Why Shouldn't I Invert That Matrix?
A standard claim in textbooks and courses in numerical linear algebra is that one should not invert a matrix to solve for in . I explore why this is typically true.
In a recent research meeting, I was told, “Never invert a matrix.” The person went on to explain that while we always use to denote a matrix inversion in an equation, in practice, we don’t actually invert the matrix. Instead, we solve a system of linear equations. Let me first clarify this claim. Consider solving for in
where is an matrix and and are -vectors. One way to solve this equation is a matrix inversion ,
However, we could avoid computing entirely by solving the system of linear equations directly.
So why and when is one approach better than the other? John Cook has a blog post on this topic, and while it is widely referenced, it is spare in details. For example, Cook claims that “Solving the system is more numerically accurate than the performing the matrix multiplication” but provides no explanation or evidence.
The goal of this post is to expand on the why computing Eq. explicitly is often undesirable. As always, the answer lies in the details.
LU decomposition
Before comparing matrix inversion to linear system solving, we need to talk about a powerful operation that is used in both calculations: the lower–upper decomposition. Feel free to skip this section if you are familiar with this material.
The LU decomposition uses Gaussian elimination to transform a full linear system into an upper-triangular system by applying linear transformations from the left. It is similar to the QR decomposition without the constraint that the left matrix is orthogonal. Both decompositions can be used for solving linear systems and inverting matrices, but I’ll focus on the LU decomposition because, at least as I understand it, it is typically preferred in practice.
The basic idea is to transform into an upper-triangular matrix by repeatedly introducing zeros below the diagonal: first add zeros to the first column, then the second, and so on:
On the -th transformation, the algorithm introduces zeros below the diagonal by subtracting multiples of the -th row from the rows beneath it ().
Let’s look at an example that borrows heavily from (Trefethen & Bau III, 1997). Consider the matrix
First, we want to introduce zeros below the top-left . Trefethen and Bau picked the numbers in judiciously for convenient elimination. Namely, and . We can represent this elimination as a lower triangular matrix as:
Now we just need to eliminate in , which we can do through another linear map:
What this example highlights is that we can maintain the previously computed zeros by only operating on rows below the th row.
At this point, you may note that we have computed
Therefore, the desired lower triangular matrix requires inverses!
As it turns out, the general formula for is such that computing the inverse is trivial: we just negate the values below the diagonal. Please see chapter of (Trefethen & Bau III, 1997) for details.
How many floating-point operations (flops) are required to compute an LU decomposition? You can find more detailed proofs elsewhere, but here’s the simple geometric intuition provided by Trefethen and Bau. For the -th row in , we have to operate over columns. So for each of the iterations of the algorithm, we have complexity that is . We can visualize this as a pyramid of computation (Figure ).
Each unit of volume of this pyramid requires two flops (not discussed here), and the area of the pyramid in the limit of is . So the work required for LU decomposition is
Solving a linear system
Now let’s talk about using the LU decomposition to solve a linear system. Let the notation denote the vector that solves . How do we compute without using a matrix inverse? A standard method is to use the LU decomposition of and then solve two easy systems of equations:
Why is it easy to solve for and w.r.t. and respectively? Because these are lower- and upper-triangular matrices respectively. For example, consider solving for above:
For each value , we have
Solving for in this way is called forward substitution because we compute and then forward substitute the value into the next row and so on. We can then run backward substitution on an upper-triangular matrix—so starting at the bottom row and moving up—to solve for .
What’s the cost of this computation? Forward substitution requires multiplications and subtractions at each step or
The cost of backward substitution is slightly larger because the diagonal elements are not one. Therefore, there are additional divisions or flops. Therefore the total complexity of solving a linear system of equations using the LU decomposition is
Inverting a matrix
Now let’s consider inverting a matrix. Now that we understand the LU decomposition, matrix inversion is easy. We want to compute in
Once we have the LU decomposition, we can simply solve for each column of :
The simplest algorithm would be to perform this operation times. Since the LU decomposition requires flops and solving for each requires flops, we see that that matrix inversion requires
That said, matrix inversion is a complicated topic, and there are faster algorithms. But the basic idea is that the inversion itself is not faster than the LU decomposition, which effectively solves for .
