Linear Independence, Basis, and the Gram–Schmidt algorithm
I formalize and visualize several important concepts in linear algebra: linear independence and dependence, orthogonality and orthonormality, and basis. Finally, I discuss the Gram–Schmidt algorithm, an algorithm for converting a basis into an orthonormal basis.
Definitions
A collection of one or more -vectors is called linearly dependent if
for some scalars which are not all zero and where is a -vector of zeros. The definition of linear independence is just the opposite notion. A collection of -vectors are linearly independent if the only way to make them equal to the zero-vector is if all the coefficients are zero:
For example, here are two pairs of -vectors that are linearly independent (left) and linearly dependent (right):
The vectors and are dependent since .
Why do we use the word “dependence” to describe Equation ? Since for at least one vector for a linearly dependent set, we can rewrite Equation as
In other words, any vector for which can be written as a linear combination of the other vectors in the collection. This is the mathematical formulation for why we call the vectors “dependent.” It’s because we can express the vectors in terms of each other.
Geometric interpretations
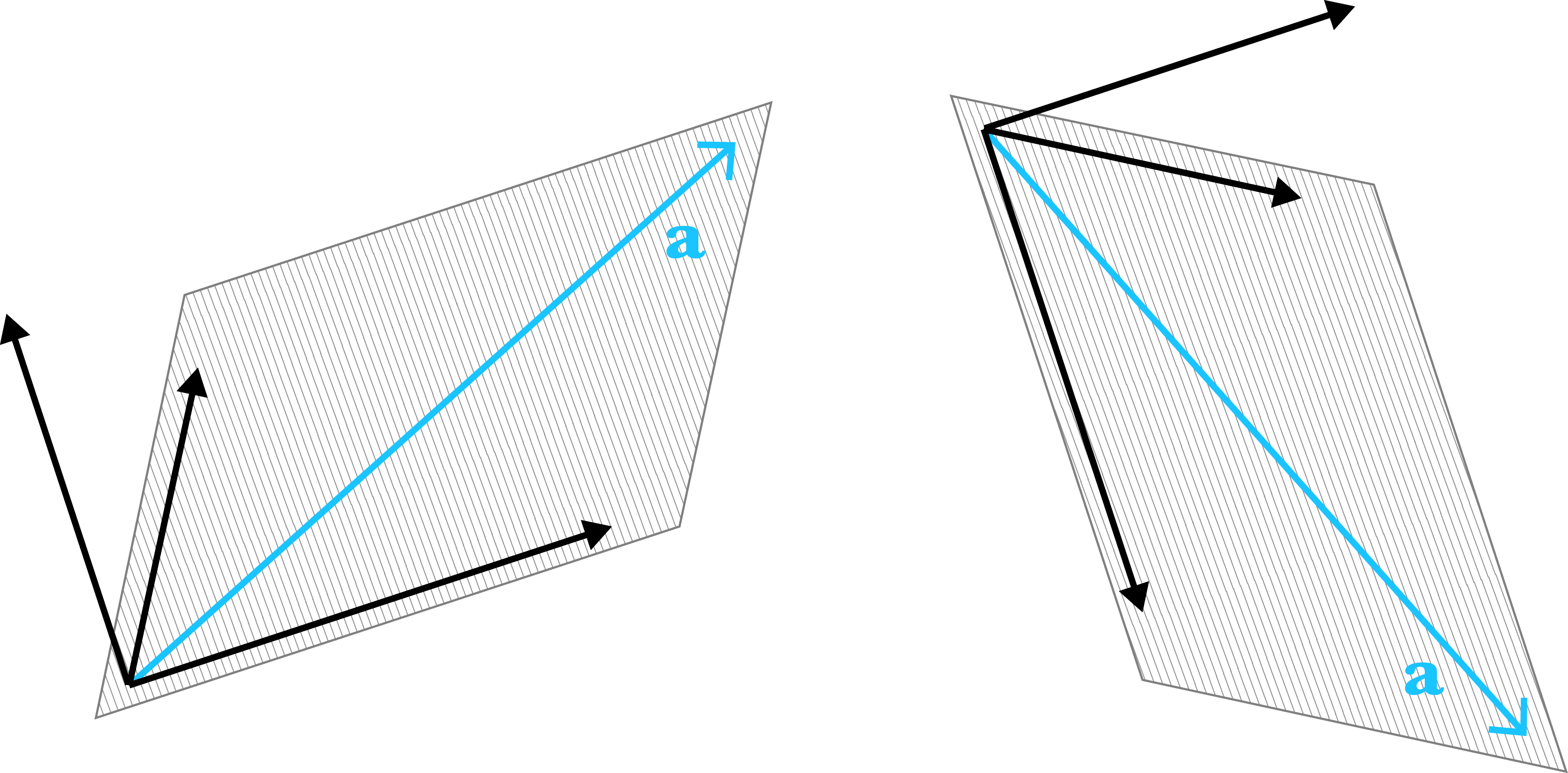
Let’s visualize linear dependence and independence. Recall that vector addition can be visualized by first drawing the vector from the origin and then drawing the vector from the head of . The resulting vector is the vector from the origin to head of (Figure ). Note that we can flip the order, drawing the vector and then and still arrive at the same location.
