Expectation–maximization for hidden Markov models is called the Baum–Welch algorithm, and it relies on the forward–backward algorithm for efficient computation. I review HMMs and then present these algorithms in detail.
Published
28 November 2020
The simplest probabilistic model of sequential data is that the data are i.i.d. We assume the data are Gaussian or binomial or from a nonparametric distribution we cannot write down, but we do not assume that model changes over time. We do not assume we can make any inference about the next observation given the current one. The graphical model for this assumption would be a sequence of unconnected nodes.
Of course, this assumption prevents modeling any sequential structure. For example, in text, certain words are more likely to follow a given word than others, while an i.i.d. assumption would obliterate this structure by assuming each word is independent from the words around it. One simple model, called a first-order Markov model, is that each observation only depends on the previous one. For example, if we assume that each observation is Gaussian and its mean linearly depends on the previous data point, then we are working with an autoregressive model.
First-order models can be extended to M-th order Markov models which assume each observation depends on the previous M observations. However, the number of parameters of this model is exponential in M. For example, imagine we flipped a coin M times, and we need to consider all possible sequence of coin flips. Each time M increases by one, the number of possible sequences doubles. Thus, inference is intractable for even modest values of M.
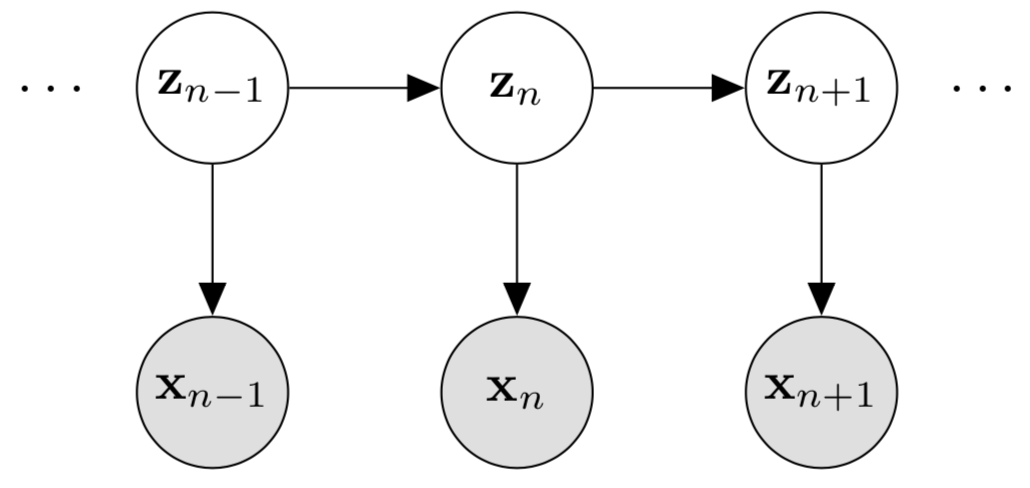
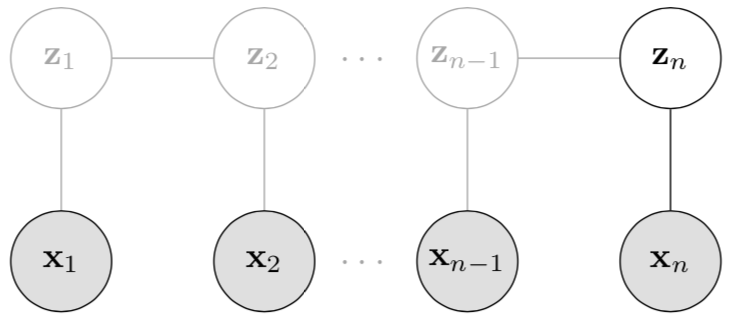
A powerful probabilistic model of sequential data that still limits the number of parameters is the hidden Markov model (HMM). The key idea is that a latent variable or state variable, rather than the data, evolves according to a discrete, first-order Markov process. Each observation is conditionally independent of every other observation given the value of its associated latent variable (Fig. 1).
Figure 1: Graphical model for a hidden Markov model. The hidden state variables z1,…,zN follow a Markov process, while each observation xn is conditionally independent from other data given its associated hidden state variable zn.
However, and this is the clever bit, notice that no observation is d-separated from any other observation. There is always an unblocked path between any two observations because all observations are connected via the latent variables. Thus, our predictive distribution is
p(xn+1∣x1,…,xn),(1)
meaning that xn+1 depends on all previous observations. Thus, by introducing these latent variables, we can tractably compute a flexible predictive distribution.
