Wang and Fleet's 2008 paper, "Gaussian Process Dynamical Models for Human Motion", introduces a Gaussian process latent variable model with Gaussian process latent dynamics. I discuss this paper in detail.
Published
24 July 2020
A Gaussian process dynamical model (GPDM) (Wang et al., 2006) can be viewed as a Gaussian process latent variable model (GPLVM) with the latent variable evolving according to its own Gaussian process. Put more simply, imagine a latent variable evolves according to some smooth, nonlinear dynamics, and that the mapping from latent- to observation-space is also a smooth, nonlinear map. For example, imagine a mouse is moving in a maze, but we only record the firing rates of its hippocampal place cells. The latent variable is the mouse position, which we know is a relatively smooth trajectory in 3D space, and the observations, neuron firing rates, are a nonlinear function of this latent variable. Can we infer the position of the mouse given just its firing rates? This is the type of question the GPDM attempts to answer. The goal of this post is to work through this model in detail.
Gaussian process dynamics
Let Y=[y1…yT]⊤ be T observations, each J-dimensional, and indexed by discrete-time index t, and let X=[x1…xT]⊤ be D-dimensional latent variables. Now consider the following Markov dynamics:
xtyt=f(xt−1;A)+nx,t,=g(xt;B)+ny,t.(1)
In Eq. 1, f and g are mappings with parameters A and B respectively, and nx,t and ny,t are zero-mean Gaussian noise. The latent dynamics are Markov because the latent variable at time t, xt, only depends on the previous latent variable xt−1 and the dynamics defined by f. Each observation yt depends on its latent variable xt through the function g. For example, in a linear dynamical system, f and g are linear functions:
xtyt=Axt−1+nx,t,=Bxt+ny,t.(2)
In the original GPDM paper, the authors propose a particular nonlinear case in which f and g are linear combinations of basis functions:
where A and B are D×K and J×M matrices respectively and where ϕ(x)=[ϕ1(x)…ϕK(x)]⊤ and ψ(x)=[ψ1(x)…ψM(x)]⊤, so K- and M-vectors respectively.
It may not be obvious why this is a clever idea, but if we place Gaussian priors on the rows of A and B, we can integrate them out. In both cases, the derivations are the same, minus a few details, as the derivation for a GPLVM. We will be left with multivariate Gaussian distributions whose covariance matrices are Gram matrices where each cell value is a dot product between the basis functions, e.g.
Kij=ϕi(x)⊤ϕj(x).(5)
Thus, an appropriate choice of basis function implies Gaussian-process dynamics for this model. This is a common theme in Bayesian inference: placing a prior on weights induces a prior on functions.
Now let’s walk through this integration process in detail.
Integrating out the weights
First, let’s integrate out B. Wang’s modeling assumption is that each row of B, each bj, has a isotropic Gaussian prior, meaning
p(B)=j=1∏JNM(bj∣0,wj−2I),(6)
for some variance wj−2. Now let’s rewrite the model in terms in terms of the features (columns) of Y:
yj=Ψbj+ny,j,(7)
where Ψ=[ψ(x1)…ψ(xT)]⊤, or a T×M matrix. This implies that the distribution on yj, conditioned on bj, is a T-variate normal,
