Ergodic Markov Chains
A Markov chain is ergodic if and only if it has at most one recurrent class and is aperiodic. A sketch of a proof of this theorem hinges on an intuitive probabilistic idea called "coupling" that is worth understanding.
An important theorem for Markov chains is the following:
Theorem 1: A Markov chain is ergodic if and only if it has at most one recurrent class and is aperiodic.
This is a very useful theorem. It means that in many cases, we can tell if a Markov chain is ergodic just by analyzing its state diagram. The goal of this post is not to provide a full proof of this theorem. Rather, I want to provide some intuition for why the theorem is true. In particular, the “only if” direction contains an intuitive probabilistic idea called coupling that is worth understanding.
The coupling method was invented by Wolfgang Doeblin (Doeblin, 1939). See A1 for a brief biography of his short but impactful life. Before explaining Doeblin’s idea of coupling, I review Markov chains to introduce notation. This section can be skimmed if one is already familiar with these ideas. Finally, I provide a sketch of a proof of Theorem .
Markov chains
A Markov chain is a powerful mathematical object. It is a stochastic model that represents a sequence of events in which each event depends only on the previous event. Formally,
Definition 1: Let be a finite set. A random process with values in is called a Markov chain if
We can think of as a random state at time , and the Markovian assumption is that the probability of transitioning from to only depends on . In words, the future depends only on the present. Let be the probability of transitioning from state to state . A Markov chain can be defined by a transition probability matrix:
Definition 2: The matrix is called the transition probability matrix.
Thus, is a matrix, where denotes the cardinality of , and the cell value is the probability of transitioning from state to state , and the rows of must sum to one. In this post, we will restrict ourselves to time homogeneous Markov chains:
Definition 3: A Markov chain is called time homogeneous if
In words, the transition probabilities are not changing as a function of time. Finally, let’s introduce some useful notation for the initial state of the Markov chain. Let
For example, I will write rather than . This is because all the conditional probabilities depend on the initial state, and it the usual notation is cumbersome.
Consider a simple Markov chain modeling the weather. We assume the weather has two states: rainy and sunny. Therefore , and is the “weather on day ”. The Markov chain model is as follows. If today is rainy (), tomorrow it is sunny () with probability . If today it is sunny, tomorrow it is rainy with probability . The transition matrix is then
and the state diagram of the Markov chain is Figure .
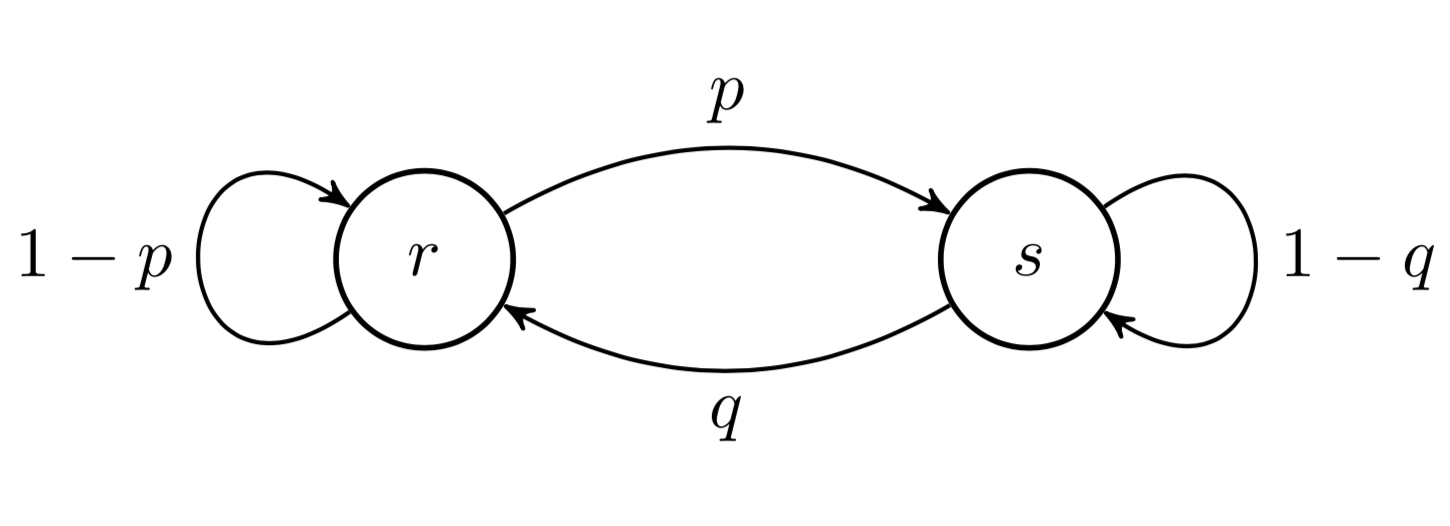
As a consequence of the Markovian assumptions, the probability of any path on a Markov chain is just the multiplication of the numbers along the path. For example, for some Markov chain with states , the probability of a particular path, say factorizes as
You can convince yourself of this easily by repeatedly applying the chain rule and the Markovian assumption (or see A2).
