Randomized Singular Value Decomposition
Halko, Martinsson, and Tropp's 2011 paper, "Finding structure with randomness: Probabilistic algorithms for constructing approximate matrix decompositions", introduces a modular framework for randomized matrix decompositions. I discuss this paper in detail with a focus on randomized SVD.
1. Introduction
Many standard algorithms for dealing with matrices, such as matrix multiplication and low-rank matrix approximation, are expensive or intractable in large-scale machine learning and statistics. For example, given an matrix where both and are large, a method such as singular value decomposition (SVD) will require memory and time which is superlinear in and (Drineas et al., 2006).
A growing area of research, randomized numerical linear algebra (RandNLA), combines probability theory with numerical linear algebra to develop fast, randomized algorithms with theoretical guarantees that such algorithms are, in some sense, a good approximation of some full computation (Drineas & Mahoney, 2016) (Mahoney, 2016). The main insight is that randomness is an algorithmic resource creating efficient, unbiased approximations of nonrandom operations.
A seminal paper in RandNLA, “Finding structure with randomness: Probabilistic algorithms for constructing approximate matrix decompositions” by Halko, Martinsson, and Tropp (Halko et al., 2011), demonstrated that a modular framework could be used for randomized matrix approximations. The goal of this post is to deeply understand this paper, with a particular focus on randomized SVD. I present Halko et al’s modular framework through the randomized SVD algorithm, walk the reader through a few theoretical results, and reproduce a couple numerical experiments.
This post is organized as follows. In Section 2, I introduce randomized SVD through the lens of Halko et al’s general framework for low-rank matrix approximations. This motivates Section 2.2, in which I discuss randomized range finders. These are the probabilistic crux of the paper. Sections 2.3–2.5 cover theory and algorithmic improvements. In Section 3, I discuss the key numerical results of the paper and demonstrate that I am able to both implement randomized SVD and reproduce these results.
2. Randomized SVD
2.1. Two-stage framework
Consider the general problem of low-rank matrix approximation. Given an matrix , we want and matrices and such that and . To approximate this computation using randomized algorithms, Halko et al propose a two-stage computation:
-
Step 1: Compute an approximate basis for the range of . We want a matrix with orthonormal columns () that captures the action of . Formally, .
-
Step 2: Given such a matrix —which is much smaller than —use it to compute our desired matrix factorization.
In the case of SVD, imagine we had access to . Then randomized SVD is the following:
Algorithm 1. Randomized SVD
Given an orthonormal matrix s.t.
- Form
- Compute the SVD of , i.e.
- Set .
- Return
The efficiency of this algorithm comes from being small relative to . Since , setting produces a low-rank approximation, .
Note that randomness only occurs in Step 1 and that Step 2 is deterministic given . Thus, the algorithmic challenge is to efficiently compute through randomized methods. Halko et al present several algorithms to do this, called randomized range finders.
2.2. Randomized range finders
The goal of a randomized range finder is to produce an orthonormal matrix with as few columns as possible such that
for some desired tolerance .
Halko et al’s solution is motivated by Johnson and Lindenstrauss’s seminal paper (Johnson & Lindenstrauss, 1984) that showed that pairwise distances among a set of points in a Euclidean space are roughly maintained when projected into a lower-dimensional Euclidean space. The basic idea is to draw Gaussian random vectors, and project them using the linear map . Intuitively, we are randomly sampling the range of . And finding an orthonormal basis for these vectors gives us our desired . This scheme is formally described in Algorithm 2.
Algorithm 2: Randomized range finder
Let be a sampling parameter indicating the number of Gaussian random vectors to draw for .
- Draw an Gaussian random matrix
- Generate an matrix
- Generate an orthonormal matrix , e.g. using QR factorization .
Note that Algorithm 2 takes as input a sampling parameter where ideally. Then is the oversampling parameter. In their Section 4.2, Halko et al claim:
For Gaussian test matrices, it is adequate to choose the oversampling parameter to be a small constant, such as or . There is rarely any advantage to select .
Justification for this claim can be found in Section 10.2 of their paper. For completeness, I provide one theoretical result in Section 2.3. But the main result is that with just a few more samples than true rank of , we can get an approximation with an error that is close to the theoretical minimum.