The goal of this post is to work through HMMs in detail. In particular, I want to focus on the Baum–Welch and forward–backward algorithms. I assume the reader understands Markov chains and expectation–maximization.
Example: Rainier weather data
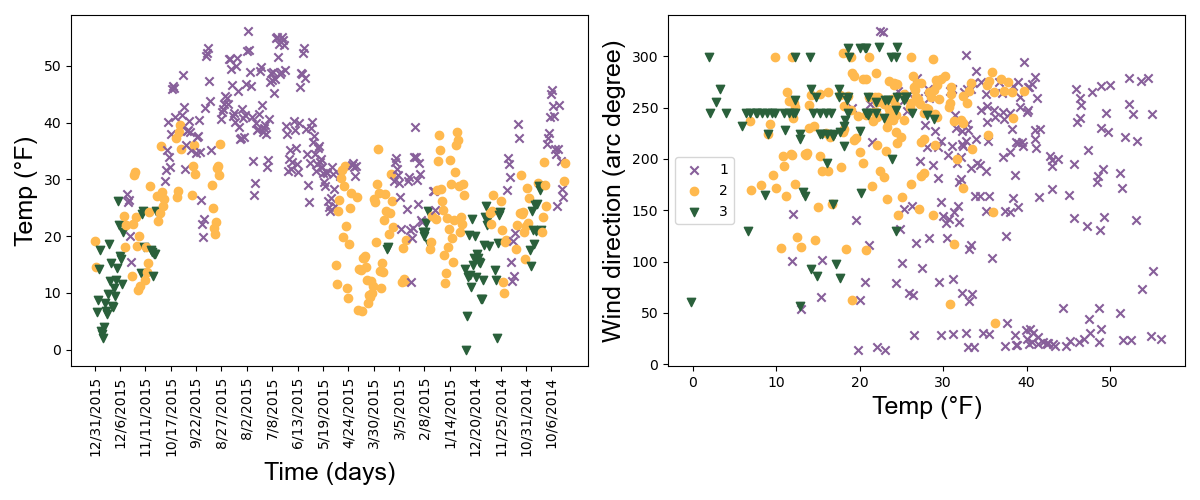
Before diving into the model and inference details, let’s look at an example. I fit a hidden Markov model using the code below on Mount Rainier weather data. The data features are: temperature, relative humidity, daily wind speed, wind direction, and battery voltage. Each feature was collected daily between 3 August 2014 and 31 December 2015. I used three state variables, meaning the HMM will assign each day to one of three latent or hidden states. In Fig. 2, I plotted temperature across time (left panel) and temperature vs. wind direction (right panel). I colored the data points by their hidden states. As we can see, the inferred states are fairly interpretable, roughly capturing warm, cool, and cold days. Interestingly, it looks like the coldest days on Rainier have wind coming from the south.
Figure 2: Mount Rainier weather data between 3 August 2014 and 31 December 2015 with days. In both plots, days (data points) are labeled by a three-state hidden Markov model. (Left) Temperature across time. (Right) Temperature vs. wind direction.
Probabilistic model
Now that we have an intuition for what kinds of problems HMMs address, let’s dive into the details. Let X={x1,…,xN} be N sequential observations where xn∈RD where D is a counting number. HMMs assume that each observation xn has a corresponding latent variable zn. We denote this set of latent variables as Z={z1,…,zN}. Note that each zn is a one-hot vector, not a scalar. This means zn is a K-vector—meaning the HMM has K states—with K−1 zeros and 1 one, indicating the assignment. We do this so that we can treat zn as a multinomial random variable, e.g.:
zn=⎣⎢⎢⎢⎢⎢⎢⎢⎢⎡0010⋮0⎦⎥⎥⎥⎥⎥⎥⎥⎥⎤,(2)
would indicate that the n-th latent state is 3 (using one-based indexing). Why do we use this representation? This lets us think of zn as a single draw from a multinomial distribution with parameters 1 and [p1,…,pK]⊤.