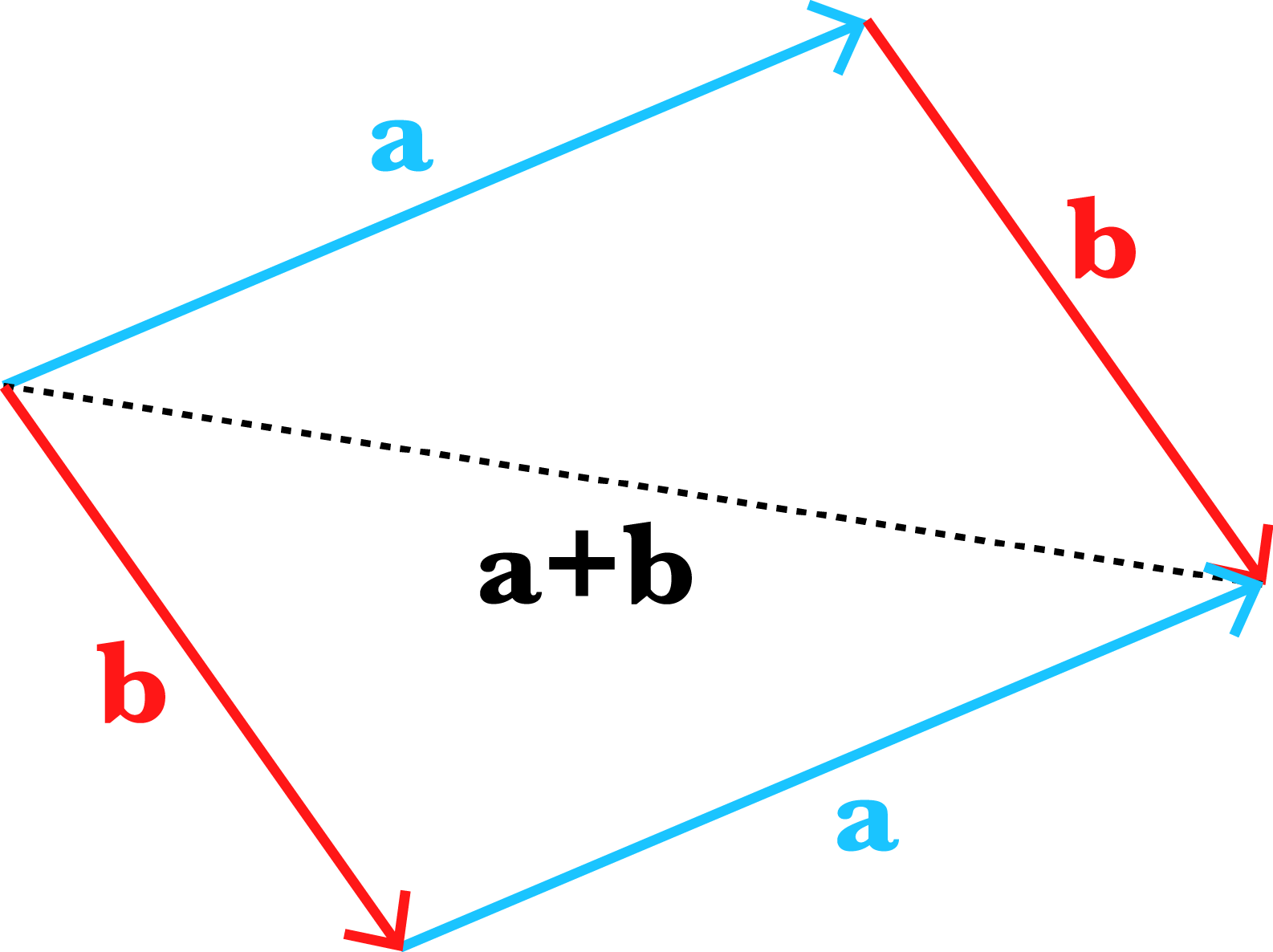
Now what does it mean for two -vectors to be scaled such that they add to ? It means they must lie on the same line (Figure ). Intuitively, if they did not lie on the same line, there would be no way to scale and add the vectors such that the computation ends at the origin .
