Asymptotic Normality of Maximum Likelihood Estimators
Under certain regularity conditions, maximum likelihood estimators are "asymptotically efficient", meaning that they achieve the Cramér–Rao lower bound in the limit. I discuss this result.
Published
28 November 2019
Given a statistical model Pθ and a random variable X∼Pθ0 where θ0 are the true generative parameters, maximum likelihood estimation (MLE) finds a point estimate θ^N such that the resulting distribution “most likely” generated the data. MLE is popular for a number of theoretical reasons, one such reason being that MLE is asymtoptically efficient: in the limit, a maximum likelihood estimator achieves minimum possible variance or the Cramér–Rao lower bound. Recall that point estimators, as functions of X, are themselves random variables. Therefore, a low-variance estimator θ^N estimates the true parameter θ0 more precisely.
To state our claim more formally, let X=⟨X1,…,XN⟩ be a finite sample where X∼Pθ0 with θ0∈Θ being the true but unknown parameter. Let →p denote converges in probability and →d denote converges in distribution. Our claim of asymptotic normality is the following:
Asymptotic normality: Assume θ^N→pθ0 with θ0∈Θ and that other regularity conditions hold. Then
N(θ^N−θ0)→dN(0,I(θ0)−1)(1)
where I(θ0) is the Fisher information.
By “other regularity conditions”, I simply mean that I do not want to make a detailed accounting of every assumption for this post. Obviously, one should consult a standard textbook for a more rigorous treatment.
If asymptotic normality holds, then asymptotic efficiency falls out because it immediately implies
θ^N→dN(θ0,IN(θ0)−1).(2)
I use the notation IN(θ) for the Fisher information for X and I(θ) for the Fisher information for a single Xn∈X. Therefore, IN(θ)=NI(θ) provided the data are i.i.d. See my previous post on properties of the Fisher information for details.
The goal of this post is to discuss the asymptotic normality of maximum likelihood estimators. This post relies on understanding the Fisher information and the Cramér–Rao lower bound.
Proof of asymptotic normality
To prove asymptotic normality of MLEs, define the normalized log-likelihood function and its first and second derivatives with respect to θ as
By definition, the MLE is a maximum of the log likelihood function and therefore,
θ^N=argθ∈ΘmaxlogfX(x;θ)⟹LN′(θ^N)=0.(4)
Now let’s apply the mean value theorem,
Mean value theorem: Let f be a continuous function on the closed interval [a,b] and differentiable on the open interval. Then there exists a point c∈(a,b) such that
f′(c)=a−bf(a)−f(b)(5)
where f=LN′, a=θ^N and b=θ0. Then for some point c=θ~∈(θ^N,θ0), we have
LN′(θ^N)=LN′(θ0)+LN′′(θ~)(θ^N−θ0).(6)
Above, we have just rearranged terms. (Note that other proofs might apply the more general Taylor’s theorem and show that the higher-order terms are bounded in probability.) Now by definition LN′(θ^N)=0, and we can write
Let’s tackle the numerator and denominator separately. The upshot is that we can show the numerator converges in distribution to a normal distribution using the Central Limit Theorem, and that the denominator converges in probability to a constant value using the Weak Law of Large Numbers. Then we can invoke Slutsky’s theorem.
For the numerator, by the linearity of differentiation and the log of products we have
In the last line, we use the fact that the expected value of the score function (derivative of log likelihood) is zero. Without loss of generality, we take X1,
E[∂θ∂logfX(X1;θ0)]=0.(9)
See my previous post on properties of the Fisher information for a proof. Equation 8 allows us to invoke the Central Limit Theorem to say that
NLN′(θ0)→dN(0,V[∂θ∂logfX(X1;θ0)]).(10)
This variance is just the Fisher information for a single observation,
In the last step, we invoke the WLLN without loss of generality on X1. Now note that θ~∈(θ^N,θ0) by construction, and we assume that θ^N→pθ0. Taken together, we have
LN′′(θ~)→pE[∂θ2∂2logfX(X1;θ0)]=−I(θ0).(13)
If you’re unconvinced that the expected value of the derivative of the score is equal to the negative of the Fisher information, once again see my previous post on properties of the Fisher information for a proof.