Furthermore, we have an easy formula to compute quantities such as
for . For example, let . Using marginalization and the Markovian assumption, we have
What is this? We are just performing a dot product between the th row and column of the transition matrix (Figure ) or
You can check that this idea generalizes so that,
Since we are repeatedly applying the transition matrix, is sometimes called the th iterate of .
In essence, the dot product performs marginalization, and everything works out nicely because of the Markovian assumption. If the -dimensional vector represents a discrete distribution over initial states , then is a -dimensional vector representing the probability distribution over . This is because a dot product of with a single column of performs marginalization over . If this is unclear, I’d recommend writing out the probabilities explicitly using a small matrix.
We are interested in ergodicity, which is a property of a random process in which its time average is the same as its probability space average. Formally,
Definition 4: A Markov chain is called ergodic if the limit
exists for every state and does not depend on the initial state . The -vector is called the stationary probability.
In other words, the probability of being on state after a long time is independent of the initial state . We can also write this as
Consider the following important implication. If a Markov chain is ergodic, then
Step holds because if the limit exists, the distinction between and does not matter. So we can write this as
where is a column vector. Hence the name “stationary probability” for . It is a distribution that does not change over time.
Since we are interested in ergodicity, let’s now introduce some properties related to reachability and long-term behavior.
Definition 5: We say that (path from to ) if there is a nonzero probability that starting at , we can reach at some point in the future.
Definition 6: A state is called transient if there exists a state such that but .
Definition 7: A state is called recurrent if for all states that , also .
Intuitively, a transient state is a state that once the chain arrives leaves, it cannot return to; while a recurrent state can be returned to. In other words, these two conditions are opposite. A transient state is not recurrent, and a recurrent state is not transient. Note that if a state is recurrent, every reachable state is also recurrent. We think of a set of recurrent states as a “class” or a “recurrent class”.
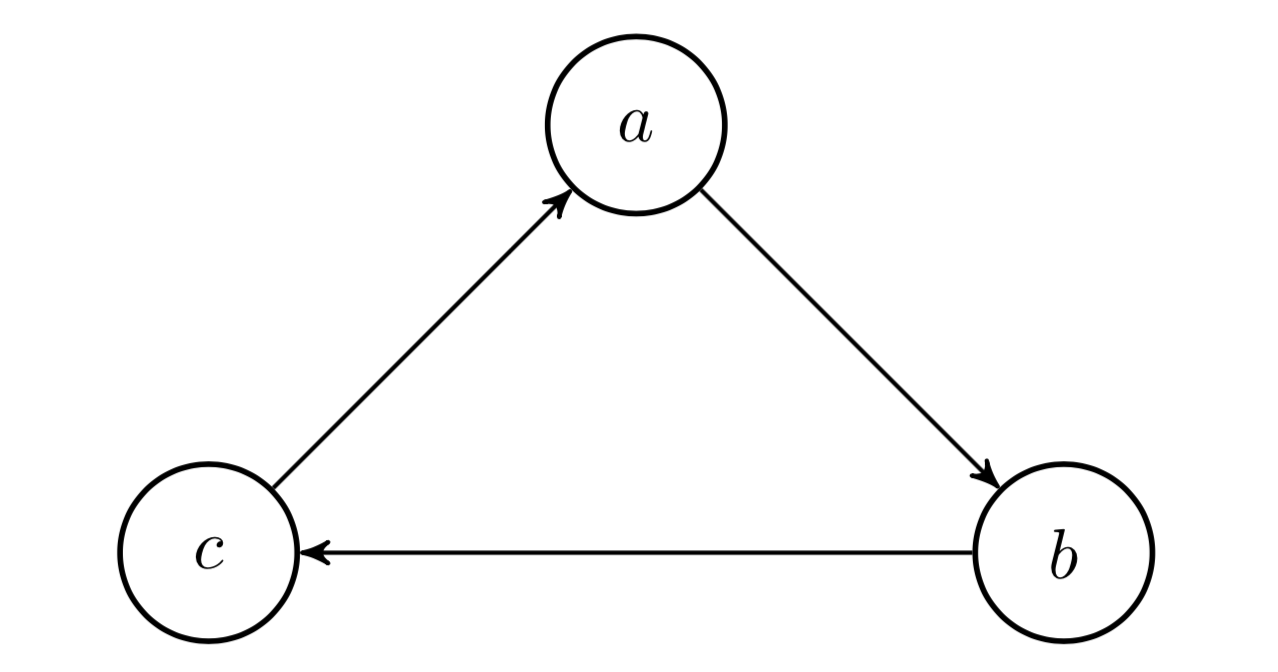
For example, consider Figure . In this Markov chain, states , , and are transient, while and form one recurrent class and , , and form another.