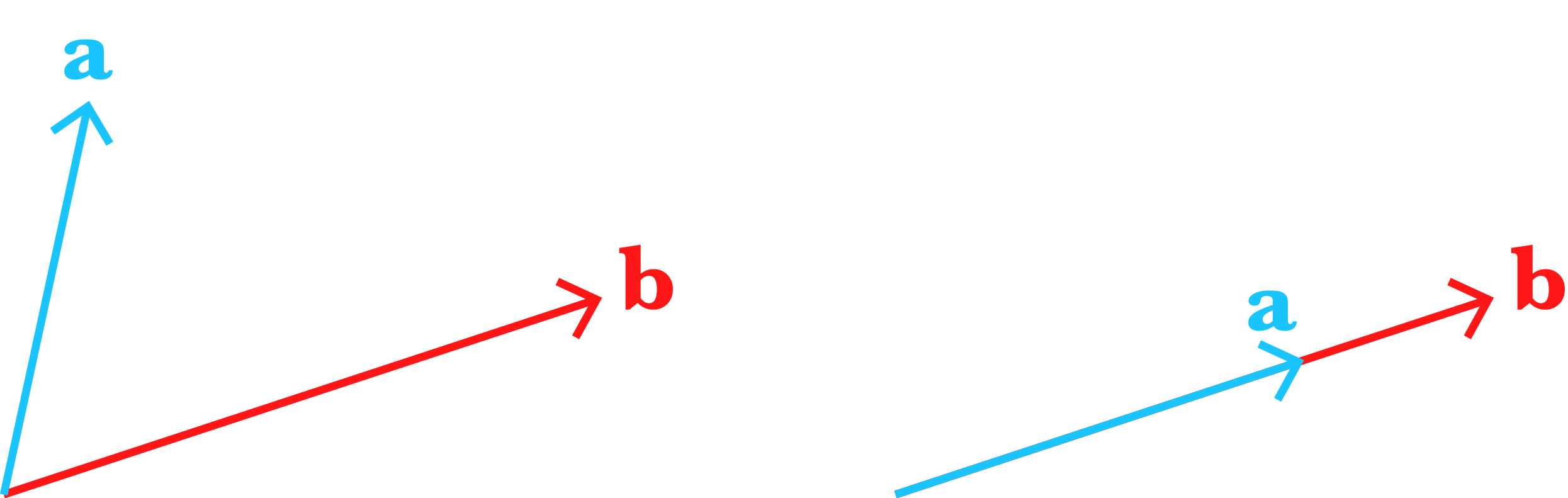
Notice that if two -vectors are linearly dependent, we can increase the vectors’ size or dimension by adding zeros and still have linearly dependent vectors. For example, the linearly dependent vectors and in Equation are linearly dependent in -dimensions provided we just add zeros:
Visually, adding zeros in this way is like embedding -vectors on a -dimensional plane into in a -dimensional space.