yj∣X,bj∼NT(yj∣Ψbj,wj−2σY2I).(8)
Note that the variance of ny,j is wj−2σY2. Wang never writes this out explicitly, but he doesn’t write out many terms explicitly, and this assumption makes the derivation work. Since both p(bj) and p(yj∣bj) are independently Gaussian, we can marginalize out bj to get:
p(yj∣X)=NT(yj∣0,Ψwj−2Ψ⊤+wj−2σY2I).(9)
See Sec. 2.3.3 in (Bishop, 2006) if this marginalization does not make sense. We can rewrite the covariance matrix in Eq. 9 as
Ψwj−2Ψ⊤+wj−2σY2I=wj2(ΨΨ⊤+σY2I)=wj2KY,(10)
where we’ve defined KY=ΨΨ⊤+σY2I. Therefore, the joint density over all J features is
where xd(2:T) denotes the d-th column of X after removing the first row of X, i.e. xd(2:T)=[xd(2)…xd(T)]⊤, and where Φ1:(T−1)=[ϕ(x1)…ϕ(xT−1)]⊤. To be clear, the superscripts denote components in a vector. σX2 is the variance of nx,d. This funky indexing is just the result of the Markov assumption, that xt depends on xt−1. Since this superscript notation is quite unwieldly, we’ll drop it in favor of just specifying matrix shapes as needed. Again, we can marginalize out A since both p(xd∣ad) and p(ad) are Gaussian:
p(xd)=NT−1(xd∣0,KXΦΦ⊤+σX2I).(14)
Again, see Sec. 2.3.3 in (Bishop, 2006) if this marginalization does not make sense. Thus, we can marginalize out A from the model entirely:
That’s it. We have derived the GPDM. As with the derivation for a GPLVM, it may not be immediately obvious where the Gaussian processes are, but notice that both p(Y∣X) and p(X) are both multivariate Gaussian with covariance matrices that are functions of Gram matrices, KY and KX. The other matrices in the last lines of Eq. 11 and 15 are the column-specific variances, W, or the result of the i.i.d. assumption for the observations and latent variables, Y and Xˉ. Thus, this model implies a Gaussian process prior on both the dynamics and latent-to-observation maps if we define KY and KX using positive definite kernel functions.
Inference
We want to infer the posterior p(X∣Y) where
p(X∣Y)∝p(Y∣X)p(X).(16)
Therefore, the log posterior in Eq. 16 decomposes into the sum of the logs of Eq. 11 and 15:
We can cancel constant terms. If we optimize the latent variable X with respect to this log posterior, Eq. 17, then we will infer a latent variable that adheres to our modeling assumptions in Eq. 3. However, Eq. 17 is slightly different from Wang’s Eq. 16. That’s because Wang also proposes optimizing the kernel functions’ hyperparameters with respect to the log posterior. Wang assumes a radial basis function (RBF) kernel and a linear-plus-RBF kernel for KY and KX respectively,
where δ is the Dirac delta function. The Dirac delta functions model the diagonal elements. Thus, β={β1,β2,β3} and α={α1,α2,α3,α4} where β3−1=σY2 and α4−1=σX2. Regardless of the kernel, meaning regardless of the set of hyperparameters β and α, we can place a prior on both kernels’ hyperparameters,
p(β)p(α)=i∏p(βi),=i∏p(αi),(19)
and then optimize the posterior
p(X,β,α∣Y)∝p(Y∣X,β)p(X∣α)p(β)p(α).(20)
This reduces to adding two additional terms to Eq. 17:
In conclusion, inference for a GPDM amounts to minimizing α, β, and X with respect to the negative log posterior, the negative of Eq. 20.
