Why Backprop Goes Backward
Backprogation is an algorithm that computes the gradient of a neural network, but it may not be obvious why the algorithm uses a backward pass. The answer allows us to reconstruct backprop from first principles.
The usual explanation of backpropagation (Rumelhart et al., 1986), the algorithm used to train neural networks, is that it is propagating errors for each node backwards. But when I first learned about the algorithm, I had a question that I could not find answered directly: why does it have to go backwards? A neural network is just a composite function, and we know how to compute the derivatives of composite functions using the chain rule. Why don’t we just compute the gradient in a forward pass? I found that answering this question strengthened my understanding of backprop.
I will assume the reader broadly understands neural networks and gradient descent and even has some familiarity with backprop. I’ll first setup backprop with some useful concepts and notation and then explain why a forward propagation algorithm is supoptimal.
Setup
Recall that the goal of backprop is to efficiently compute for every weight in a neural network . To frame the problem, let’s reason about an arbitrary weight and node somewhere in :
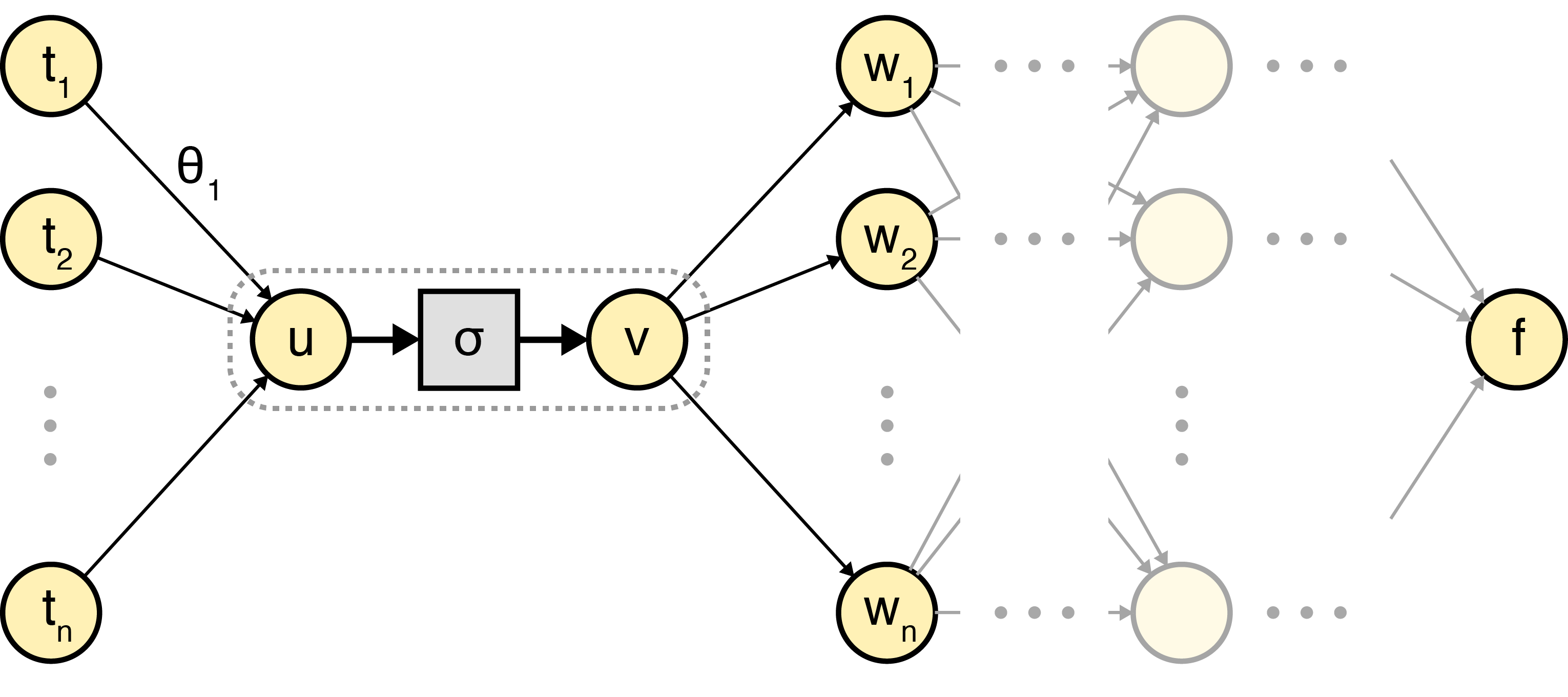
To be clear, the node refers to the output value of the node after passing the weighted sum of its inputs through an activation function , i.e.:
Note that in a typical diagram, , , and would all be a single node, denoted by the dashed line. In my mind, the most important observation needed to understand backprop is this: most of computing can be done locally at every node because of the chain rule:
We can compute analytically; it just depends on the definition of . And we know that . So at every node , if we knew , we could compute .