Finally, solving for is not the same thing as computing . To compute , we have to perform a matrix multiplication, , which is
As we can see inverting a matrix to solve is roughly three times as expensive as directly solving for . This alone is justification for the claim that, unless you have good reasons, it is better to directly solve for .
Numerical errors and conditioning
As we’ll see, solving a linear system using a matrix inverse can also be less accurate. However, before discussing this, let’s review several concepts related to numerical methods. Consider the function
and imagine we can only approximate its output, denoted . The forward error is the error between the true and approximated outputs, . The backward error measures the sensitivity to the problem. We want the smallest such that
This quantifies: for what input data have we actually solved the problem? If is very large, then our approximation isn’t even based on a value close to the true input . So is called the backward error.
For example, imagine we approximate with . The forward error is the absolute difference between and . Since , the backward error is the absolute difference between and .
Finally, we say that the problem is well-conditioned if a small change in leads to a small change and ill-conditioned otherwise. This is often quantified with a condition number. In numerical linear algebra, the condition number of a matrix, denoted by , is
If is the matrix -norm, then Eq. is just the ratio of largest to smallest singular values,
See this StackExchange answer for a proof. In other words, an ill-conditioned matrix is one with a large spread in its singular values. Intuitively, this is not surprising, since matrices with sharp decays in their singular values are associated with many other instabilities, such as in control systems.
Accuracy
Let’s return to the main thread. A second problem with matrix inversion is that it can be less accurate. Let denote the vector solved for directly by the LU decomposition, and let denote the vector solved by , where is computed using the LU decomposition as discussed above. Now imagine that we computed the matrix inverse exactly, meaning we have no rounding errors in the computation . Then the best residual bound on the backward error, taken from section of (Higham, 2002), is:
where is a small constant factor accounting for things like machine precision. For , this bound is
If we assume the LU decomposition of is relatively good—something Higham says is “usually true”—then the terms in purple in Eq. and are roughly equal, and the terms that dominate the bound for each method are and . Thus, the matrix inversion approach can have signficantly worse backward error than directly solving for if the matrix is ill-conditioned.
That said, the forward error between matrix inversion and direct solving can be much closer than expected for well-conditioned problems, a point argued by (Druinsky & Toledo, 2012). Thus, in practice, if you care only about the forward error, the folk wisdom that you should never invert a matrix may stress the point too much. I don’t discuss the bounds on forward errors here, but see this StackExchange post for details.
As I see it, the upshot is still the same: solving a system of linear equations by performing a matrix inversion is typically less accurate than solving the system directly.
Numerical experiments
I ran a couple simple numerical experiments to verify the results discussed above.
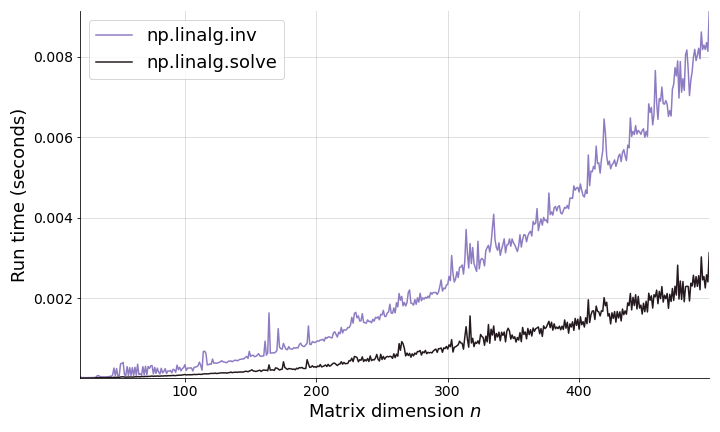
First, let’s explore whether in practice, solving for directly is faster than using a matrix inversion. For increasing , I ran the following experiment: generate a matrix and vector . Then solve for using np.linalg.solve(A, b) and np.linalg.inv(A) @ b. I ran each experiment times and recorded the mean run time (Figure ). As expected, solving for directly is faster. While the absolute difference in seconds is trivial here, it is easy to imagine this mattering more in large-scale data processing tasks.