A useful modification to Algorithm 2 is the ability to automatically select based on the acceptable error or tolerance . The main idea is that the orthonormal basis can be constructed incrementally, and we can stop when the error is acceptable. Let denote an iteration of the matrix with columns. Then the empty basis matrix is . Algorithm 3 incrementally generates .
Algorithm 3: Iterative construction of
- Draw an Gaussian random vector, , and set .
- Construct
- Set
- Form
This procedure is reminiscent of the Gram–Schmidt process (Björck, 1994). If we integrate this iterative procedure into Algorithm 2, we get Halko et al’s adaptive randomized range finder in their Section 4.4.
2.3. Performance Analysis
Halko et al present a number of theoretical results for their algorithms, but one illustrative result is their Theorem 1.1. As a preliminary, note Equation per (Mirsky, 1960), which claims that the theoretical minimum of any low-rank matrix approximation of is equal to the th singular value:
Given this, consider their Theorem 1.1:
Theorem 1.1
Suppose that is a real matrix. Select a target rank and an oversampling parameter , where . Execute the proto-algorithm with a standard Gaussian test matrix to obtain an matrix with orthonormal columns. Then
where denotes the expectation with respect to the random test matrix and is the th singular value of .
For a proof, see Halko et al’s proof of Theorem 10.6, which generalizes Theorem 1.1 above.
What this theorem states is that their randomized range finder produces a with an error that is within a small polynomial factor of the theoretical minimum (Equation ). In other words, if , , and are all fixed parameters of , what matters is its singular spectrum.
It makes intuitive sense that the quality of any randomized approximation of depends on the structure of . If is full-rank or if its singular spectrum decays slowly, there is only so well that a randomized low-rank technique can do.
2.6. Subspace iteration
As discussed in Section 2.4, when the singular spectrum of decays slowly, randomized SVD can have high reconstruction error. In this scenario, Halko et al propose taking a couple power iterations (their Algorithm 4.4). The main idea is that power iterations do not modify the singular vectors, but they do reduce the relative weight of small singular values. This forces the spectrum of our approximate range, , to decay more rapidly.
Formally, if the singular values of are , the singular values of are . This is easy to show. Let . Then
In other words, the spectrum decays exponentially with the number of power iterations. Since the SVD of is and since the SVD is unique (Trefethen & Bau III, 1997), the singular vectors are the same.
2.5. Special matrices
In their Sections 5.1-5.4, Halko et al discuss randomized matrix factorizations when is a special matrix. As a taste for this section, I present the scenario in which is Hermitian, i.e. when . In this case, is symmetric and the columns of are a basis for both the column and row spaces. Formally, this means:
When Equation holds, then we have
The first inequality is just the triangle inequality. In the second-to-last line, note that the left term is less than by Equation . The second term is also less than because while
which relies on the symmetry of . Intuitively, given a Hermitian matrix and a range approximation , our error bound is twice the non-Hermitian case because of symmetry, i.e. any element-wise errors are doubled.
Halko et al also analyze the case in which is positive semidefinite and use Nyström’s method (Drineas & Mahoney, 2005) to efficiently improve standard factorizations, but this discussion is omitted for space.
3. Reproducing numerical results
A major contribution of Halko et al is to demonstrate that their algorithms are not just theoretically elegant but also work in practice. In their Section 7, they present a number of numerical experiments.
A goal of this post was to implement randomized SVD and then demonstrate the correctness of the implementation. The code was written for conceptual clarity and correctness rather than performance. While code written in C, C++, or even FORTRAN (as in Halko et al) might be faster, it is worth observing that my Python code is still performant because the key computational costs, computing the SVD and the matrix-vector product , are both done by numpy which has C bindings.
The full code for my implementation of randomized SVD as well as reproducing my results can be found on GitHub.
