Woodbury Matrix Identity for Factor Analysis
In factor analysis, the Woodbury matrix identity allows us to invert the covariance matrix of our data in time rather than time where and are the latent and data dimensions respectively. I explain and implement the technique.
Motivation
Given a -dimensional random vector , its generative model under factor analysis is
where is the loadings matrix and is the noise or uncertainty. The factors are assumed to be normal with unit variance, i.e. . The uncertainty is distributed where is a diagonal matrix. This means that the random variable is modeled by
One way to view this is that since is a matrix times a matrix, it is a low-rank approximation of the covariance of , while is a correction matrix that allows to be full rank.
If you write out the log-likelihood of this model, set its derivative equal to , and solve for the parameters and , you’ll eventually run into the fact that you need to invert , i.e. this shows up in the EM updates:
See my previous post on factor analysis for more details. This matrix is , meaning that matrix inversion is using Gauss–Jordan elimination. In Ghahramani and Hinton’s paper on a mixture of factor analyzers (Ghahramani & Hinton, 1996), they mention that can be “efficiently inverted using the matrix inversion lemma” or the Woodbury matrix identity. This post explores what that comment means.
Woodbury matrix identity
The Woodbury matrix identity states that the inverse of a rank- correction of some matrix—in factor analysis, the full rank matrix is rank-corrected by —can be computed by doing a rank- correction to the inverse of the original matrix.
If is a full rank matrix that is rank corrected by where , , and , then the Woodbury identity is:
Wikipedia has a direct proof of this that is easy to follow. In our case, we have , , , and , giving us:
The critical thing to note is that
meaning that inverting this matrix is where we assume that . Inverting is easy because it is diagonal; we just replace each element in the diagonal with its reciprocal, i.e.
In summary, the Woodbury matrix identity is perfect for fast matrix inversion in factor analysis. The inversion is rather than .
Implementation
I’m starting to appreciate that while numerical linear algebra is fun—it’s the perfect combination of math, programming, and efficiency—it’s hard to get right. The Woodbury identity is a good example of what I mean.
Consider this Python function to compute the Woodbury identity given a -vector that represents the diagonal elements of and matrices and :
import numpy as np
def woodbury(P, U, V):
k = P.shape[1]
# Fast inversion of diagonal Psi.
P_inv = np.diag(1./P)
# B is the k by k matrix to invert.
B_inv = np.linalg.inv(np.eye(k) + V @ P_inv @ U)
return P_inv - P_inv @ U @ B_inv @ V @ P_inv
Comparing this method to np.linalg.inv(), it is certainly faster, but it is not as fast as I would have expected (Figure ). What gives? In the experiments in Figure , the number of samples is , , and , which ranges along the -axis, gets as large as . Yet NumPy is competitive with our function.
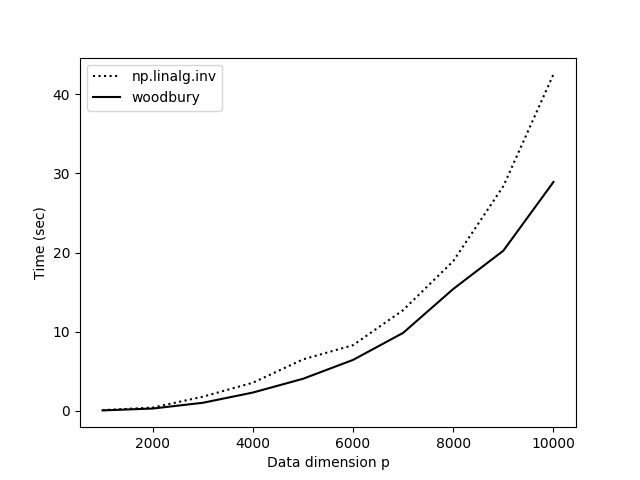
My hypothesis was that NumPy is competitive for large because woodbury() requires storing a lot of intermediate matrices and performs. To find a faster way to perform our matrix multiplications, I used einsum_path. The improved function is:
import numpy as np
def woodbury_einsum(P, U, V):
k = P.shape[1]