Markov assumption
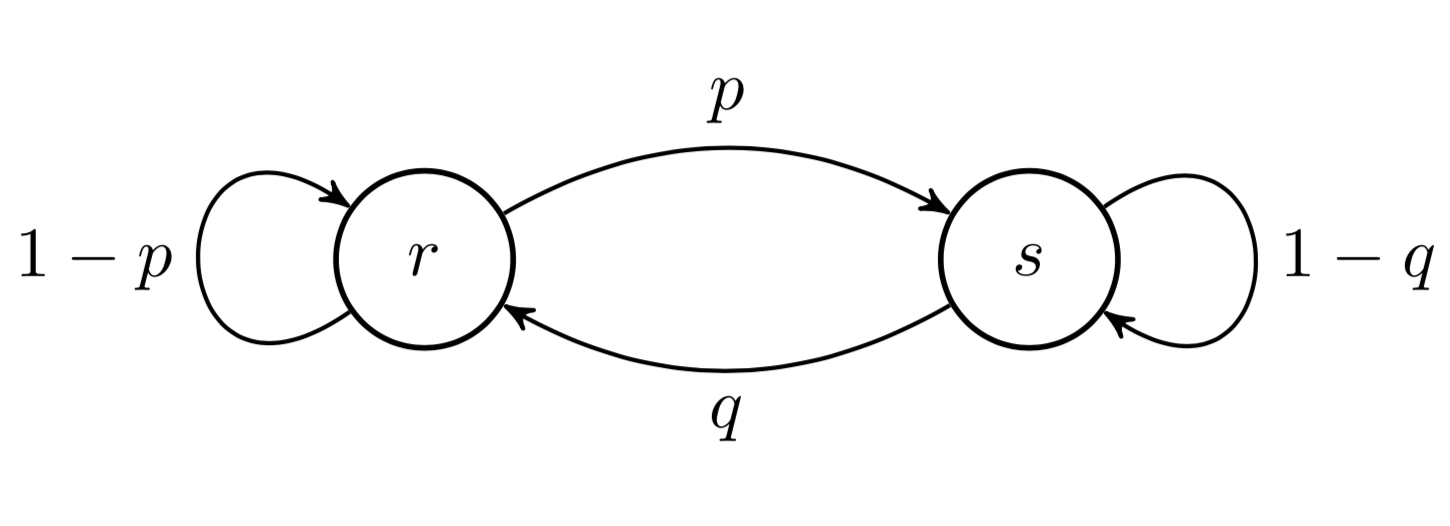
We assume the latent variables follow a random process, a K-state Markov chain. For example, consider a K=2 state Markov chain modeling the weather. The weather can either be sunny (zn=s) or rainy (zn=r) at time index n (day, hour, minute, etc.). The transition probabilities are given in Fig. 3.
Figure 3: State diagram for a Markov chain {zn} with states S={r,s}. The probability of moving from r to s is p and from s to r is q. The remaining probabilities can be computed because probabilities over all disjoint events must sum to one.
For an HMM, imagine that we only observe humidity as a percentage. Thus, at each time point n, xn is a scalar in the range [0,1], representings the day’s humidity, while the latent variable zn evolves according to the chain in Fig. 3. Thus, if we could infer Z, we could cluster our humidity data into K=2 states.
The random process Z is first-order Markovian. This Markov assumption is that the future only depends on the present. Formally, a random process z1,z2,… taking values in S is called a Markov chain if
p(zn+1∣zn,…,z1)=p(zn+1∣zn).(3)
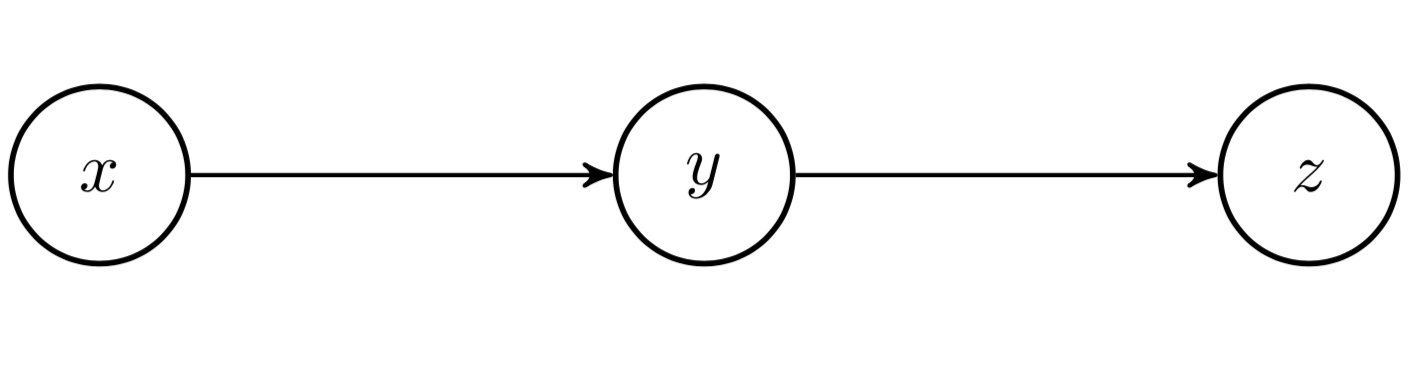
Thus, for a Markov chain such as in Fig. 4, we can say that X⊥⊥Z∣Y, which is read: “X is independent of Z given Y”. For example, height and vocabulary are not independent. In the absence of any other information, we might guess that someone who is six-feet tall has a bigger vocabulary than someone who is four-feet tall. However, height and vocabulary are conditionally independent given age. If we learn that the six-foot tall person is a fast-growing fourteen-year-old while the the four-foot tall person is thirty-five, we might switch our guess as to who has the bigger vocabulary. In Fig. 4, “vocabulary” is the Z node, height is the Y node, and age is the X node. We can see that if we don’t know Y, we can use X to infer Z; but if we do know Y, X is irrelevant.