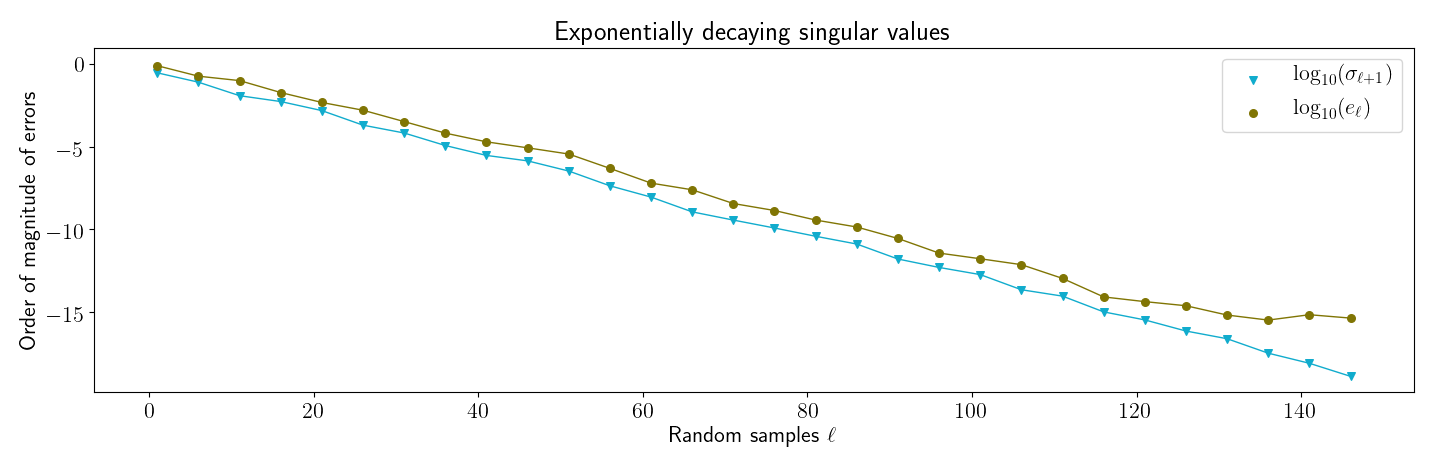
3.1 Decaying singular values
My first reproduction of Halko et al’s numerical results was to reproduce a figure similar to their Figure . The idea behind this figure is to show that when the singular spectrum of a matrix decays, the actual error of randomized SVD on is close to the theoretical minimum.
First, I generated a matrix with exponentially decaying singular values. This was done by reversing SVD after creating a with decreasing values along its diagonal. Then I ran my implementation of randomized SVD over a range of sampling parameter values . For each , I computed two values:
- : This is the minimum approximation error (Equation ).
- : The actual error, computed with
np.linalg.norm.
I then generated Figure , which closely matches the main result in Halko et al’s Figure . First, note that randomized SVD’s actual error, , is close to the theoretical minimum, . Furthermore, as expected, the actual error is always slightly higher than the best we could do.
3.2 Subspace iterations
My second reproduction of Halko et al’s experiments was to verify that subspace iterations work as predicted. First, I verified my understanding by generating Figure , which plots the singular values for the matrix for varying integers . Clearly, for larger , the singular spectrum decays more rapidly.
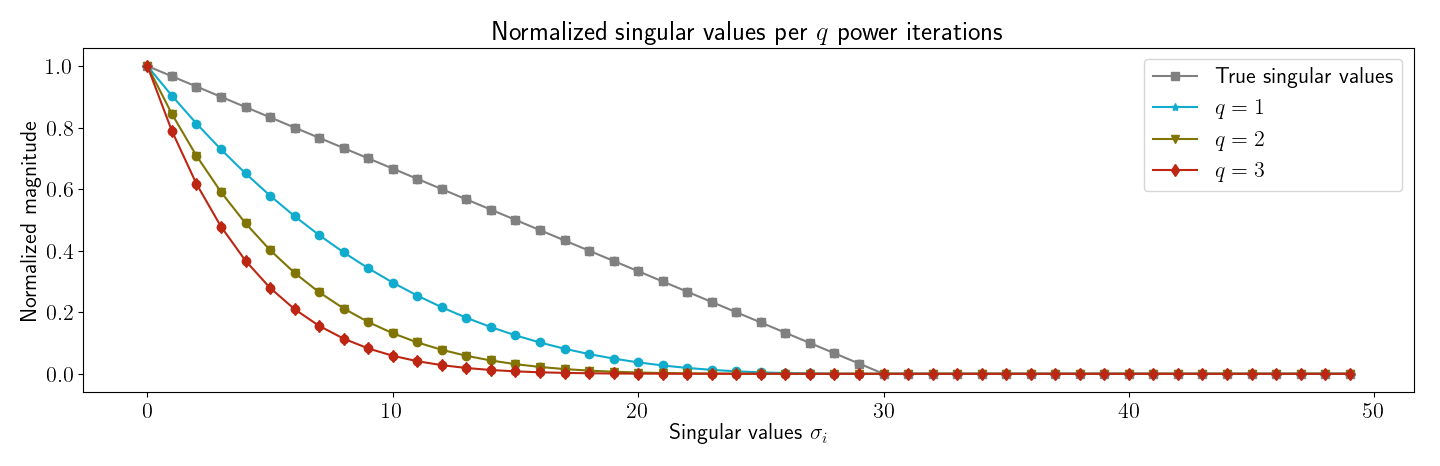
Next, I produced Figure , which is similar to their Figure . This simple numerical experiment demonstrates that even when has slowly decaying singular values—in this case, the singular values decay linearly—subspace iteration can be used to improve the randomized low-rank approximation.