# Fast inversion of diagonal Psi.
P_inv = np.diag(1./np.diag(P))
tmp = np.einsum('ab,bc,cd->ad',
V, P_inv, U,
optimize=['einsum_path', (1, 2), (0, 1)])
B_inv = np.linalg.inv(np.eye(k) + tmp)
tmp = np.einsum('ab,bc,cd,de,ef->af',
P_inv, U, B_inv, V, P_inv,
optimize=['einsum_path', (0, 1), (0, 1), (0, 2), (0, 1)])
return P_inv - tmp
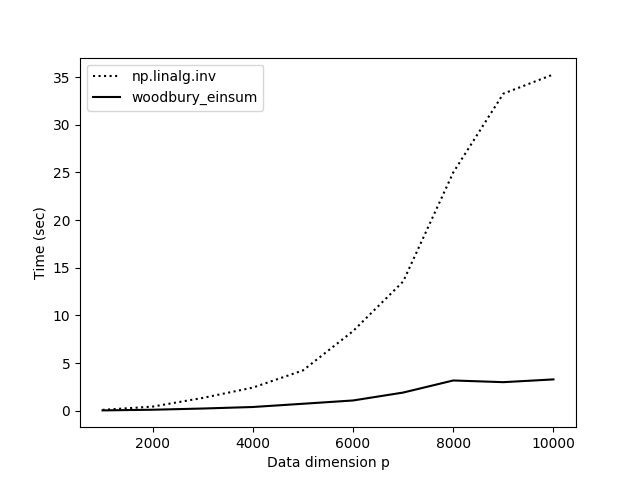
The results with woodbury_einsum() are much more satisfying (Figure ). Now our practical implementation starts to match our expectations based on theory.
But there’s an even faster way to tackle this problem. I asked how to make this function faster on StackOverflow, and someone observed that since we know P is a diagonal matrix, we can use NumPy’s broadcasting rather than explicitly performing matrix multiplications. This works because:
>>> import numpy as np
>>> A = np.array([2, 3])
>>> B = np.ones((2, 2))
>>> B * A
array([[2., 3.],
[2., 3.]])
>>> B @ np.diag(A)
array([[2., 3.],
[2., 3.]])
In words, when we write B * A where A is a vector, NumPy broadcasts, performing element-wise vector-vector multiplication with every row vector in B. This is mathematically equivalent to matrix multiplying B times A when A is a diagonal matrix. The code for this is (credit: Chris Swierczewski):
def woodbury_broadcasting(P, U, V):
k = P.shape[1]
P_inv_diag = 1./np.diag(P)
B_inv = np.linalg.inv(np.eye(k) + (V * P_inv_diag) @ U)
return np.diag(P_inv_diag) - (P_inv_diag.reshape(-1,1) * U @ B_inv @ V * P_inv_diag)
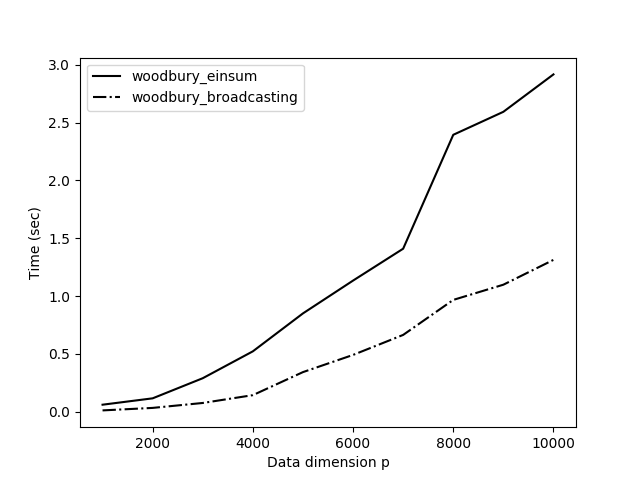
I compared this new method, woodbury_broadcasting(), to our method optimized with einsum() (Figure ) and the results are impressive. The new method using broadcasting is over twice as fast. This makes a lot of sense. Avoiding a couple of big matrix multiplications is obviously faster than optimizing those operations.
These kinds of problems and solutions are some of my favorite. We started with a hard problem, an algorithm that scaled cubically with the dimension of our data. But with a little math and a little programming, we were able to recover an exact solution that, for large dimensions, is several orders of magnitude faster.
Acknowledgements
I want to thank Ryan Adams for telling me to look into this identity when thinking about how to make factor analysis more scalable.
- Ghahramani, Z., & Hinton, G. E. (1996). The EM algorithm for mixtures of factor analyzers. Technical Report CRG-TR-96-1, University of Toronto.