Figure 4: Graphical model in which state Z is conditionally independent from X given Z.
An important implication of the Markovian assumption is that the joint probability of our HMM factorizes nicely,
Because of this factorization, the joint probability p(Z) can be completely represented via a transition probability matrix. Let Aij be the probability of transitioning from state i to state j. Then the transition probability matrix is A=[Aij]i,j∈S. Since there are K states, A is a K×K matrix. Furthermore, we assume the Markov process is stationary or time-homogeneous, meaning
p(zn=j∣zn=i)=Aij,∀n.(5)
In words, the transition probabilities are not changing as a function of n. This assumption can be changed to produce a time-inhomogeneous Markov chain, but we’ll focus on the time-homogeneous model.
Emission probabilities
In addition to the transition probabilities, an HMM has emission probabilities, which model how we assume our data are distributed given the state variable zn:
p(xn∣zn=k,ϕk),(6)
where ϕk are the parameters of some distribution which we posit. For example, we might model xn as a D-variate normal given zn or
xn∼ND(xn∣μk,Σk).(7)
Thus, zn indexes the parameter of the distribution, meaning it specifies which parameters to use in the set {ϕk}k=1K at time n. Clearly, these probabilities are of interest because if we infer zn, then the emission probabilities tell us something about our data. For example, in the Mount Rainier example, I fit a Gaussian HMM; the Gaussian mean vector μk for each of the three states tells us the mean value for the data vector xn.
Initialization
The last thing to note is how to initialize the state distribution of our Markov chain. Let π be a K-dimensional vector representing the probability of the Markov chain starting on each of the K states. Thus, the components of π sum to one, ∑k=1Kπk=1, and π is called the initial state distribution. Recall that a multinomial random variable with parameters (M,π1,…,πK) models the probability of rolling a K-sided die M times, where πk is the bias of the die landing on the kth side. With M=1 and π=[π1,…,πK]⊤, we can express our modeling assumption about z1 taking one of K values as a multinomial random variable,
z1∼Mult(1,π).(8)
HMMs can be either supervised or unsupervised. In the supervised setting, our observations have state labels X={(x1,z1),…,(xN,zN)}. In this context, we can use empirical Bayes to estimate π,
π^k=N∑n=1N1(zn=k)(9)
where 1(zn=k) is an indicator random variable. The goal of a supervised HMM is to estimate the initial state, the transition probability matrix A, and the emission probabilities p(xn∣zn,ϕ). This post will focus on the unsupervised setting. In this case, we need to estimate the model parameters θ={π,A,ϕ} (the initial state, the transition probability matrix, and the emission probabilities) and the state variables Z.
Filtering and smoothing
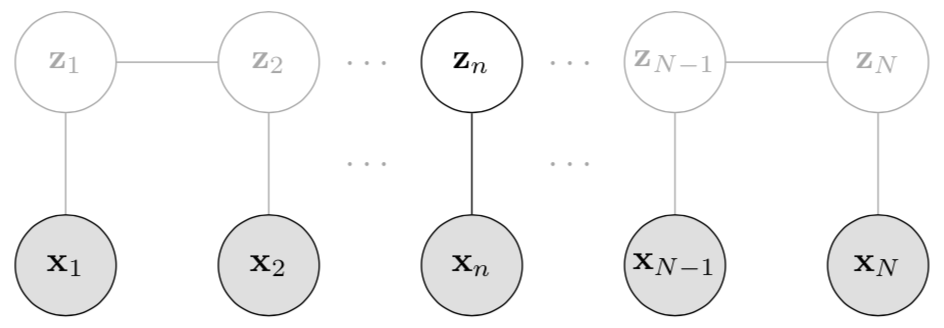
Before discussing inference, it is helpful to discuss two concepts in the HMM literature: filtering and smoothing. Filtering computes a belief state, or the probability of the latent variable zn being on a certain state in S, given the history of evidence so far (Fig. 5). Formally, filtering computes
p(zn∣X1:n),(10)
where the notation Xa:b denotes the set {xa,xa+1,…,xb−1,xb} for a≤b. Using our running example of weather, filtering answers the question: given weather measurements up until the current time, what state are we in now? Notice that the Markov property forces us to look at all of our observations. This is because of how the model factorizes. Since the dependencies between time points are encoded in the random process, we need to marginalize over all of the previous latent variables to condition on X1:n.