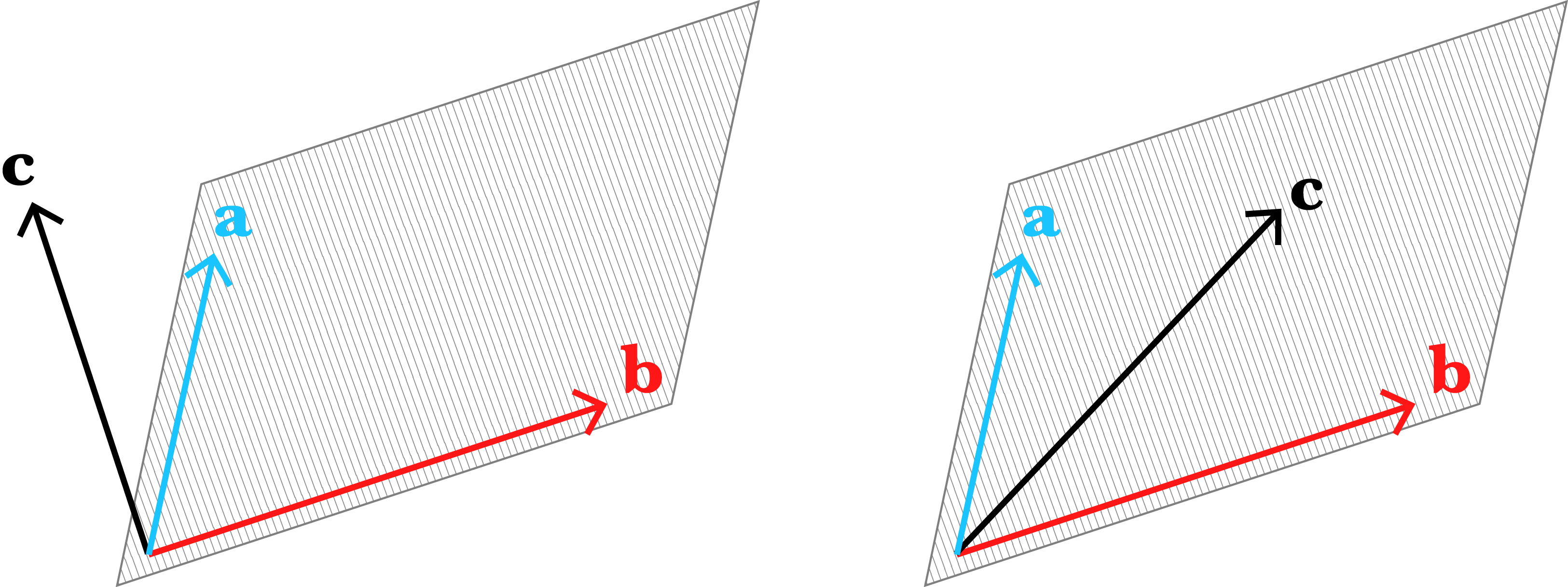
This starts to suggest what linear dependence in -dimensions might look like. Three linearly dependent -vectors must lie on a plane that goes through the origin (Figure ). Again, the visual intuition is that if this were not true, there would be no way to, speaking loosely, get back to the origin using scaled versions of these vectors. Linear independence in three dimensions is precisely the opposite claim, that the -vectors do not all lie on a plane that passes through the origin.
Uniqueness
If a vector is a linear combination of linearly independent vectors ,
then the coefficients are unique. It is easy to prove this. Suppose there are other coefficients such that
Then clearly
Since we assumed that the vectors are linearly independent, then clearly for all .
Dimension and basis
Linear–dimension inequality
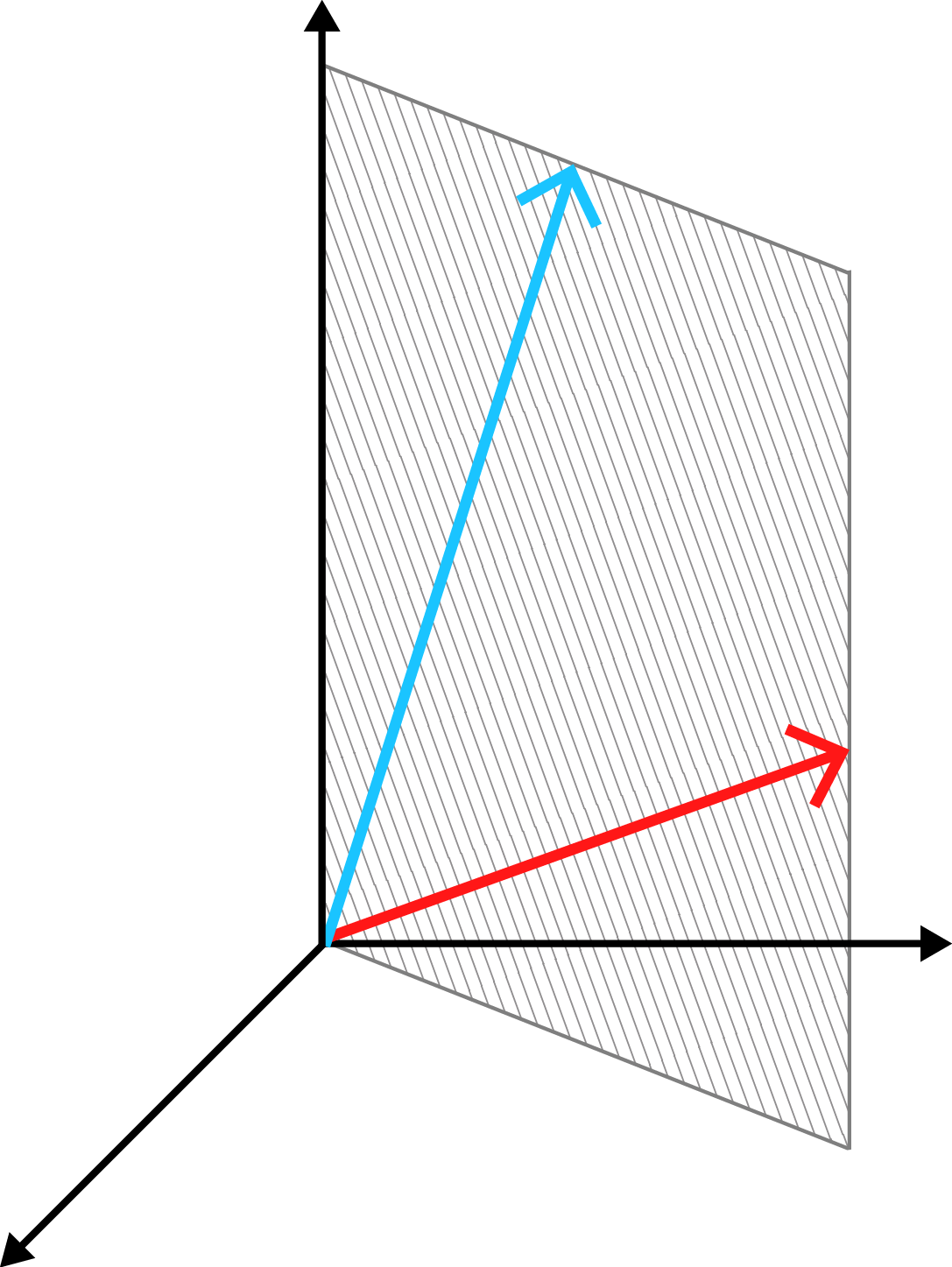
Notice that if we have two -vectors, they could lie on a plane that passes through the origin and still be linearly independent (Figure ).
For example, we can increase the dimension of vectors and in Equation by adding zeros, and the two resultant vectors would still be linearly independent:
Furthermore, we could even add another vector to this collection such that the new collection is linearly independent, e.g.:
However, we cannot add a new vector to the collection in Equation and still have a linearly independent set. In general, we cannot have an -sized collection of linearly independent -vectors if . However, I think it is an intuitive result. Imagine we had two linearly independent -vectors, such as in Figure . Can you add another vector to the set such that it’s still impossible to scale and add the vectors to return to the origin?