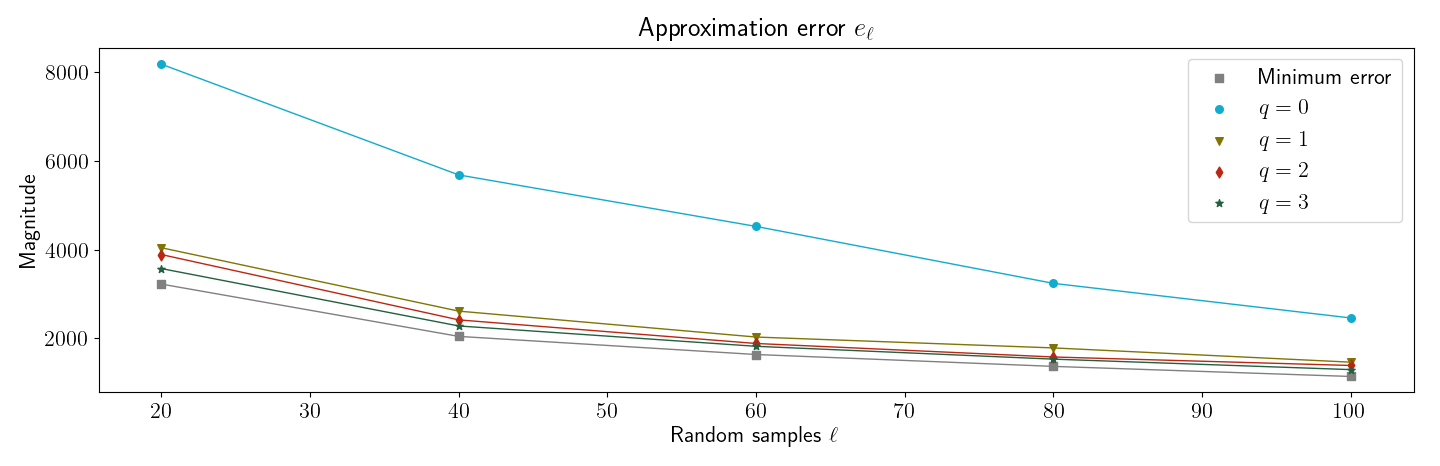
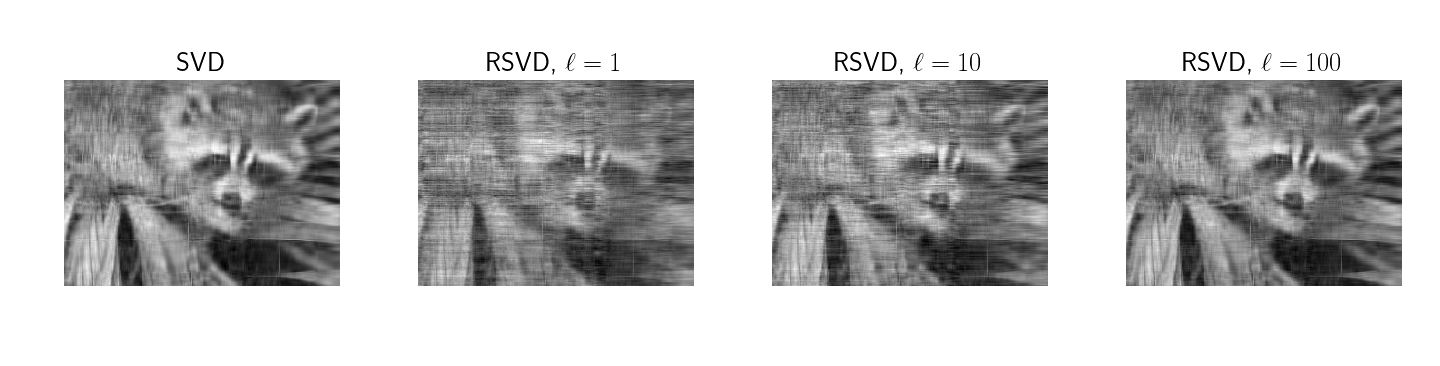
3.3 Oversampling and accuracy
Finally, a common example of the utility of SVD is image reconstruction with the top singular values for some number . For example, in their Section 7.3, Halko et al discuss measuring the reconstruction error on ``Eigenfaces’’ (Phillips et al., 1998) (Phillips et al., 2000). To qualitatively evaluate the correctness of my implementation as well as the impact of the sampling parameter , I generated Figure . This demonstrates that with more Gaussian random samples , the reconstruction approaches the true low-rank factorization.
Conclusion
RandNLA is an exciting area of research that focuses on randomized techniques for numerical linear algebra. Halko, Martinsson, and Tropp’s 2011 paper introduced a two-stage modular framework for computing randomized low-rank matrix factorizations. The work addressed issues such as slowly decaying singular spectrums and special matrices, offered tight bounds on the performance of their algorithms, and provided numerical results demonstrating that these methods work in practice. This post, in addition to providing an overview of the paper, has demonstrated that Halko et al’s work is reproducible and that their theoretical guarantees closely match results from straightforward implementations.
Acknowledgements
Most of the work that went into this post was the result of a class project for ELE 538B at Princeton. I want to thank Yuxin Chen for helpful feedback.