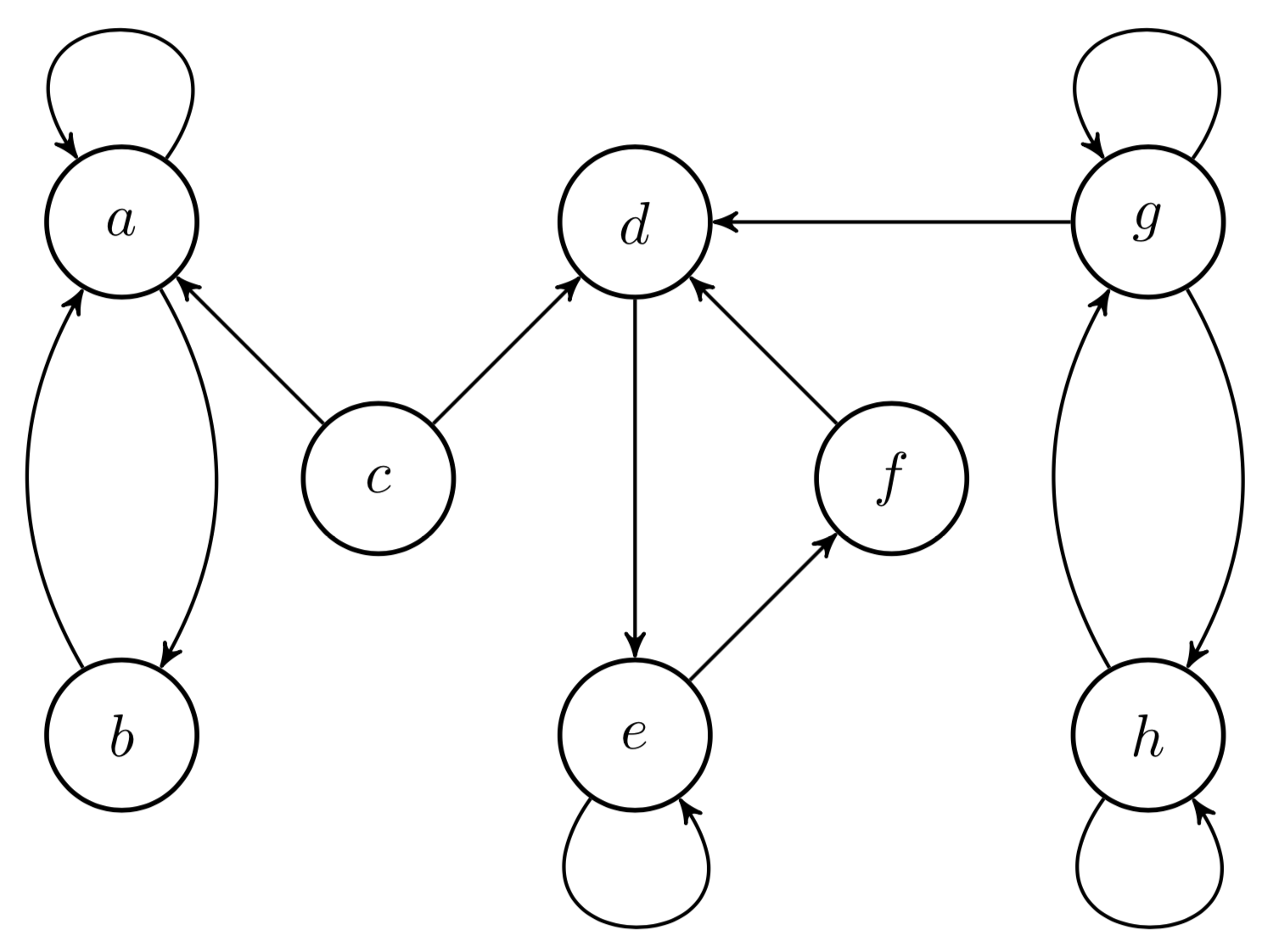
As I mentioned in the preamble, defining ergodicity in terms of recurrent states is useful because we can sometimes just look at a Markov chain and know whether it is ergodic, e.g. the Markov chain in Figure is ergodic, while the Markov chain in Figure is not. We now have a common framework and notation to tackle Theorem .
