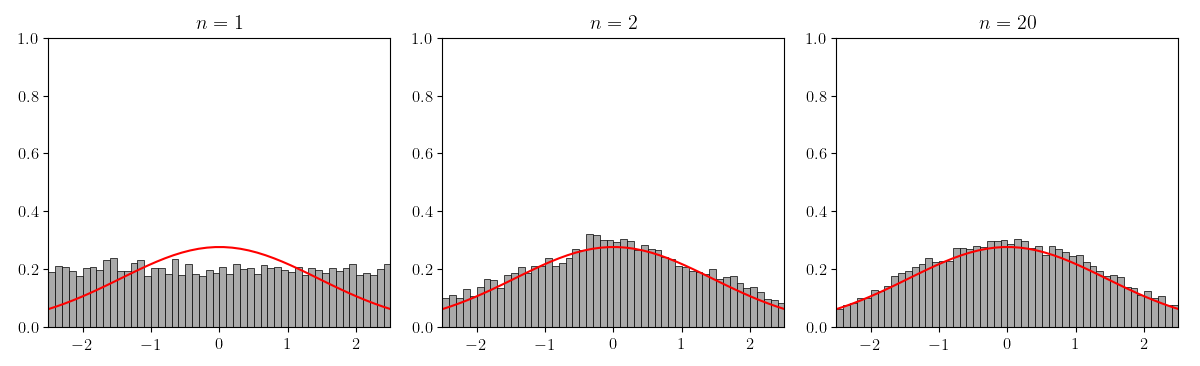
The Lyapunov CLT
Lindeberg–Lévy CLT has two conditions for our random variables. The random variables must (1) be i.i.d. and (2) have finite variance. If either of these conditions is not met, the CLT is not guaranteed to hold. For example, consider the Cauchy distribution, which is pathological in the sense that both its first and second moments are undefined, i.e. . If you take the code in the Appendix and re-run it with np.random.standard_cauchy, you will find that is not Gaussian distributed.
But it is noteworthy that while the samples must be independent, they need not be identically distributed. After reading the Lindeberg–Lévy CLT, I assumed the data must be identically distributed, but I could not convince myself why. To understand my thinking, consider some sequence of random variables,
where and denote differently distributed random variables. If we just re-order these random variables and re-number them, we get:
where is the number of samples and is the number of samples. Clearly by the Lindeberg–Lévy CLT, the sums and are Gaussian distributed, and since these random variables are independent, their sums must be Gaussian distributed. After some searching, I realized that this has already been proven and is the Lyapunov CLT which states that the random variables must be independent but not necessarily identically distributed.
In my mind, this is an important generalization for understanding why noise is so often modeled as Gaussian distributed.
Additive Gaussian noise
Now that we understand the Lyapunov CLT, the assumption that noise is Gaussian starts to make sense. Noise is not one thing but rather the byproduct of interference from potentially many different sources. Let’s think of an example. Imagine a Bluetooth speaker receiving a signal from your laptop. In this context, noise can be many things: a microwave oven with a similar radio frequency, sensor errors due to overheating, physical interference as you pick up the speaker, and so on. Each of these sources of noise can be thought of as interferring with or being added to the true signal from your laptop. And while these sources of noise are neither Gaussian distributed nor identically distributed in general, their total effect can be plausibly modeled as a single Gaussian random variable—or additive Gaussian noise.
Appendix
1. Code to generate Figure 1
import numpy as np
import matplotlib.pyplot as plt
a = 0
b = 5
reps = 2000
fig, axes = plt.subplots(1, 3)
for n, ax in zip([1, 2, 20], axes.flat):
rvs = [np.random.uniform(a, b, n).mean() for _ in range(reps)]
ax.hist(rvs, density=True)
plt.show()
- Lindeberg, J. W. (1922). Eine neue Herleitung des Exponentialgesetzes in der Wahrscheinlichkeitsrechnung. Mathematische Zeitschrift, 15(1), 211–225.