Bayesian inference for models with binomial likelihoods is hard, but in a 2013 paper, Nicholas Polson and his coauthors introduced a new method fast Bayesian inference using Gibbs sampling. I discuss their main results in detail.
Published
20 September 2019
Consider the task of Bayesian inference for models with binomial likelihoods parameterized by log-odds. Two well-known examples of such models are logistic regression and negative binomial regression. For example, in logistic regression, the dependent variables are assumed to be i.i.d. from a Bernoulli distribution with parameter p, and therefore the likelihood function is
L(p)∝n=1∏Npyn(1−p)1−yn=p∑yn(1−p)N−∑yn.(1)
The observations interact with the response through a linear relationship with the log-odds,
log(1−pp)=β0+x1β1+x2β2+⋯+xDβD=β⊤x.(2)
If we solve for p in (2), we get
p=1+exp(β⊤xn)exp(β⊤xn)(3)
and a likelihood of
L(β)∝[1+exp(β⊤x)]N[exp(β⊤x)]∑yn.(4)
Due to this functional form, Bayesian inference for logistic regression is intractable (Bishop, 2006). This is because the evidence would require normalizing the product of a prior distribution (e.g. a Gaussian prior on β) times the likelihood function in (4). A similar problem arises for other models with binomial likelihoods parameterized by log-odds. See A1 for a derivation of the likelihood function for negative binomial regression.
However, (Polson et al., 2013) introduced a new method called Pólya-gamma augmentation that allows for constructing simple Gibbs samplers for these models. The goal of this post is to discuss their main results in detail, understand the derivations, and implement this Gibbs sampler.
Pólya-gamma random variables
If ω is a Pólya-gamma-distributed random variable with parameters b>0
and c∈R, denoted ω∼PG(b,c), then it is equal
in distribution to an infinite weighted sum of gamma random variables:
ω=d2π21k=1∑∞(k−1/2)2+c2/(4π2)gk.(5)
Here, =d denotes equality in distribution, and gk∼gamma(b,1) are independent gamma random variables. Note that this is not the density function. Instead, equality in distribution
means that the Pólya-gamma random variable on the left-hand side has the same cumulative
distribution function as the random variable on the right-hand side. The density
function itself is more complicated (see Polson et al’s first equation in section 2.3).
While a Pólya-gamma random variable’s density function is complicated, Polson et al show that all the finite moments of ω can be written in closed form. For example, the expectation can be calculated immediately,
E[ω]=2cbtanh(c/2).(6)
In particular, Polson et al proved two useful properties of Pólya-gamma variables. First,
(1+eψ)b(eψ)a=2−beκψ∫0∞e−ωψ2/2p(ω)dω(7)
where κ=a−b/2 and p(ω)=PG(ω∣b,0). And second,
p(ω∣ψ)∼PG(b,ψ).(8)
While the proof of (7) is a few lines in the paper, it is dense. See A2 for the proof with details. See A3 for a derivation of (8).
Logistic regression with PG augmentation
It may not be immediately obvious why the RHS of (7) is useful. Its utility is that we can construct Gibbs samplers of logistic models or models with likelihoods of the form in (9). To be concrete, consider Bayesian inference for logistic regression. Recall that the n-th observation’s contribution to the likelihood (4) is
Ln(β)=1+exp(β⊤xn)(exp(β⊤xn))yn.(9)
Using (7), we can express this likelihood contribution as
where z=⟨κ1/ω1,…,κN/ωN⟩ and Ω=diag(ω1,…,ωN). Step ‡ holds because the expectation in (10) is constant if we condition on ωn. Step ⋆ works by completing the square (see A4), while step † is just a little algebra (see A5).
In summary, if our prior on β is Gaussian (quadratic in β), then (11) is tractable because the posterior can be written as Gaussian (β). This suggests that we can construct a Gibbs sampler, where we repeatedly sample Ω given β and then β given Ω.
PG augmented Gibbs sampler
To perform Gibbs sampling with two parameters, we repeatedly fix one parameter while conditionally sampling from the other. Concretely for us, we first initialize β. Then we for t=1,…T, we sample
Ω(t+1)β(t+1)∼p(Ω∣β(t))∼p(β∣Ω(t+1)).(12)
Provided we can compute each density above, we’re done. The first density comes from (8). We know that
ωn∣β∼PG(1,β⊤xn).(13)
In other words, we sample each element along the diagonal of Ω using (13). The second equation is a bit trickier. If the prior on β is N(b,B), then p(β∣Ω,y) is
β∣Ω,y∼N(mω,Vω)(14)
where
Vωmω=(X⊤ΩX+B−1)−1=Vω(X⊤κ+B−1b)(15)
where κ=⟨κ1,…,κN⟩. The derivation just requires the matrix formula for completing the square and a bit of algebra (see A6). It is worth skimming this derivation to confirm that the reason it works is because β is Gaussian.
Thinking algorithmically, if we can sample ωn, we can use this reparameterization to get a conditionally Gaussian likelihood centered at X−1z with covariance X⊤ΩX.
Demo
Section 4 of Polson et al discusses simulating PG random variables. The details of this are beyond the scope of this post, and thankfully Scott Linderman has already created a Cython port of Jesse Windle’s code for sampling PG random variables. Using this library, we can easily construct a Gibbs sampler for logistic regression using PG augmentation:
importmatplotlib.pyplotaspltimportnumpyasnpfromnumpy.linalgimportinvimportnumpy.randomasnprfrompypolyagammaimportPyPolyaGammadefsigmoid(x):"""Numerically stable sigmoid function.
