I disentangle the what I call the "lifting trick" from the kernel trick as a way of clarifying what the kernel trick is and does.
Published
10 December 2019
Implicit lifting
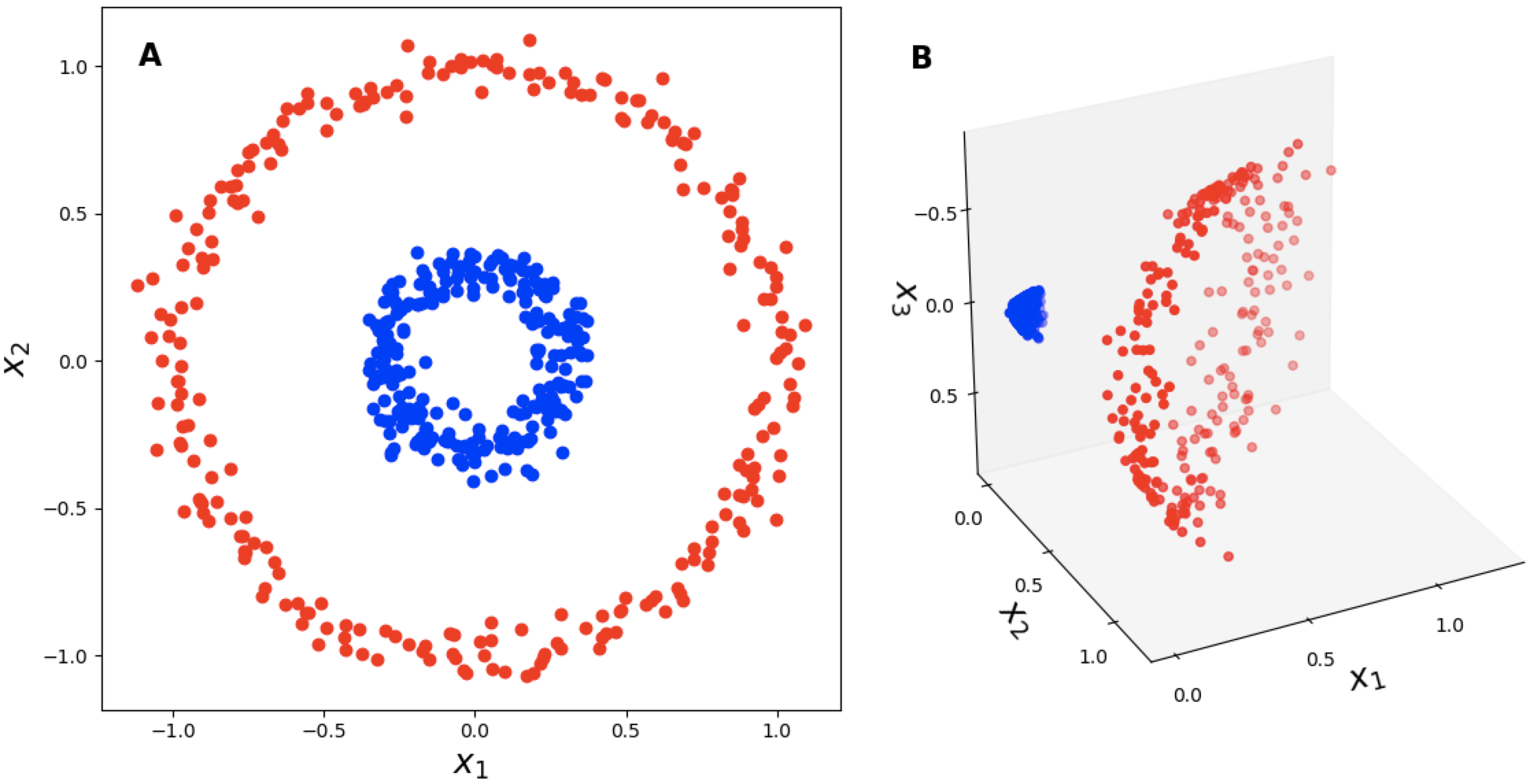
Imagine we have some data for a classification problem that is not linearly separable. A classic example is Figure 1a. We would like to use a linear classifier. How might we do this? One idea is to augment our data’s features so that we can “lift” it into a higher dimensional space in which our data are linearly separable (Figure 1b).
Figure 1: The "lifting trick". (a) A binary classification problem that is not linearly separable in R2. (b) A lifting of the data into R3 using a polynomial kernel, φ([x1x2])=[x12x222x1x2].
Let’s formalize this approach. Let our data be {(x1,y1),…,(xN,yN)} where xn∈RD in general. Now consider D=2 and a single data point
x=[x1x2].
We might transform each data point with a function (the polynomial kernel for the curious),
φ(x)=⎣⎢⎡x12x222x1x2⎦⎥⎤.
Since our new data, φ(x), is in R3, we might be able to find a hyperplane β in 3D to separate our observations,
β⊤φ(x)=β0+β1x12+β2x22+β32x1x2=0.