Proof sketch
We first show the “if” direction: if a Markov chain is either periodic or containing more than one recurrent class, it cannot be ergodic. We conclude with the “only if” direction, which contains the notion of coupling mentioned in the introduction.
“If” direction
Theorem implies that there are two blockers to ergodicity. First, if a Markov chain has more than one recurrent class, then it is not ergodic. Second, if a Markov chain is periodic, then it is not ergodic. Consider the Markov chain with two recurrent classes in Figure .
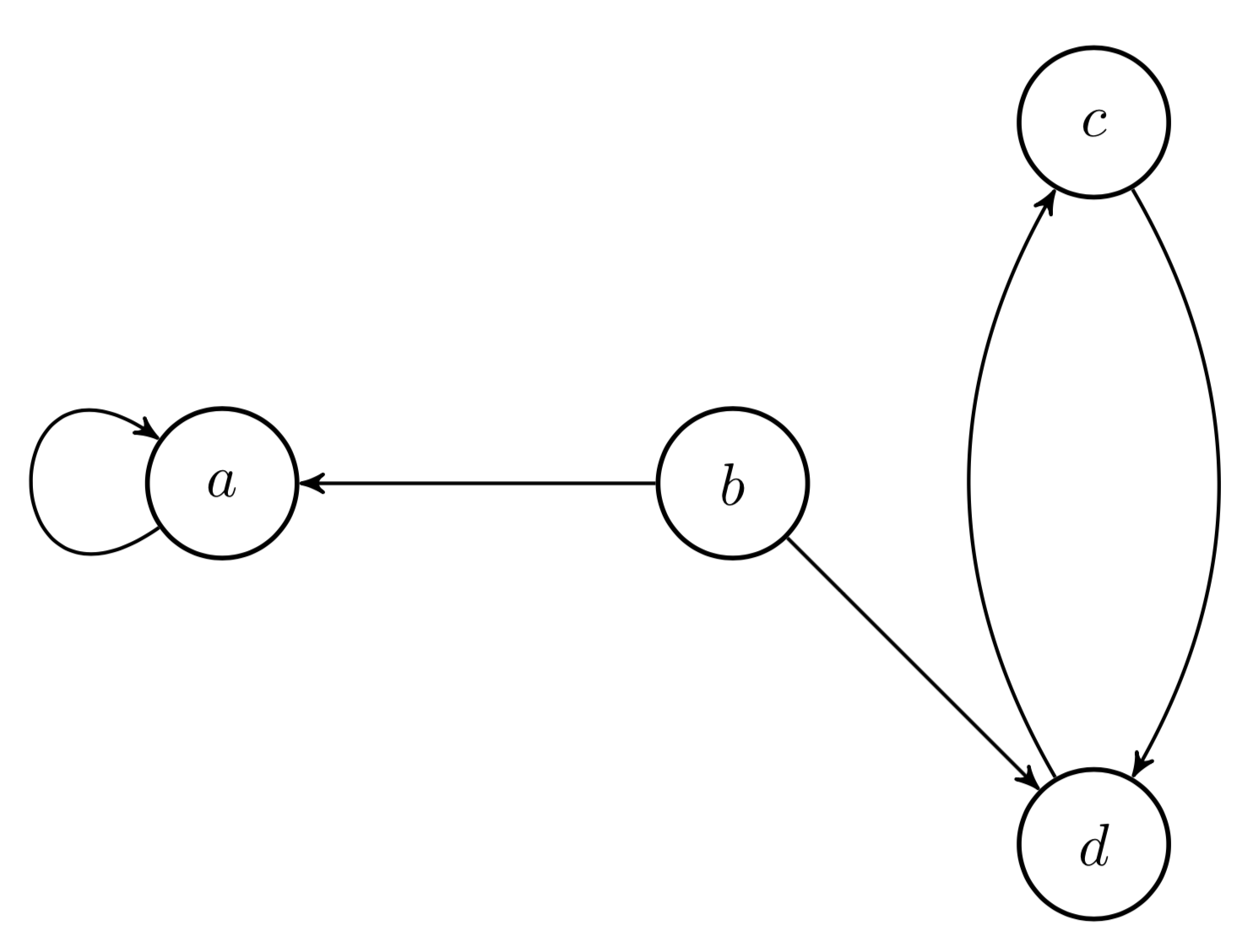
The important thing to note is that it has two recurrent classes. If we start on state , we’ll stay on forever. If we start in , we’ll stay in this recurrent class forever. If we start on , we’ll end up in one of the two recurrent classes. Therefore, the long-term probability of being on a particular state depends on the initial state. So multiple recurrent classes is an obvious obstruction to ergodicity.