Figure 5: Filtering or posterior inference of zn given all the observations up until that time point, x1,…,xn.
As we’ll see, the forward–backward algorithm for HMMs performs filtering in a recursive forward pass over the data. At each time point, it computes it’s belief about the current zn and then uses that estimate in its estimate for zn+1.
In smoothing, we compute a belief state given observations up to and including future time, relative to zn (Fig. 6). Formally,
p(zn∣X).(11)
For example, smoothing answers the question: given all the weather measurement data available to us, what state were we in some time period ago? Once again, since the dependencies between time points are encoded in the random process, to condition on x1:N requires marginalizing over all the latent variables. Thus, we cannot look at fewer than all our observations.
Figure 6: Smoothing or posterior inference of zn given all the observations x1,…,xN.
Smoothing is performed during the backward pass of the forward–backward algorithm. You can think of it as “smoothing” because we’re using all the data we have seen so far to update our original, filtering-based estimate of each zn.
There are a number of other tasks we can perform with HMMs. Prediction computes p(xn+1∣x1:n). Viterbi decoding labels the most likely states for a new observed sequence x1:M. Posterior sampling allows us to randomly sample a latent state sequence z1:N given an observed sequence x1:N. In this post, we’ll focus on just filtering and smoothing, since these two steps are the core components of the forward–backward algorithm for HMM inference.
Baum–Welch algorithm
To perform maximum likelihood estimation on an HMM, we need to compute the likelihood p(X∣θ) for θ={π,A,ϕ}. We could compute this by marginalizing over the latent variables,
p(X∣θ)=Z∑p(X,Z∣θ).(12)
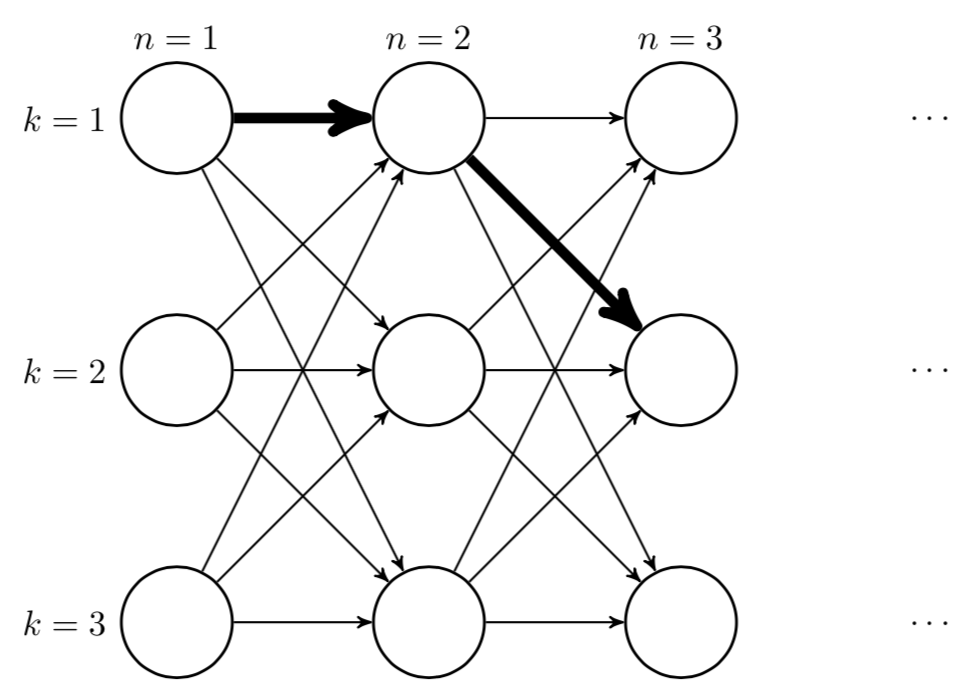
In words, we could marginalize out our uncertainty of the state variables by considering all possible values. However, there are KN terms in this equation. This is because for all N observations, there are K possible state values at time n. To see this, consider Fig. 7. Here we unroll an HMM with K=3 states, representing all possible state values over time. A single configuration of Z—a single term in the sum in Eq. 12—amounts to a single path along the lattice in Fig. 7. There are KN such paths. Since the number of terms in the likelihood scales exponentially in N, computing p(X∣θ) directly is intractable.