This idea is called the independence–dimension inequality. Formally, if -vectors are linearly independent, then . See (Boyd & Vandenberghe, 2018) for a proof. Therefore, a collection of linearly independent -vectors cannot have more than elements. This immediately implies that any collection of or more -vectors is linearly dependent.
Basis
A basis is a collection of linearly independent -vectors. Any -vector can be written as a linear combination of the vectors in a basis of -vectors:
The scalars are called the coordinates of the basis. As this definition suggests, you are already familiar with this concept. When we use Cartesian coordinates to specify the location of an object on the -plane, those coordinates implicitly rely on the basis vectors and :
Let’s prove that any -vector can be represented as a linear combination of a basis of -vectors. Since a basis is linearly independent, we know that if and only if
Now consider this basis plus an additional vector . By the independence–dimension inequality, we know this new collection is linearly dependent. Therefore, it can be written as
where are not all zero. Then clearly , otherwise we have a contradiction in our assumption that . And if , we can write the vector as a linear combination of the basis vectors:
Furthermore, we proved that if is a linear combination of independent vectors, then its coefficients are unique. Combining these two results, we can say: any -vector can be uniquely represented as a linear combination of basis vectors .
Change of basis
Notice that we can describe the same vector using different bases. I won’t go into this concept in detail, but I think it is quite easy to visualization (Figure ). A change of basis is an operation that re-expresses all vectors using a new basis or coordinate system. We’ll see in a bit how the Gram–Schmidt algorithm takes any basis and performs a change-of-basis to an orthonormal basis (discussed next).