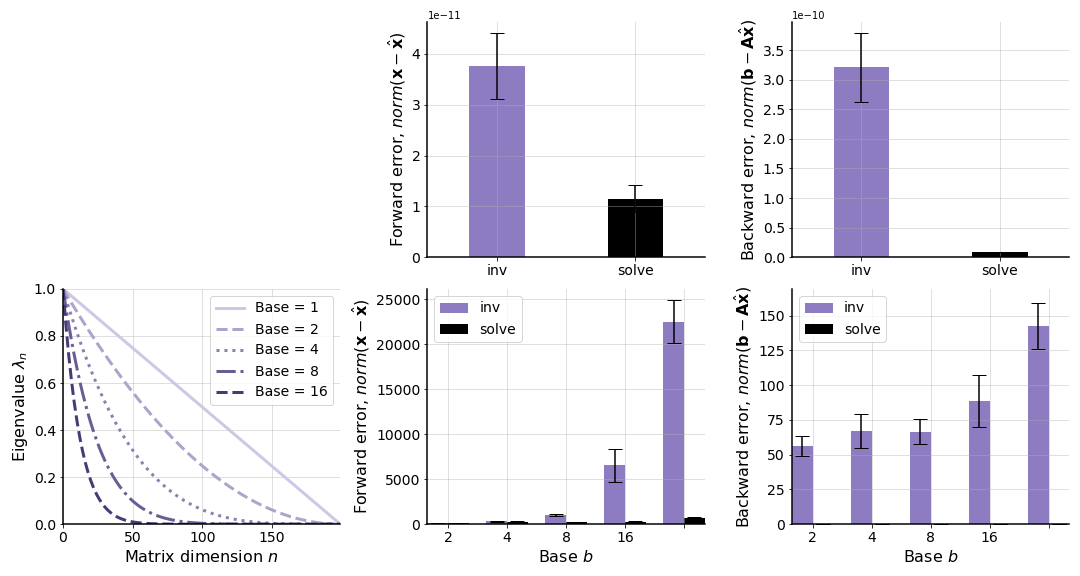
Next, let’s explore the forward and backward error for well- and ill-conditioned problems. I generated two matrices and in the following way:
x = np.random.normal(n)
# Well-conditioned A and resulting b.
Aw = np.random.normal(size=(n, n))
bw = Aw @ x
# Ill-conditioned A and resulting b.
lambs = np.power(np.linspace(0, 1, n), b)
inds = np.argsort(lambs)[::-1]
lambs = lambs[inds]
Q = ortho_group.rvs(dim=n)
Ai = Q @ np.diag(lambs) @ Q.T
bi = Ai @ x
In words, the well-conditioned matrix is just a full-rank matrix with each element drawn from . For the ill-conditioned matrix, I generated a matrix with sharply decaying singular values. The decay rate is controlled by an exponent base b. As we can see (Figure ), both the forward and backward errors are relatively small and close to each other when the matrix is well-conditioned. However, when the matrix is ill-conditioned, the forward and backward errors increase, loosely as a function of the decay rate for the singular values.
Summary
When solving for in , it is always faster and often more accurate to directly solve the system of linear equations, rather than inverting and doing a left multiplication with . This is a big topic, and I’m sure I’ve missed many nuances, but I think the main point stands: as a rule, one should be wary of inverting matrices.
- Trefethen, L. N., & Bau III, D. (1997). Numerical linear algebra (Vol. 50). Siam.
- Higham, N. J. (2002). Accuracy and stability of numerical algorithms. SIAM.
- Druinsky, A., & Toledo, S. (2012). How Accurate is inv (A)* b? ArXiv Preprint ArXiv:1201.6035.