"""returnnp.where(x>=0,1/(1+np.exp(-x)),np.exp(x)/(1+np.exp(x)))defmulti_pgdraw(pg,B,C):"""Utility function for calling `pgdraw` on every pair in vectors B, C.
"""returnnp.array([pg.pgdraw(b,c)forb,cinzip(B,C)])defgen_bimodal_data(N,p):"""Generate bimodal data for easy sanity checking.
"""y=npr.random(N)<pX=np.empty(N)X[y]=npr.normal(0,1,size=y.sum())X[~y]=npr.normal(4,1.4,size=(~y).sum())returnX,y.astype(int)# Set priors and create data.
N_train=1000N_test=1000b=np.zeros(2)B=np.diag(np.ones(2))X_train,y_train=gen_bimodal_data(N_train,p=0.3)X_test,y_test=gen_bimodal_data(N_test,p=0.3)# Prepend 1 for the bias β_0.
X_train=np.vstack([np.ones(N_train),X_train])X_test=np.vstack([np.ones(N_test),X_test])# Peform Gibb sampling for T iterations.
pg=PyPolyaGamma()T=100Omega_diag=np.ones(N_train)beta_hat=npr.multivariate_normal(b,B)k=y_train-1/2.for_inrange(T):# ω ~ PG(1, x*β).
Omega_diag=multi_pgdraw(pg,np.ones(N_train),X_train.T@beta_hat)# β ~ N(m, V).
V=inv(X_train@np.diag(Omega_diag)@X_train.T+inv(B))m=np.dot(V,X_train@k+inv(B)@b)beta_hat=npr.multivariate_normal(m,V)y_pred=npr.binomial(1,sigmoid(X_test.T@beta_hat))bins=np.linspace(X_test.min()-3.,X_test.max()+3,100)plt.hist(X_test.T[y_pred==0][:,1],color='r',bins=bins)plt.hist(X_test.T[~(y_pred==0)][:,1],color='b',bins=bins)plt.show()
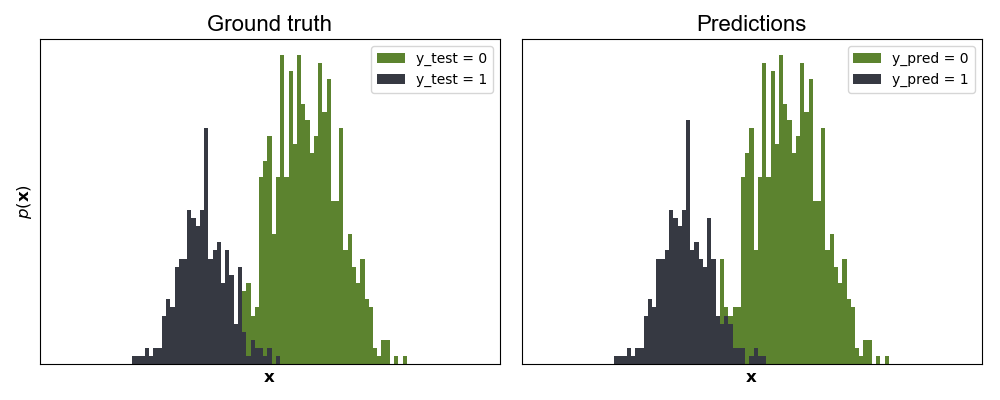
We can see in Figure 1 that the method works nicely. The only data points that are misclassified are where the two Gaussian distributions overlap.
Figure 1. (Left) Test data from a bimodal distribution colored based on ground truth binary labels. (Right) Test data colored based on predictions from a Bayesianb logistic regression model using PG-augmented Gibb sampling.
Acknowledgements
Thanks to Michael Minyi Zhang for helping
with a derivation and finding a bug in my code. Thanks to Yamada Kumpei and Nikos Gianniotis for
correcting typos and mistakes. Finally, I asked for a detailed derivation of Polson’s proof on
math.stackexchange.com, and Grada
Gukovic provided a
fantastic answer.
The expectation is with respect to ω∼PG(b,0). Just apply the definition of expectation to (23), and we’re done.
A3. Proof of secondary result
By the definitions of a PG random variable and expectation,
E[exp(−ω)ψ2/2]=∫0∞exp(−ωψ2/2)p(ω)dω.(24)
Plug this into Polson’s (5) with c=ψ.
A4. Completing the square
This derivation relies on the univariate case of completing the square. If we drop the subscripts and change vectors to scalars to ease notation, we have
Note that the sum of two quadratic forms in x can be written as a single quadratic form plus a constant term that is independent of x. Consider the equation
This is proportional to a Gaussian kernel with mean V−1m and covariance V−1. We can ignore the remainder terms m⊤V−1m and R since they does not depend on β.
This is the trick used in the paper. Using the notation in the paper, both Gaussians are quadratic in β; one has mean b and covariance B, and the other has mean X−1z and covariance X⊤Ω−1X. Doing a little pattern matching, we get
Step ⋆ holds because if we multiply each value in Ωs by the definition of z, we get back κ. Thus, we have shown that (β∣y,ω) is Gaussian with mean V−1m and covariance V−1.
Bishop, C. M. (2006). Pattern Recognition and Machine Learning.
Polson, N. G., Scott, J. G., & Windle, J. (2013). Bayesian inference for logistic models using Pólya–Gamma latent variables. Journal of the American Statistical Association, 108(504), 1339–1349.