To summarize, we have shown that
NLN′(θ0)→dN(0,I(θ0))(14)
and
LN′′(θ~)→p−I(θ0).(15)
We invoke Slutsky’s theorem, and we’re done:
N(θ^N−θ0)→dN(I(θ0)1).(16)
As discussed in the introduction, asymptotic normality immediately implies
θ^N→dN(θ0,IN(θ0)−1).(17)
As our finite sample size N increases, the MLE becomes more concentrated or its variance becomes smaller and smaller. In the limit, MLE achieves the lowest possible variance, the Cramér–Rao lower bound.
Example with Bernoulli distribution
Let’s look at a complete example. Let X1,…,XN be i.i.d. samples from a Bernoulli distribution with true parameter p. The log likelihood is
This works because Xn only has support {0,1}. If we compute the derivative of this log likelihood, set it equal to zero, and solve for p, we’ll have p^N, the MLE. First, let’s compute the derivative:
In other words, the MLE of the Bernoulli bias is just the average of the observations, which makes sense. The second derivative is the derivative of Equation 19 or
Thus, by the asymptotic normality of the MLE of the Bernoullli distribution—to be completely rigorous, we should show that the Bernoulli distribution meets the required regularity conditions—we know that
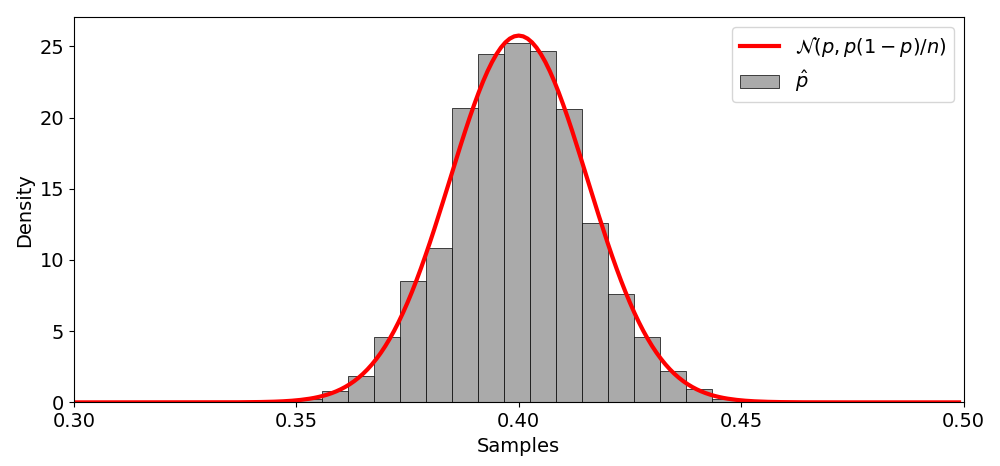
p^N→dN(p,Np(1−p)).(24)
We can empirically test this by drawing the probability density function of the above normal distribution, as well as a histogram of p^N for many iterations (Figure 1).
Figure 1. The probability density function of N(p,p(1−p)/N) (red), as well as a histogram of p^N (gray) over many experimental iterations. The true value of p is 0.4.
Here is the minimum code required to generate the above figure:
importnumpyasnpfromscipy.statsimportnormimportmatplotlib.pyplotasplt# Plot the asymptotically normal distribution.
N=1000p0=0.4xx=np.arange(0.3,0.5,0.001)yy=norm.pdf(xx,p0,np.sqrt((p0*(1-p0))/N))# Generate many random samples of size N and compute MLE.
mles=[]for_inrange(10000):X=np.random.binomial(1,p0,size=N)mles.append(X.mean())# Plot histogram of MLEs.
plt.plot(xx,yy)plt.hist(mles,bins=20,density=True)plt.show()
Acknowledgements
I relied on a few different excellent resources to write this post: