I derive some basic properties of the lognormal distribution.
Published
17 December 2023
Let X be a normal random variable with mean μ and variance σ2:
X∼N(μ,σ2).(1)
Now define Y as
Y=exp(X).(2)
We say that Y is lognormally distributed with parameters μ and σ
or
Y∼lognormal(μ,σ).(3)
Alternatively, we could say that logY is normally distributed,
logY∼N(μ,σ2).(4)
Let’s work through some basic properties of Y.
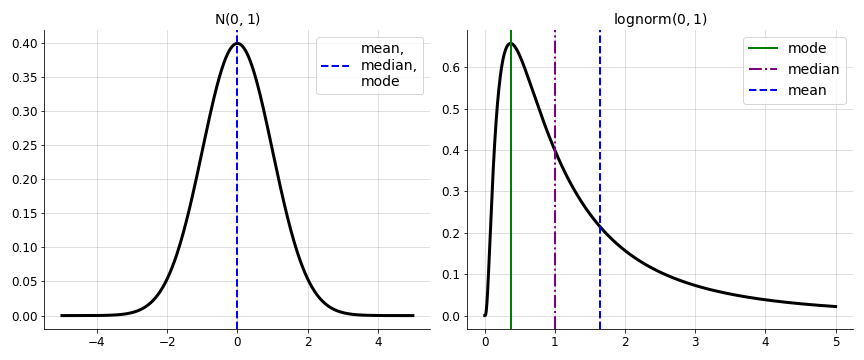
Non-negativity. Perhaps the first thing to observe is that Y is a non-negative random
variable (Figure 1). This is because ex is positive for any value of x. Thus, the lognormal distribution often arises in cases
where non-negativity is an important property of the data being modeled.
Figure 1. Normal (left) and lognormal
(right) distributions, both with parameters μ=0 and σ=1. The
normal distribution's measures of central tendency (mean, median, mode) are
all equal, while the lognormal distribution's measures are different due to
the lognormal distribution's skew.
Moments. The second thing to observe is that the parameters μ and σ2 are
the mean and variance of X, but they are not the mean and variance of
Y. The mean of Y is
E[Y]=E[exp(X)]=exp{μ+21σ2}.(5)
This is just a special case of the k-th moment of the lognormal
distribution. In general, the k-th moment is
Measures of central tendency. Using the CDF in Equation 8, we can compute
the median m of Y, which is
m:=exp(μ).(11)
See A4 for details. And using the PDF in Equation 8, we can compute the
mode d, which is
d:=exp(μ−σ2).(12)
See A5 for details. Given Equations 5, 11, and 12, we can
order these measures of central tendency as
exp(μ−σ2)≤exp(μ)≤exp(μ+21σ2).(13)
This tells us that a lognormal distribution’s measures are ordered
left-to-right as mode, median, and then mean (Figure 1, right).
Parameterizations. Not only is μ not the mean of Y, it is not even a
clean measure of central tendency. This is because μ is shifting logy
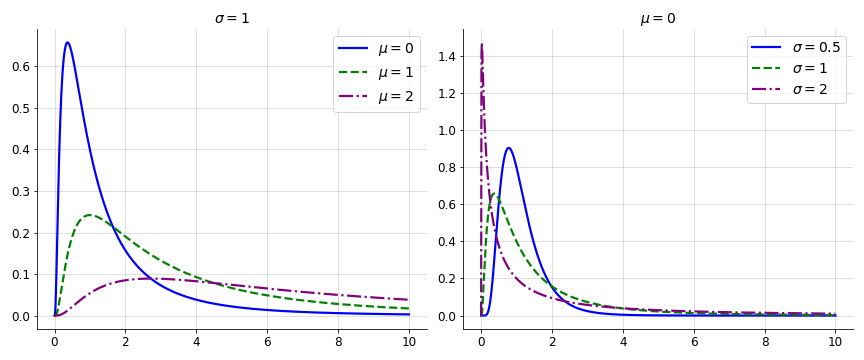
rather than y. So the dispersion of Y increases as either μ or σ increases (Equation 7 and Figure 2).
Figure 2. Several lognormal distributions
with (left) the parameter σ fixed and (right) the
parameter μ fixed. We can see that both the central tendency and dispersion
of Y depend on μ and σ.
Given the fact that μ and σ are not actually
the mean and standard deviations of Y, we can consider alternative, more
natural parameterizations. One choice is to consider the exponent of each
parameter, so
μ∗=eμ,σ∗=eσ.(14)
We have already seen that μ∗ is the median of Y, while σ∗
captures the dispersion of Y, although it is not the variance of Y.
As a final note, some statistical libraries use different parameterizations. In
my mind, it is easiest to think of the “canonical” parameterization as the one
used in this post and to then convert to alternative forms as needed. For an example, see A6 for details on SciPy’s parameterization of the lognormal distribution.
Appendix
A1. Moments
We want to find the k-th moment of Y=eX when X∼N(μ,σ2). This means we want to simplify
Then all we need to do is simplify the expression in brackets to be again
quadratic in x. We can then pull out any terms that do not depend on x, and
see that the integral must be unity because probabilities are normalized. So
let’s write the bracketed term as
But for X, the median is μ, and therefore we have μ=logm, which
implies that m=expμ, as desired.
A5. Mode
To compute the mode d of a distribution, we want to compute
d:=y⋆=argymaxfY(y).(A5.1)
To compute this, we take the derivative of the PDF, set it equal to zero, and
solve for y. In addition, we should confirm that m is the local maximum
using a second derivative test.
We should confirm this is a maximum with a second derivative test. However, I
don’t want to take the derivative of Equation A5.2. See the Book of Statistical Proofs for
a complete proof.
A6. SciPy
SciPy
uses a parameter s for σ and a parameter scale for expμ. This is a
SciPy convention in which multiple distributions use the same parameter
names (loc, shape, scale, …). Since μ is not strictly a location
parameter—it also affects the dispersion—we can only specify μ a la
Equation 3 using the median expμ. I am not sure why the argument for
σ is named s rather than shape.