- Drineas, P., Kannan, R., & Mahoney, M. W. (2006). Fast Monte Carlo algorithms for matrices II: Computing a low-rank approximation to a matrix. SIAM Journal on Computing, 36(1), 158–183.
- Drineas, P., & Mahoney, M. W. (2016). RandNLA: randomized numerical linear algebra. Communications of the ACM, 59(6), 80–90.
- Mahoney, M. W. (2016). Lecture notes on randomized linear algebra. ArXiv Preprint ArXiv:1608.04481.
- Halko, N., Martinsson, P.-G., & Tropp, J. A. (2011). Finding structure with randomness: Probabilistic algorithms for constructing approximate matrix decompositions. SIAM Review, 53(2), 217–288.
- Johnson, W. B., & Lindenstrauss, J. (1984). Extensions of Lipschitz mappings into a Hilbert space. Contemporary Mathematics, 26(189-206), 1.
- Björck, Å. (1994). Numerics of gram-schmidt orthogonalization. Linear Algebra and Its Applications, 197, 297–316.
- Mirsky, L. (1960). Symmetric gauge functions and unitarily invariant norms. The Quarterly Journal of Mathematics, 11(1), 50–59.
- Trefethen, L. N., & Bau III, D. (1997). Numerical linear algebra (Vol. 50). Siam.
- Drineas, P., & Mahoney, M. W. (2005). On the Nyström method for approximating a Gram matrix for improved kernel-based learning. Journal of Machine Learning Research, 6(Dec), 2153–2175.
- Phillips, P. J., Wechsler, H., Huang, J., & Rauss, P. J. (1998). The FERET database and evaluation procedure for face-recognition algorithms. Image and Vision Computing, 16(5), 295–306.
- Phillips, P. J., Moon, H., Rizvi, S. A., & Rauss, P. J. (2000). The FERET evaluation methodology for face-recognition algorithms. IEEE Transactions on Pattern Analysis and Machine Intelligence, 22(10), 1090–1104.