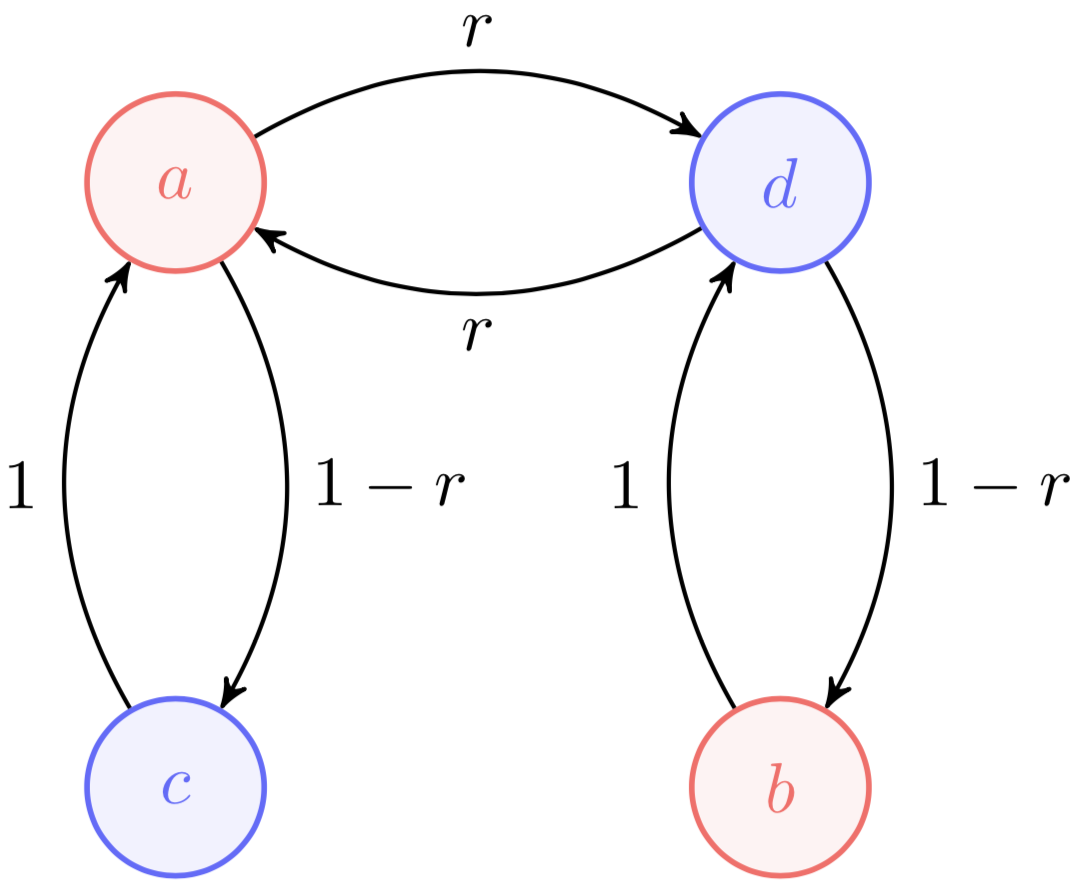
Next, consider the periodic Markov chain in Figure .