Orthogonal and orthonormal vectors
Orthogonality and orthonormality
Two vectors and are orthogonal if their dot product is zero, i.e.
A collection of vectors is orthogonal if Equation holds for any pair of vectors in the collection. A collection is orthonormal if the collection is both orthogonal and if
That is, if every vector has unit length. We can express these two conditions as a single condition:
Orthonormal basis
We can easily prove that orthonormal -vectors are linearly independent. Suppose for some coefficients
We can take the dot product of both sides of this equation with any in the collection to get
The last step holds because of the conditions in Equation . Thus, we have shown that for any in the collection, its associated coordinate is zero, i.e. orthonormal vectors are linearly independent. Notice that this immediately implies that any -sized collection of orthonormal -vectors is a basis.
Furthermore, notice that if is a linear combination of orthonormal vectors, we can use the logic in Equation to find the coefficients:
The dot product of each vector in the orthonormal basis with equals the associated coefficient.
The standard basis or standard unit vectors are basis of vectors whose coordinates are one-hot vectors, i.e. all zero except for one . For example, the standard basis for is
Gram–Schmidt algorithm
Imagine we had a collection of -vectors that formed a basis but that were not necessarily orthonormal. Since orthonormal bases are both convention and easier to work with, a common operation in numerical linear algebra is to convert bases to orthonormal bases. The Gram–Schmidt algorithm is a process for doing that.
Vector projection
Before discussing the Gram–Schmidt algorithm, recall the definition of a vector projection. The vector projection of a vector onto a vector , often denoted , is
where is a unit vector in the direction of . This definition falls out of a little trigonometry and the definition of the dot product. We know from basic trigonometry that the projection of onto is , where is the angle between and (Figure ).
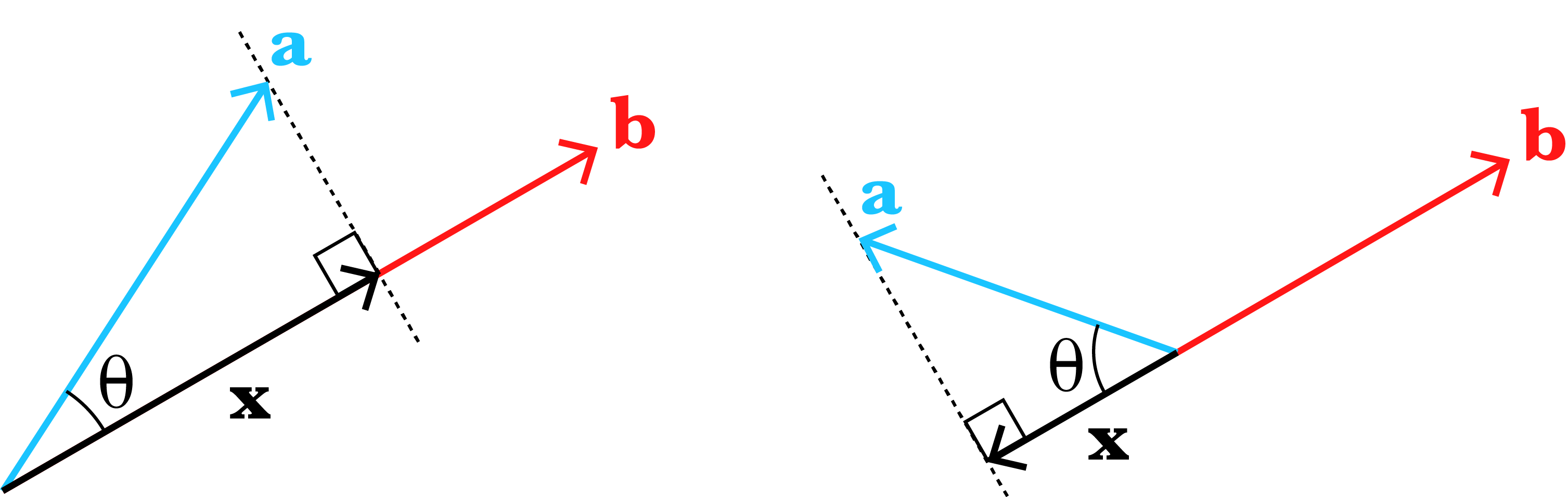
However, if we don’t know , we can simply rewrite using the definition of the dot product,
This scalar value is the length of the vector in Figure , but we must multiply it by a vector that has unit length and points in the direction of , hence in Equation .