Figure 7: Unrolling a K=3 state HMM into a K×N lattice. The bolded path is a single set of assignments Z.
The standard solution to this kind of problem is expectation–maximization (EM). As we’ll see, the inference algorithm is a bit more complicated than “just EM”, and it has a name, the Baum–Welch algorithm (Baum et al., 1970). The M-step of the Baum–Welch algorithm is fairly straightforward, but the E-step is tricky and leverages the forward–backward algorithm.
EM works by iteratively optimizing the expected complete log likelihood rather than logp(X∣θ). It consists of two eponymous steps:
In the E-step, we construct a tight lower bound to the log likelihood. In the M-step, we optimize this lower bound. EM relies on the fact that it is often easier to optimize the complete log likelihoodp(X,Z∣θ) than it is to optimize the log likelihood p(X∣θ). We also want to estimate the parameters θ under the modeling assumption that Z exists, and therefore we need the M-step. In more detail, our two steps are:
E-step:M-step:Estimate E[Z(t+1)∣X,θ] given X, π(t),A(t) and ϕ(t).Estimate π(t+1),A(t+1) and ϕ(t+1) given E[Z(t+1)∣X,θ] and X.(14)
We use the expectations in Eq. 14 to compute the expected complete log likelihood. As we will see, we compute the E-step using the forward–backward algorithm; and we compute the M-step using maximum likelihood estimation and Lagrange multipliers.
E-step
First, let’s construct the complete log likelihood:
Now recall that we’re conditioning on our parameter estimates θ(t)={π(t),A(t),ϕ(t)}, and the only randomness is in the latent state variables Z, which is a collection of multinomial random variables. So let’s write each expectation as explicit sums over the state variables:
Here, znk is the k-th component of the vector zn. See A1 for a complete derivation of Eq. 17. This might seem like a turgid representation, but it has two benefits. First, we have isolated the random quantities; and second, we have written everything explicitly in terms of our parameters θ. Since the E-step amounts to estimating Z under the expected complete log likelihood, we just need to compute the terms inside expectations in Eq. 17 given our parameters θ and then use those expectations in the M-step. We don’t actually have to compute the value of the expected complete log likelihood.
Now note that each znk is a component of a multinomial random variable zn. So the expectation is just the probability that znk takes the value 1:
In the sum, K−1 terms are 0 because z is a one-hot vector.
The goal of the E-step is to efficiently compute these posterior moments (Eq. 18), and this is done using the forward–backward algorithm. Following Bishop, I will refer to the these posterior moments as gamma (γ) and xi (ξ) respectively:
The forward–backward algorithm estimates γ(znk) and ξ(zn−1,j,znk) for every n∈{1,…,N} and every k∈{1,…,K}. We’ll walk through the algorithm in detail in the next section, but now let’s look at the M-step.
M-step
In the M-step, we want to maximize the parameters, θ={π,A,ϕ}, given Z(t). The first two parameters can be optimized using Lagrange multipliers. Let’s walk through optimizing π in detail. The Lagrangian function for π is
where λπ is the Lagrange multiplier for π and where “…” represent the other terms in Eq. 17 that do not depend on π. The partial derivatives of this function with respect to both each πk and λπ is:
This is an intuitive result. The probability of being on the initial state k is the expected value of the k-th component of first latent variable, properly normalized. The logic for A is the same. The optimal Ajk is:
Finally, we need to solve for the optimal model parameters ϕk. These values depend on the functional form of the density p(xn∣ϕk). For a concrete example, let’s assume our emissions are Gaussian; therefore, ϕk={μk,Σk}. First, notice that our complete log likelihood in Eq. 15 only depends on ϕk through the rightmost term:
n=1∑Nk=1∑KE[znk]logp(xn∣ϕk).(26)
When taking the derivative of Eq. 15 w.r.t. to the parameters in ϕk, clearly this is the only term that will not necessarily go to zero. Furthermore, note that every term in the sum over K will go zero except for the kth parameters. Finally, this term has no constraints, and we can optimize the parameters via maximum likelihood estimation. In the Gaussian case, the optimal values are:
We’ve almost completed everything we need for EM inference for HMMs. If we can efficiently compute the expectations in Eq. 15 in our E-step—or γ and ξ in Eq. 19—, then all the updates in the M-step (Eq. 24, 25, and 27) immediately follow. As mentioned previously, this requires the forward–backward algorithm.