The probability of being on a state by time is completely dependent upon the initial state. It is easy to see this if we write out two sequences of probability paths side-by-side:
Thus, periodicity is another obstruction to ergodicity, and so both aperiodicity and at most one recurrent class are necessary conditions for ergodicity. If a Markov chain is ergodic, it cannot be periodic or have more than one recurrent class. Perhaps surprisingly, these conditions are also sufficient.
Note that a Markov chain can be periodic even if it is random, meaning even if we cannot predict which state it will go to next given its current state. This is because periodicity refers to the chain being “forced” to switch between sets of states in a predictable manner:
Definition 8: A Markov chain is periodic if its states can be partitioned into periodic classes such that .
For example, Figure is a -periodic Markov chain. While a random walk of the chain would be indeed random, we can predict if the chain will be in states or , conditional on the current set of states.
“Only if” direction
Let’s assume that we have an aperiodic Markov chain with one recurrent class. We need to show that the Markov chain “forgets” its initial state or
for all initial states and . To see this, we need Wolfgang Doeblin’s idea of coupling. Imagine an aperiodic Markov chain with a single recurrent class in which each state is a lily pad, and imagine that there are two frogs born on two separate lily pads (Figure ).
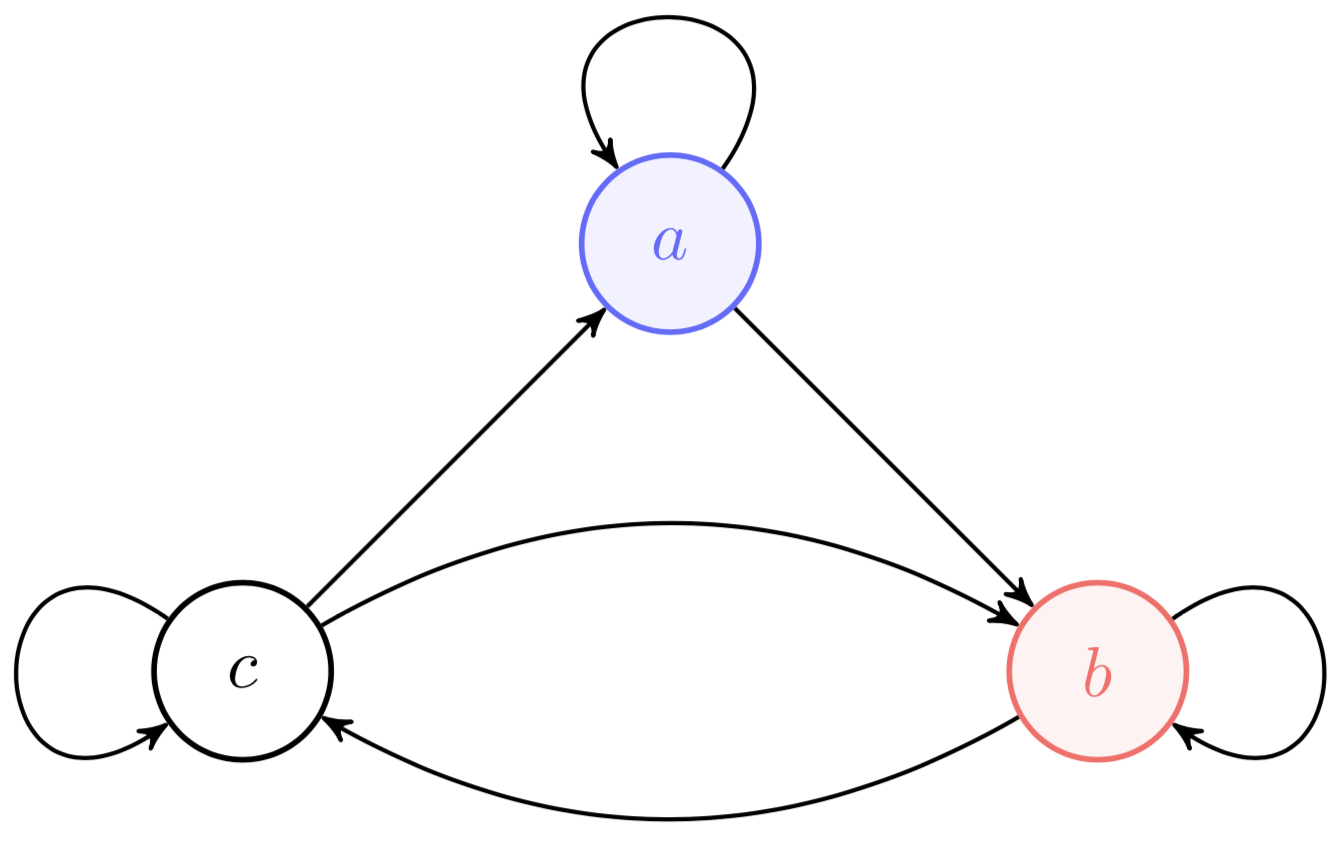
Initially, these two frogs hop around independently, moving according to the same transition matrix but with different initial conditions. However, the moment they first land on the same lily pad, they are coupled. That is, at each time, the next state is selected according to the transition probabilities of the Markov chain, and both frogs jump together to the next state. Thus, once they meet, they fall madly in love and go everywhere together. The time at which the frogs meet is the coupling time.