The challenge with computing is that downstream nodes depend on the value of . Thankfully, the multivariable chain rule has the answer. Given a multivariable function in which each is a single variable function , the multivariable chain rule says:
So we can compute for any weight , meaning we have the necessary machinery to attempt to implement backprop in a forward rather than backward pass. Let’s see what happens.
Repeated terms
We want a forward propagating algorithm that can compute the partial derivative for an arbitrary weight . We showed above that at node , this is equivalent to:
Note that I’ve dropped the intermediate variable for ease of notation. To design our forward propagating algorithm, let’s formalize an important fact: in a directed computational graph in which node depends upon node , it is impossible to compute at any point before node :
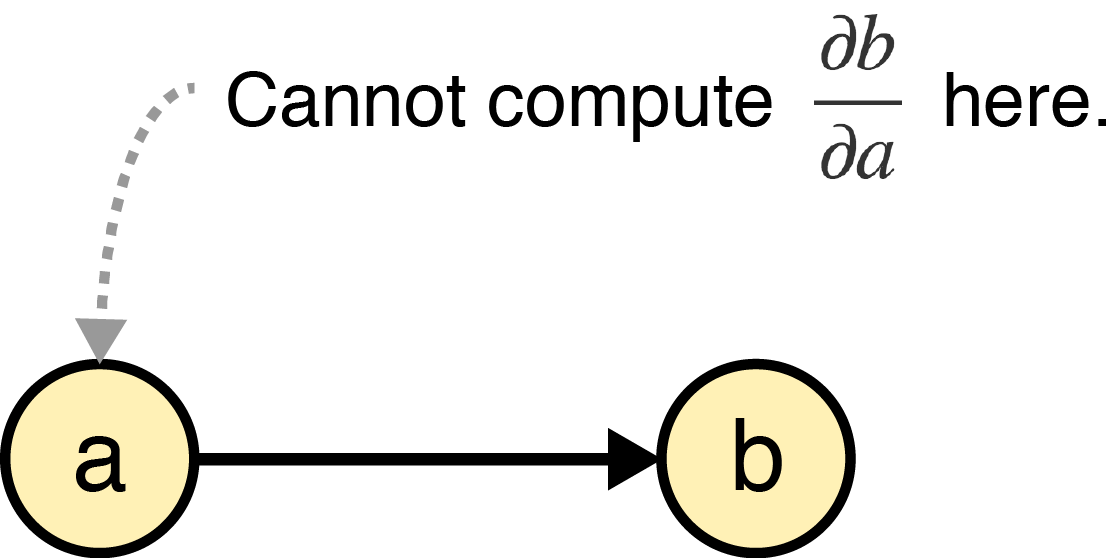
This claim should be obvious. If our computational graph represents a function , it is impossible to compute without access to and therefore .
In our setup, for every downstream node that depends on a node , it is impossible to compute at node . Therefore, in order to compute , we must decompose the term using the multivariable chain rule and pass the other terms needed to compute forward to each node that depends on :
We can see that such an algorithm blows up computationally because we’re forward propagating the same message many times over. For example, if we want to compute and where and are different weights in the same layer, we need to compute and separately, but all the other terms are repeated:
Here is a diagram of message passing the repeated terms:
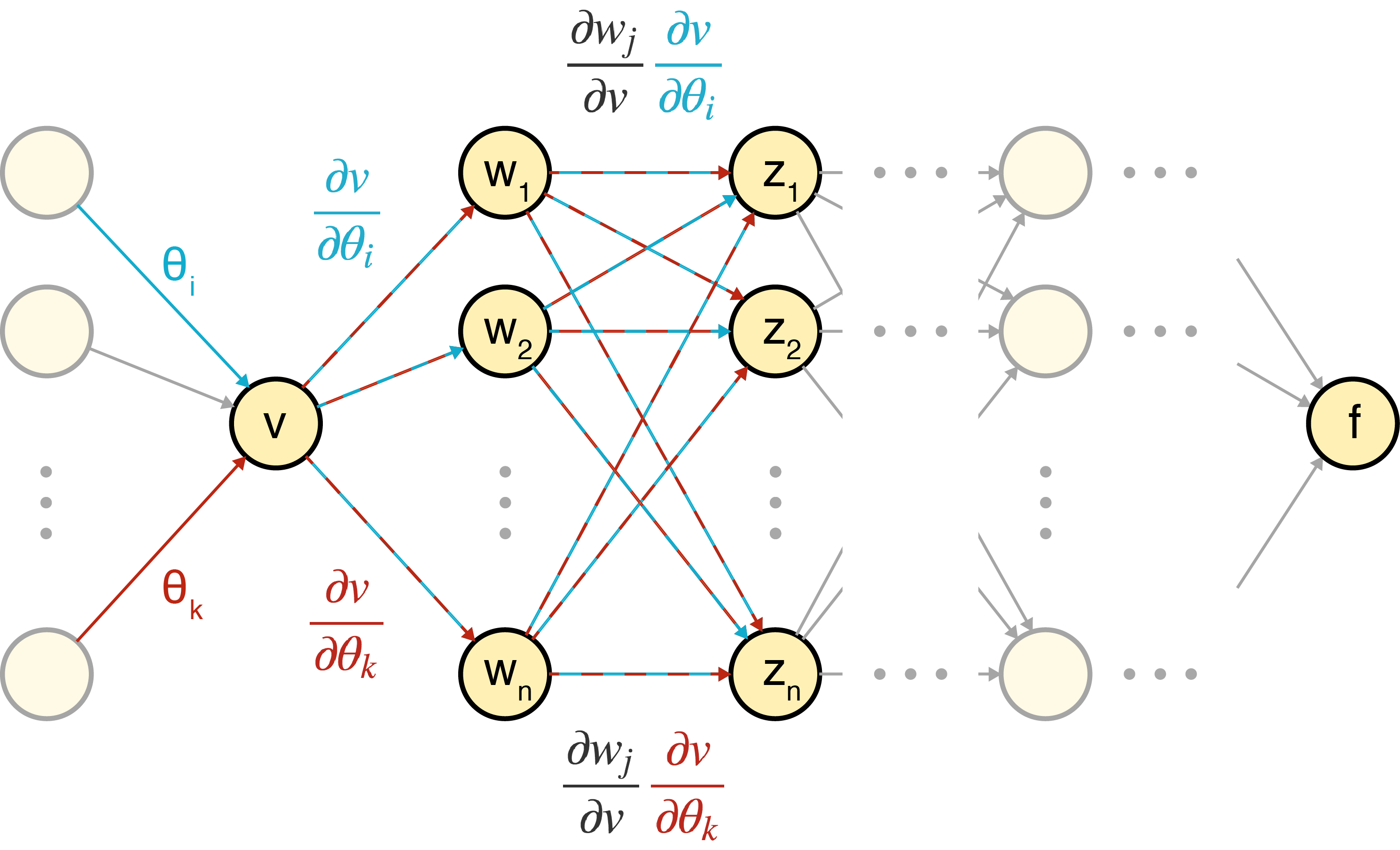
I think the above diagram is the lynchpin in understanding why backprop goes backwards. This is the key insight: if we already had access to downstream terms, for example , then we could message pass those terms backwards to node in order to compute . Since each node is just passing its own local term, the backward pass could be done in linear time with respect to the number of nodes.
A backward pass
I hope this explanation it clarifies how you might get to backprop from first principles trying to compute derivatives in a directed acyclic graph. On a given node that depends on a node , we simply message pass back to . The multivariable chain rule helps prove the correctness of backprop. For any node with downstream weights , if simply sums the backwardly propagating messages, it computes its desired derivative:
Once you understand the main computational problem backprop solves, I think the standard explanation of backpropagating errors makes much more sense. This process is can be viewed as a solution to a kind of credit assignment problem: each node tells its upstream neighbors what they did wrong. But the reason the algorithm works this way is because a naive, forward propagating solution would have quadratic runtime in the number of nodes.
- Rumelhart, D. E., Hinton, G. E., & Williams, R. J. (1986). Learning representations by back-propagating errors. Nature, 323(6088), 533.