Forward–backward algorithm
The forward–backward algorithm computes p(zn∣X,θ(t)) and p(zn−1,zn∣X,θ(t)), which are required by the posterior moments (Eq. 19). More specifically, the algorithm computes these two terms,
In the steps labeled ⋆, we apply our modeling assumptions: that Z are Markov and that future observations only depend on the current latent variable. Look at the graphical model in Fig. 1 again if needed.
In the language of HMMs, the forward–backward algorithm does both filtering and smoothing. Computing α(zn) is effectively filtering, and computing the first posterior moment is smoothing:
I think it’s fair to think of computing the posterior second moment as a kind of smoothing as well. Now let’s look at the two passes.
Forward pass
The main idea of the forward pass is to marginalize over the previous latent variable to develop a recursive message-passing algorithm. This will allow us to use dynamic programming for efficient computation:
Terms cancel due to modeling assumptions. Again, look at the graphical model; if a node separates two other nodes as in Fig. 1, then it induces conditional independence.
Backward pass
The backward pass is a similar idea, but rather than marginalizing over the previous hidden state, we marginalize over the next hidden state:
Once again, this is a recursive algorithm in which we can message pass a previously computed quantity backward.
Initial conditions and evidence
Finally, we need to initialize our recursive algorithm. Since we compute the α(z) terms in a forward filtering pass, we need a value for α(z1). This is easy to compute:
In words, this is the probability of x1 for each state, weighted by the initial probability of that state.
However, what are the initial conditions for β(zN)? (Recall that the recursion starts at the last observation since we compute the β(z) terms in reverse.) Notice that if we set n=N and apply the definition of α(z) in Eq. 29, we have
p(zN∣X)=p(X)p(zN,X)β(zN).(35)
Thus, it’s clear that β(zN)=1 for each state k; otherwise, we would not have properly normalized distributions.
Finally, we can compute the evidence by summing over both sides of Eq. 29:
Now that we understand inference for HMMs, let’s look at a complete implementation of the Baum–Welch algorithm.
A practical limitation is that the forward–backward algorithm can be numerically unstable. This is because we are multiplying small probabilities many times in the forward–backward algorithm. This can quickly result in numerical underflow. In (Rabiner & Juang, 1986), the authors propose addressing this instability using scaling factors. However, I have opted for the use of logarithms following (Mann, 2006). This approach relies on the log-sum-exp trick to normalize log quantities.
This code was used to generate the results for Mount Rainier weather in Fig. 2. I annotate each step with equations from (Bishop, 2006).
importnumpyasnpfromscipy.specialimportlogsumexpfromscipy.statsimportmultivariate_normalasmvndefbaum_welch(obs,states,n_iters):"""EM for hidden Markov models, i.e. the Baum–Welch algorithm. Numerical
instability handled by working in log space.
"""N,D=obs.shapeK=len(states)# Initialize parameters \theta:
#
# 1. Probaiblities \pi (size K).
# 2. Transition probability matrix A.
# 3. Emission parameters \phi (Gaussian case: \mu and \Sigma).
#
log_pi=np.ones(K)/Kassertnp.isclose(log_pi.sum(),1)log_A=np.random.normal(0,1,size=(K,K))log_A-=logsumexp(log_A,axis=1,keepdims=True)assertnp.allclose(np.sum(np.exp(log_A),axis=1),1)means=np.random.normal(0,1,size=(K,D))covars=np.empty((K,D,D))forkinrange(K):# Ensure initial covariance matrices are PSD.
tmp=np.random.random((D,2*D))covars[k]=tmp@tmp.T# Initialize emission probabilities (size N × K).
log_emm_prob=np.random.random((N,K))# The n-th row is log(alpha(z_n)).
# The k-th column is value z_n takes.
# So (nk)-th cell is alpha(z_n = k).
log_alpha=np.zeros((N,K))log_beta=np.zeros((N,K))for_inrange(n_iters):# E-step (forward-backward algorithm).
# ------------------------------------
forkinrange(K):log_alpha[0,k]=log_pi[k]+log_emm_prob[0,k]forninrange(1,N):forkinrange(K):tmp=np.empty(K)forjinrange(K):tmp[j]=log_alpha[n-1,j]+log_A[j,k]log_alpha[n,k]=logsumexp(tmp)+log_emm_prob[n,k]log_beta[N-1]=0# log(1)
forninreversed(range(N-1)):forkinrange(K):tmp=np.empty(K)forjinrange(K):tmp[j]=(log_beta[n+1,j]+log_emm_prob[n+1,j]+log_A[k,j])log_beta[n,k]=logsumexp(tmp)# M-step.
# ------------------------------------
# Compute first posterior moment, \gamma (size N × K).
# Eq. 13.33 in Bishop.
log_gamma=log_alpha+log_betalog_evidence=logsumexp(log_alpha[N-1])gamma=np.exp(log_gamma-log_evidence)assertnp.allclose(np.sum(gamma,axis=1),1)# Compute second posterior moment, \xi (size N × K × K). For the n-th
# sample, the (K × K) matrix A is defined such that
# A_{ij} = E[z_{n} = i, z_{n+1} = j].
#
# Eq. 13.43 in Bishop.
log_xi=np.empty((N,K,K))forninrange(N-1):tmp=np.empty((K,K))forkinrange(K):forjinrange(K):tmp[k,j]=(log_alpha[n,k]+log_beta[n+1,j]+log_emm_prob[n+1,j]+log_A[k,j]-log_evidence)log_xi[n]=tmp# Eq. 13.18 in Bishop.
log_pi=log_gamma[0]-logsumexp(log_gamma[0])assertlog_pi.size==Kassertnp.isclose(np.sum(np.exp(log_pi)),1)# Eq. 13.19 in Bishop.
foriinrange(K):forjinrange(K):log_A[i,j]=logsumexp(log_xi[1:,i,j])-logsumexp(log_xi[1:,i,:])assertnp.allclose(np.sum(np.exp(log_A),axis=1),1)# Use matrix multiplication to sum over N.
# Eq. 13.20 in Bishop.
forkinrange(K):means[k]=obs.T@gamma[:,k]means[k]/=gamma[:,k].sum()# Compute new covariances.
# Eq. 13.21 in Bishop.
forkinrange(K):covars[k]=np.zeros((D,D))forninrange(N):dev=obs[n]-means[k]covars[k]+=gamma[n,k]*np.outer(dev,dev.T)covars[k]/=gamma[:,k].sum()# Recompute emission probabilities using inferred states.
forninrange(N):x=obs[n]forkinrange(K):mu=means[k]# var = covars[k] + 100 * np.eye(D)
M=np.random.random((N,D))var=M.T@Mlog_emm_prob[n,k]=mvn.logpdf(x,mu,var)Z=np.argmax(gamma,axis=1)theta=(np.exp(log_pi),np.exp(log_A),means,covars)returnZ,theta
Conclusion
While hidden Markov models are fairly complicated in terms of inference, they are conceptually simple and offer flexibility in the predictive distribution while remaining tractable. The Baum–Welch algorithm, which relies on the recursive forward–backward algorithm, is an efficient, model-specific version of EM for this sequential latent variable model.
Appendix
A1. Expected complete log likelihood
Recall that zn is a one-hot vector. Thus, it is a vector of zeros with a single one. Let znk denote the k-th component of the n-th state variable. Since x0=1 and x1=x for any value of x, we can index into a K-vector a using the following trick:
ai=k=1∏Kakznk.(A1.1)
In words, each component of a is raised to the zero-th power except for the i-th component, which is raised to the power one. This is useful because it represents the value ai in terms of the state variable. For example, we can write the transition probabilities as
p(zn∣zn−1)=j=1∏Kk=1∏KAjkzn−1,jznk.(A1.2)
We are indexing into the transition matrix A, and raising each cell value using the values associated with our one-hot vectors zn and zn−1. This means the expected log of this transition probability can be written as
Since Aij is the transition probability of moving from state i to state j, each row of A must sum to one, and so each row needs its own Lagrange multiplier. The Lagrange function for each row Aj is
Baum, L. E., Petrie, T., Soules, G., & Weiss, N. (1970). A maximization technique occurring in the statistical analysis of probabilistic functions of Markov chains. The Annals of Mathematical Statistics, 41(1), 164–171.
Rabiner, L., & Juang, B. (1986). An introduction to hidden Markov models. Ieee Assp Magazine, 3(1), 4–16.
Mann, T. P. (2006). Numerically stable hidden Markov model implementation. An HMM Scaling Tutorial, 1–8.
Bishop, C. M. (2006). Pattern Recognition and Machine Learning.