Let’s embrace heteronormativity for ease of notation, and say that one frog is a boy and the other is a girl. The trajectory of the boy frog is and the girl frog . For example, the movement of the frogs might look something like this,
where the coupling time is . On and after , the frogs are linked. Why are we doing this? This is a way of defining two different Markov chains, and , at two different starting conditions on the same meta-Markov chain . Imagine the boy frog starts on state and the girl frog state . Then note
Recall that . It follows that
Step holds because of Jensen’s inequality. Step holds because . If the two indicators on the left-hand side disagree, then the value is one. Otherwise, the value is zero.
This mathematical statement is intuitive: the difference in probability between the two Markov chains and is upper bounded by the probability that the two frogs have not yet met. We can drive this difference to zero by showing that as . In words, they will eventually meet. Intuitively, the reason periodicity hurts ergodicity is that it is like the two frogs simply never meet.
So we need to show that the two frogs eventually meet. Note that the pair is itself a Markov chain but in the state space . In order to show that the frogs eventually meet, it suffices to show that every state where is a transient state of the Markov chain . We know that once the two frogs are coupled, they are never uncoupled. That is,
for all and . Therefore, to show that is transient, we just need to show that . This is a mathematical formulation of the idea that the frogs eventually meet.
Let be any recurrent state in the original Markov chain. Since there is only one recurrent class, then we know that and . If were to fail, we would have a weird situation: even though both frogs can reach infinitely often, they will never be there at the same time. The only way this can happen is if the frogs are always out of sync, that is: if the chain is periodic.
Therefore, if the original Markov chain has only one recurrent class and is aperiodic, the two frogs must eventually meet in finite time. Thus, as , the Markov chain forgets its initial state and is therefore ergodic.
Acknowledgements
This blog post relies heavily on definitions, notation, and intuition (the story of two frogs) provided by Ramon von Handel in Princeton’s course “Probability and random processes”.
Appendix
A1. Wolfgang Doeblin
Wolfgang Doeblin was a born in Berlin in 1915 to Alfred and Erna Döblin. His father was a famous writer. They were Jewish-German; and Alfred and his family sans Wolfgang fled Berlin a few days after the Reichstag fire in February 1933. Wolfgang stayed behind until April to complete his gymnasium studies. The family was reunited and settled in Paris later that year; and Wolfgang continued his mathematical studies at the Sorbonne.
In the summer of 1936, Doeblin submitted his work on coupling (Doeblin, 1939) for publication. In March 1938, Doeblin defended his thesis—more or less (Doeblin, 1938)—and was drafted into the French army in November. After the start of World War II in September 1939, Doeblin was moved into active duty. In April 1940, Doeblin’s last mathematical note was filed with l’Academie des Sciences by Émile Borel. The note was submitted as a pli cacheté (sealed envelope), which was designed to remain sealed, granting its author intellectual priority if necessary without disclosing the work.
In 1940, Doeblin lost contact with his company while on a mission to the village Housseras. With Nazi troops a few minutes away, Doeblin burned his mathematical notes and took his own life. Doeblin’s pli cacheté was opened in 2000, revealing he had already proven a result (Itô’s lemma) for random processes.
A2. Path probabilities
- Doeblin, W. (1939). Sur les sommes d’un grand nombre de variables aléatoires indépendantes. Bull. Sci. Math, 63(2), 23–32.
- Doeblin, W. (1938). Sur les propriétés asymptotiques de mouvements régis par certains types de chaı̂nes simples... [PhD thesis]. Univ. de Paris.