This idea, while cool, is not the kernel trick, but it deserves a name. Rather than calling it the pre-(kernel trick) trick, let’s just call it the lifting trick. Caveat: I am not aware of a name for this trick, but I find naming things useful. If you loudly call this “the lifting trick” at a machine-learning party, you might get confused looks.
In order to find this hyperplane, we need to run a classification algorithm on our data after it has been lifted into three-dimensional space. At this point, we could be done. We take RD, perform our lifting trick into RJ where D<J, and then use a method like logistic regression to try to linearly classify it. However, this might be expensive for a “fancy” enough φ(⋅). For N data points lifted into J dimensions, we need NJ operations just to preprocess the data. But we can avoid computing φ(⋅) entirely while still doing linear classification in this lifted space if we’re clever. This second trick is the kernel trick.
w is a normed vector representing the linear decision boundary and
α is a vector of Lagrange multipliers. If this is new or
confusing, please see these excellent lecture
notes
from Rob Schapire’s Princeton course on theoretical machine learning. Otherwise,
you can elide the details if you like; the upshot is that SVMs require computing
a dot product and that, as formulated, the SVM is linear. (Note that
w is implicit in the equation above; see those lecture notes as needed.)
Now what if we had the data problem in Figure 1a? Could we use the lifting trick to make our SVM nonlinear? Sure. For the previously specified φ(⋅), we have
We would then need to compute this for all our N data points. As we discussed, the problem with this approach is scalability. However, consider the following derivation,
What just happened? Rather than lifting our data into R3 and computing an inner product, we just computed an inner product in R2 and then squared the sum. While both derivations have a similar number of mathematical symbols, the actual number of operations is much smaller for the second approach. This is because a inner product in R2 is two multiplications and a sum. The square is just the square of a scalar, so 4 operations. The first approach squared three components of two vectors (6 operations), then performed an inner product (3 multiplications, 1 sum) for 9 operations.
This is the kernel trick: we can avoid expensive operations in high dimensions by finding an appropriate kernel functionk(xn,xm) that is equivalent to the inner product in higher dimensional space. In our example above, k(xn,xm)=(xn⊤xm)2. In other words, the kernel trick performs the lifting trick for cheap.
Mercer’s theorem
The mathematical basis for the kernel trick was discovered by James Mercer. Mercer proved that any positive definition functionk(xn,xm) with xn,xm∈RD defines an inner product of another vector space V. Thus, if you have a function φ(⋅) such that ⟨φ(xn),φ(xm)⟩V is a valid inner product in V, you know a kernel function exists that can perform the lifting trick for cheap. Alternatively, if you have a positive definite kernel, you can deconstruct its implicit basis functionφ(⋅).
is positive semidefinite for any collection {x1,…,xN}.
This theorem is if and only if, meaning we could explicitly construct a kernel function k(⋅,⋅) for a given φ(⋅) or we could take a kernel function and use it without having an explicit representation of φ(⋅).
If we assume everything is real-valued, then we can demonstrate this fact easily. Let K be the positive semidefinite Gram matrix above. Since it is real and symmetric, it has an eigendecomposition of the form
K=U⊤ΛU
where Λ=diag(λ1,…,λN). Since K is positive definite, then λn≥0 and the square root is real-valued. We can write an element of K as
Kij=[Λ1/2U:,i][Λ1/2U:,j].
Define φ(xi)=Λ1/2U:,i. Therefore, if our kernel function is positive semidefinite—if it defines a Gram matrix that is positive semidefinite—then there exists a function φ:X↦V such that
k(x,y)=φ(x)⊤φ(y)
where X is the space of samples.
Infinite-dimensional feature space
An interesting consequence of the kernel trick is that kernel methods, equipped with the appropriate kernel function, can be viewed as operating in infinite-dimensional feature space. As an example, consider the radial basis function (RBF) kernel,
kRBF(x,y)=exp(−γ∥x−y∥2).
Let’s take it for granted that this is a valid positive semidefinite kernel. Let kpoly(r) denote a polynomial kernel of degree r, and let γ=1/2. Then
So the RBF kernel can be viewed as an infinite sum over polynomial kernels. As r increases, each polynomial kernel lifts the data into higher dimensions, and the RBF kernel is an infinite sum over these kernels. (NB: kernel functions are linear operators.) Matthew Bernstein has a nice derivation more explicitly showing that φRBF:RD↦R∞, but I think the above logic captures the main point.
Why the distinction?
Why did I stress the distinction beween lifting and the kernel trick? Good research is about having a line of attack on a problem. A layperson might suggest good problems solve, but researchers find good solvable problems. This is the difference between saying, “We should cure cancer,” and the work done by an oncology researcher.
For similar reasons, I think it’s important to disentangle the lifting trick from the kernel trick. Without the mathematics of Mercer and others, we might have discovered the lifting trick but found it entirely useless in practice. With high probability, such currently useless solutions exist in the research wild today. It is mathematical relationship between kernel functions and lifting that is the eureka moment for the kernel trick.
Acknowledgements
I thank multiple readers for emailing me about various typos in this post.