Example
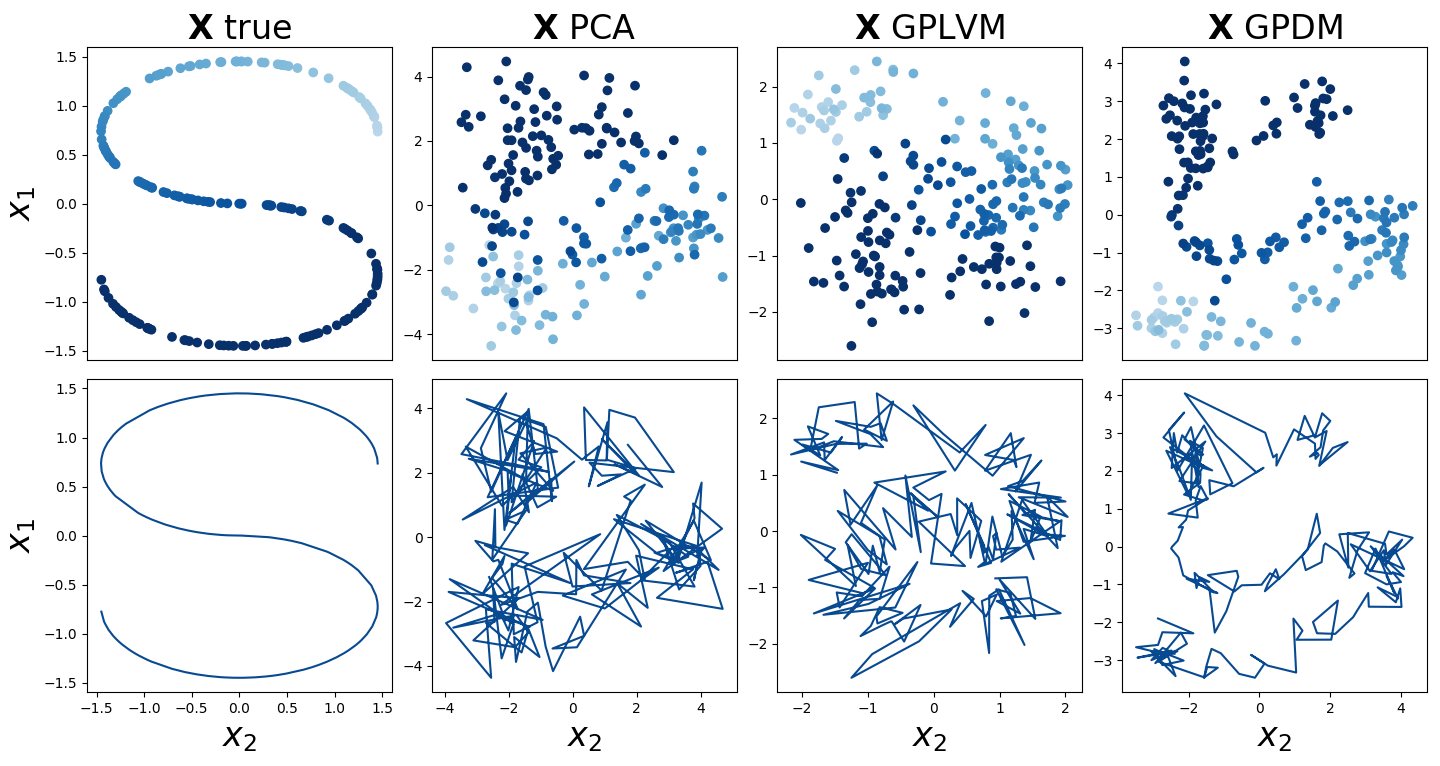
Consider the task of inferring a smooth S-shaped latent variable from high-dimensional observations (Figure 1, top left). See A1 for Python code to generate this S-shaped variable. Next, let’s fit three dimension reduction techniques to these data: principal component analysis (PCA), GPLVM, and GPDM (Figure 1, top right three subplots). We find that PCA can uncover the structure at a high-level, but has difficulty disambiguating points in the middle of the S-curve. This makes sense since PCA is a linear model. Both the GPLVM and GPDM do better at inferring the actual S-shape.
Figure 1. (Top row, left) True S-shaped latent variable generated from Scikit-learn's `make_s_curve` function. (Top row, right three plots) The inferred latent variable from three dimension reduction techniques: PCA, GPLVM, and GPDM. (Bottom row) Each subplot is the same as the one above it, but using a line plot rather than a scatter plot.
However, consider the bottom row of plots in Figure 1. Here, I’ve plotted the latent variables, each xn, in order using a line plot. This visualization makes it clear that GPDM infers a smoother latent space than the GPLVM. See A2 for Python code to fit a GPDM by optimizing the log posterior.