Algorithm
The Gram–Schmidt algorithm is fairly straightforward. It processes the vectors one at a time while maintaining an invariant: all the previously processed vectors are an orthonormal set. For each vector , it first finds a new vector that is orthogonal to the previously processed vectors. It then normalizes that to a vector we will call . There are plenty of proofs of the correctness of Gram–Schmidt, e.g. (Boyd & Vandenberghe, 2018). In this post, I will just focus on the intuition. I think it’s fairly straightforward to see that Gram–Schmidt should be correct.
Consider the first step of the algorithm. The algorithm processes the vector . Since no other vectors have been processed, does not need to be changed to be orthogonal to the empty set. The algorithm simply normalizes , i.e. (Figure and ).
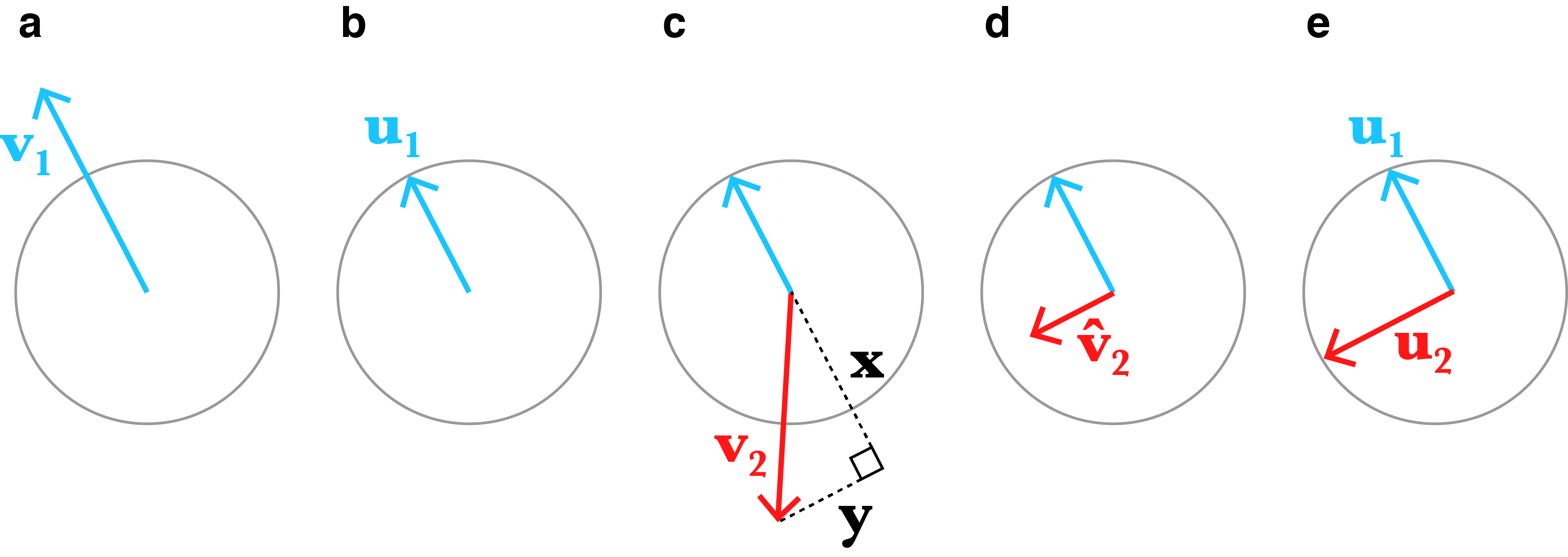
Next, consider the vector , which is not necessarily orthogonal to (Figure ). This vector can expressed as the sum of two vectors and , where is the projection of onto and where , i.e. it is orthogonal to the vector projection. Therefore, we can find a new vector that is orthogonal to (Figure ) as
Finally, we simply normalize to get (Figure ). Gram–Schmidt then proceeds by finding a third vector, , that is orthogonal to the vectors and following the same logic, and so on. In general, the equation for is
This is the basic idea of Gram–Schmidt. Besides proving it is correct, there are some other details such as how to handle cases in which the algorithm discovers that is not a basis. However, I don’t think these add much to the intuition desired here.
- Boyd, S., & Vandenberghe, L. (2018). Introduction to applied linear algebra: vectors, matrices, and least squares. Cambridge university press.